Taichi能够更精细地控制并行和每个元素(element)的操作,极大地提升了用户操作的灵活性。而Torch则将这些细节抽象成张量(Tensor)级别的操作,使得用户能聚焦于机器学习的模型结构。
作为机器学习、计算机图形学领域炙手可热的框架和编程语言,Torch 和 Taichi 能否各取所长,结合使用呢?答案是肯定的。在本篇文章中,作者将通过两个简单的例子演示:如何使用 Taichi Kernel 来实现 PyTorch 程序中特殊的数据预处理和自定义的算子,告别手写 CUDA,用轻巧便捷的方式提升机器学习模型算法的开发效率和灵活性。
案例 1:数据预处理
边缘填充(Padding)是机器学习中常用的预处理方法。如在对图像执行卷积操作时,用户需要对图像边缘进行填充,以保证图像输入输出前后的尺寸不变。一般来说,填充的方法有零填充或 torch.nn.functional.pad 提供的重复填充、循环填充等其他预设模式。但有时候我们想要在边缘上填充某个特殊的纹理或者模式,却并没有一个精心优化过的 PyTorch 算子能够适配这种场景。
解决方案有两个:使用 PyTorch 或者 Python 逐个操作矩阵元素;手写 C++ 或 CUDA 代码并接入PyTorch。前者的计算效率非常低,会拖累神经网络的训练速度;后者学习曲线陡峭,实操非常麻烦,开发流程冗长。
那么,有没有更好的方案呢?接下来我们将通过一个例子,带大家体验如何用 Taichi 做一个砖墙纹理的边缘填充。
用Taichi给PyTorch「添砖加瓦」!
第一步,我们在PyTorch中创建一个如下图所示的「砖块」。为了更好地观察填充的规律,我们给这块「砖」填充上了渐变的颜色:

填充的基本单元第二步,我们想要在x轴上错位重复这个「砖」,也就是如下所示的效果:

由于PyTorch中没有为这样的填充提供原生的算子,为了提高运算效率,需要将padding过程改写成一系列PyTorch的原生矩阵运算:
def torch_pad(arr, tile, y):
# image_pixel_to_coord
arr[:, :, 0] = image_height - 1 + ph - arr[:, :, 0]
arr[:, :, 1] -= pw
arr1 = torch.flip(arr, (2, ))
# map_coord
v = torch.floor(arr1[:, :, 1] / tile_height).to(torch.int)
u = torch.floor((arr1[:, :, 0] - v * shift_y[0]) / tile_width).to(torch.int)
uu = torch.stack((u, u), axis=2)
vv = torch.stack((v, v), axis=2)
arr2 = arr1 - uu * shift_x - vv * shift_y
# coord_to_tile_pixel
arr2[:, :, 1] = tile_height - 1 - arr2[:, :, 1]
table = torch.flip(arr2, (2, ))
table = table.view(-1, 2).to(torch.float)
inds = table.mv(y)
gathered = torch.index_select(tile.view(-1), 0, inds.to(torch.long))
return gathered
with Timer():
gathered = torch_pad(coords, tile, y)
torch.cuda.synchronize(device=device)
这一系列的矩阵操作并不是特别直观,而且需要在GPU内存中保存多个中间结果矩阵。一个较为明显的缺点是显存比较小的卡上可能就跑不起来了。而如果使用Taichi,我们可以非常直接地描述这个运算:
@ti.kernel
def ti_pad(image_pixels: ti.types.ndarray(), tile: ti.types.ndarray()):
for row, col in ti.ndrange(image_height, image_width):
# image_pixel_to_coord
x1, y1 = ti.math.ivec2(col - pw, image_height - 1 - row + ph)
# map_coord
v: ti.i32 = ti.floor(y1 / tile_height)
u: ti.i32 = ti.floor((x1 - v * shift_y[0]) / tile_width)
x2, y2 = ti.math.ivec2(x1 - u * shift_x[0] - v * shift_y[0],
y1 - u * shift_x[1] - v * shift_y[1])
# coord_to_tile_pixel
x, y = ti.math.ivec2(tile_height - 1 - y2, x2)
image_pixels[row, col] = tile[x, y]
with Timer():
ti_pad(image_pixels, tile)
ti.sync()
这段代码逻辑非常简单:遍历输出图片的每个像素,计算当前像素对应到输入的「砖块」图片中的位置,最后复制该位置的颜色到这个像素。虽然看起来是在逐个写入每个像素,但Taichi会将kernel的顶层for-loop编译成高度并行的GPU代码。同时,上一段代码中我们直接把两个PyTorch的Tensor传给了 Taichi 函数ti_pad ,Taichi会直接使用PyTorch分配好的内存,不会因为两个框架间的数据交互而产生额外开销。
最后,实际的运算性能是:在RTX3090 GPU上运行时,PyTorch (v1.12.1)耗费了30.392 ms[1],而Taichi版本的Kernel耗时仅0.267 ms[2],Taichi相对PyTorch的加速比超过了100倍。

*加速比会因实现细节和运行硬件略有不同
事实上,上述的 PyTorch 底层实现需要启动 58 个 CUDA Kernel,而本例中 Taichi 将全部运算编译成了 1 个 CUDA Kernel。更少的 Kernel 减少了 GPU 函数启动的开销,且相比 PyTorch 实现,Taichi 节省了大量冗余的内存操作。在 GPU 上内存操作远比运算操作开销更「昂贵」,这也是非常夸张的加速比的来源。Taichi 的设计遵循了 「Megakernel」的设计准则:使用单个大的 Kernel 去完成尽可能多的运算逻辑,这与机器学习系统设计中常见的 「算子融合优化」是一样的道理。
在数据预处理问题上,一方面 Taichi 拥有更精细的操作颗粒度,能灵活适配研究人员不同的需求,另一方面 Taichi 能达到更高的计算性能,显著提升预处理部分的运行速度。当然,预处理仅仅是机器学习训练和推理过程中的一小步,对于机器学习领域的研究人员来说,有大量时间花费在模型前向和反向的计算算子中。那么对于定制高性能 ML 算子,Taichi 有什么好办法?
案例 2:定制高性能 ML 算子
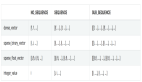
和预处理遇到的问题一样,很多时候研究员用到的算子非常新或者干脆是自己发明的,在 PyTorch 中找不到良好的支持。考虑到机器学习训练和推理计算量大、成本高昂,很多研究员不得不去学习 CUDA 并尽力调优,以提升计算效率。但 CUDA 代码编写难度大,调试困难,会拖慢模型迭代速度。有一篇知乎文章[3]讲述了一个精彩的例子:作者开发了 RWKV 语言模型,使用了一个类似一维的深度卷积(depthwise convolution)的自定义算子。这个算子本身计算量不大,但是因为 PyTorch 中没有原生支持,跑得特别慢。为了解决计算性能的问题,作者编写 CUDA 代码并且采用循环合并、Shared Memory 等多种技巧来优化,最终性能达到了 PyTorch 实现的 20 倍性能。参考这篇文章和发布的 CUDA 代码,我们也使用相同的优化手段实现了对应的 Taichi 版本。那么 Taichi 在这个例子中性能如何呢?请看下图:

RTX3080 上的 RWKV 运算时间,单位是毫秒,越低越好。Baseline 代表代码直接实现算法,不做任何优化。v1-v3 代表不同的优化版本。CUDA 实现代码见[4], Taichi 实现代码见[5]。
我们可以看到,在使用同样的优化技术的前提下, Taichi 版本达到了非常接近 CUDA 的性能,甚至某些情况下还略快一点。这样的性能水平是如何用 Taichi 实现的呢?会有多么简单呢?接下来我们就以 Baseline 版本为例,体验如何用 Taichi 轻松实现深度卷积算子!算子本身的运算过程很简单:遍历两个输入 Tensor w 和 k, 把它们对应位置的元素乘起来,通过一个累加循环计算出 s 并存进输出 Tensor out。
Python 实现(很慢很好懂)
def run_formula_very_slow(w, k, B, C, T, eps):
out = torch.empty((B, C, T), device='cpu')
for b in range(B):
for c in range(C):
for t in range(T):
s = eps
for u in range(t-T+1, t+1):
s += w[c][0][(T-1)-(t-u)] * k[b][c][u+T-1]
out[b][c][t] = s
return out
这段代码非常直观好懂,但它运行速度如此之慢,以至于测试出来的数据都没办法把它放进上面那张图里...🚗 PyTorch 实现(一般慢不好懂)
out = eps + F.conv1d(nn.ZeroPad2d((T-1, 0, 0, 0))(k), w.unsqueeze(1), groups=C)
从上面的 Python 代码写出 PyTorch 的这一行还是非常有难度的,要对 PyTorch 的这几个算子底层的运算逻辑很熟悉才能写得出来。
Taichi 实现(很快很好懂)
@ti.kernel
def taichi_forward_v0(
out: ti.types.ndarray(field_dim=3),
w: ti.types.ndarray(field_dim=3),
k: ti.types.ndarray(field_dim=3),
eps: ti.f32):
for b, c, t in out:
s = eps
for u in range(t-T+1, t+1):
s += w[c, 0, (T-1)-(t-u)] * k[b, c, u+T-1]
out[b, c, t] = s
Taichi 代码和 Python 代码几乎完全一致,而且不用考虑并行、指针偏移计算等等各种编程细节,就可以达到和 CUDA 接近的性能,在开发效率上具有很大的优势。作为对比,我们也把对应的 CUDA 版本放在后面,有兴趣的读者可以看一下。CUDA 版本的可读性差了很多。它的外层循环是隐含在线程并行的逻辑里。另外,它的指针的偏移计算比较复杂,每个元素在矩阵中的位置没办法很直观地看出来,需要做一些推演才能完全理解这段代码,当算法再复杂一些的时候就很容易写错。
__global__ void kernel_forward(const float* w, const float* k, float* x,
const float eps, const int B, const int C, const int T)
{
const int i = blockIdx.y;
const int t = threadIdx.x;
float s = eps;
const float* www = w + (i % C) * T + (T - 1) - t;
const float* kk = k + i * T;
for (int u = 0; u <= t; u++){
s += www[u] * kk[u];
}
x[i * T + t] = s;
}
更重要的是,CUDA 代码需要编译环境才能运行。如果提前编译成动态库,又需要对齐 CUDA 运行时环境。环境配置、Python 接口封装等等都需要耗费精力去做。而 Taichi 代码本身就是一小段 Python 代码,可以通过 pip 安装管理,与 PyTorch 完全一致,简单了很多,其良好的可复现性,也便于机器学习开发者开源、分享代码。
更好的性能、更敏捷的开发效率、更便捷的分享方式,共同构成了使用 Taichi 开发自定义 ML 算子的显著优势。
总结
虽然 PyTorch 可以高效完成机器学习中大部分的运算任务,但仍有许多算子没有实现或者运算效率无法满足需求。作为嵌在 Python 中的高性能编程语言,Taichi 易于编写、内存消耗小,计算性能接近手写 CUDA。本文展示的两个例子,正是结合 Taichi 和 PyTorch 之所长,解决了预处理算子和新算法中的算子的高性能编程问题,同时 Taichi 和 Pytorch Tensor 零开销交互的特性也省去了编写「脚手架」代码的时间,极大地提升了开发效率。希望 Taichi 可以将机器学习研究人员从繁复晦涩的高性能代码编写、验证、调优中解放出来,专注于算法本身,创造出更多有趣的东西 。