通过上面爬取股票个股资金流的例子,大家应该已经能够学会自己编写爬取代码。现在巩固一下,做个相似的小练习题。要动手自己编写Python程序,爬取网上板块的资金流。爬取网址为http://data.eastmoney.com/bkzj/hy.html,显示界面如图1所示。
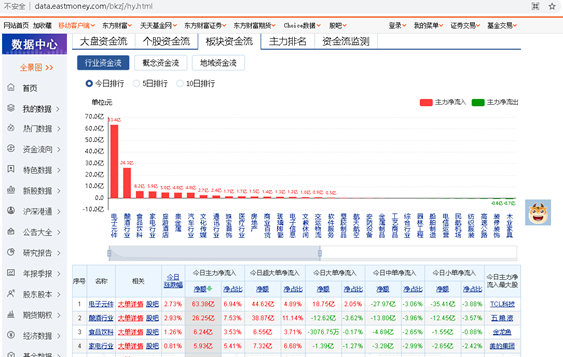
图1 板块资金流网址界面
1,查找JS
直接按F12键,打开开发调试工具并查找数据所对应的网页,如图2所示。
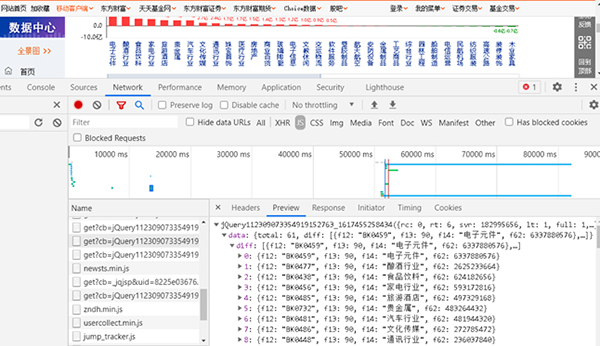
图2 查找JS所对应的网页
然后把网址输入浏览器中,网址比较长。
http://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112309073354919152763_1617455258434&pn=1&pz=500&po=1&np=1&fields=f12%2Cf13%2Cf14%2Cf62&fid=f62&fs=m%3A90%2Bt%3A2&ut=b2884a393a59ad64002292a3e90d46a5&_=1617455258435
此时,会得到网站的反馈,如图3所示。

图3 从网站获得板块及资金流
该网址对应的内容即是我们想要爬取的内容。
2,request请求及response响应状态
编写爬虫代码,详见如下代码:
# coding=utf-8
import requests
url=" http://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112309073354919152763_
1617455258436&fid=f62&po=1&pz=50&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3
e90d46a5&fs=m%3A90+t%3A2&fields=f12%2Cf14%2Cf2%2Cf3%2Cf62%2Cf184%2Cf66%2Cf69%2Cf72%2
Cf75%2Cf78%2Cf81%2Cf84%2Cf87%2Cf204%2Cf205%2Cf124"
r = requests.get(url)
r.status_code显示200,表示响应状态正常。r.text也有数据,说明爬取资金流数据是成功的,如图4所示。
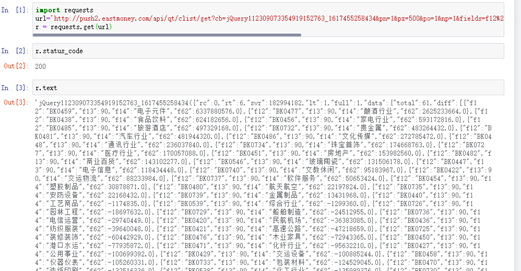
图4 response响应状态
3,清洗str变成JSON标准格式
(1)分析r.text数据。其内部是标准的JSON格式,只是前面多了一些前缀。将jQ前缀去掉,使用split()函数就能完成这个操作。详见如下代码:
r_text=r.text.split("{}".format("jQuery112309073354919152763_1617455258436"))[1]
r_text
运行结果如图5所示。

图5 去掉前缀的运行结果
(2)整理JSON数据。详见如下代码:
r_text_qu=r_text.rstrip(';')
r_text_json=json.loads(r_text_qu[1:-1])['data']['diff']
dfcf_code={"f12":"code","f2":"价格","f3":"涨幅","f14":"name","f62":"主净入√","f66":"超净入","f69":"超占比", "f72":"大净入","f75":"大占比","f78":"中净入","f81":"中占比","f84":"小净入","f87":"小占比","f124":"不知道","f184":"主占比√"}
result_=pd.DataFrame(r_text_json).rename(columns=dfcf_code)
result_["主净入√"]=round(result_["主净入√"]/100000000,2)#一亿,保留2位
result_=result_[result_["主净入√"]>0]
result_["超净入"]=round(result_["超净入"]/100000000,2)#一亿,保留2位
result_["大净入"]=round(result_["大净入"]/100000000,2)#一亿,保留2位
result_["中净入"]=round(result_["中净入"]/100000000,2)#一亿,保留2位
result_["小净入"]=round(result_["小净入"]/100000000,2)#一亿,保留2位
result_
运行结果如图6所示。
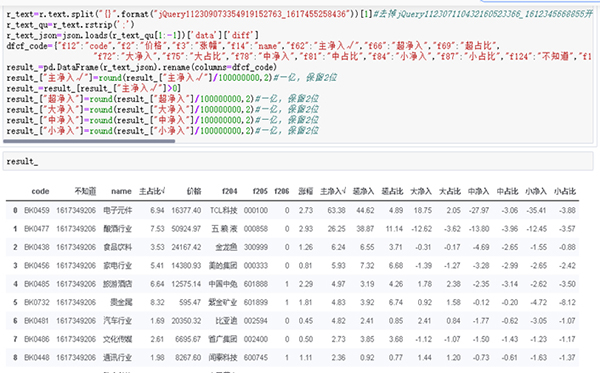
图6 整理后的运行结果
4,保存资金流数据
将清洗好的数据使用to_csv()函数保存到本地,如图7所示。
通过以上两种资金爬取的例子,想必大家已经了解了爬虫的一部分使用方法。其核心思路是:
(1)选取股票个股资金流的优势;
(2)获得网址并加以分析;
(3)使用爬虫进行数据获取并保存数据。

图6 数据保存
总结
JSON格式的数据是诸多网站使用的标准化数据格式之一,是一种轻量级的数据交换格式,十分易于阅读和编写,可以有效地提升网络传输效率。首先爬取到的是str格式的字符串,通过数据加工与处理,将其变成标准的JSON格式,继而变成Pandas格式。
通过案例分析与实战,我们要学会自己编写代码爬取金融数据并具备转化为JSON标准格式的能力。完成每日数据爬取工作与数据保存工作,为日后对数据进行历史测试与历史分析提供有效的数据支撑。
当然,有能力的读者可以将结果保存到MySQL、MongoDB等数据库中,甚至云端数据库Mongo Atlas中,这里作者不作重点讲解。我们将重点完全放在量化学习与策略的研究上面。使用txt格式保存数据,完全可以解决前期数据存储问题,数据也是完整有效的。