在这篇文章中,我将详细解释这篇论文《Why do tree-based models still outperform deep learning on tabular data》这篇论文解释了一个被世界各地的机器学习从业者在各种领域观察到的现象——基于树的模型在分析表格数据方面比深度学习/神经网络好得多。
论文的注意事项
这篇论文进行了大量的预处理。例如像删除丢失的数据会阻碍树的性能,但是随机森林非常适合缺少数据的情况,如果你的数据非常杂乱:包含大量的特征和维度。RF的鲁棒性和优点使其优于更“先进”的解决方案,因为后者很容易出现问题。

其余的大部分工作都很标准。我个人不太喜欢应用太多的预处理技术,因为这可能会导致失去数据集的许多细微差别,但论文中所采取的步骤基本上会产生相同的数据集。但是需要说明的是,在评估最终结果时要使用相同的处理方法。
论文还使用随机搜索来进行超参数调优。这也是行业标准,但根据我的经验,贝叶斯搜索更适合在更广泛的搜索空间中进行搜索。
了解了这些就可以深入我们的主要问题了——为什么基于树的方法胜过深度学习?
1、神经网络偏向过于平滑的解决方案
这是作者分享深度学习神经网络无法与随机森林竞争的第一个原因。 简而言之,当涉及到非平滑函数/决策边界时,神经网络很难创建最适合的函数。 随机森林在怪异/锯齿/不规则模式下做得更好。

如果我来猜测原因的话,可能是在神经网络中使用了梯度,而梯度依赖于可微的搜索空间,根据定义这些空间是平滑的,所以无法区分尖锐点和一些随机函数。 所以我推荐学习诸如进化算法、传统搜索等更基本的概念等 AI 概念,因为这些概念可以在 NN 失败时的各种情况下取得很好的结果。
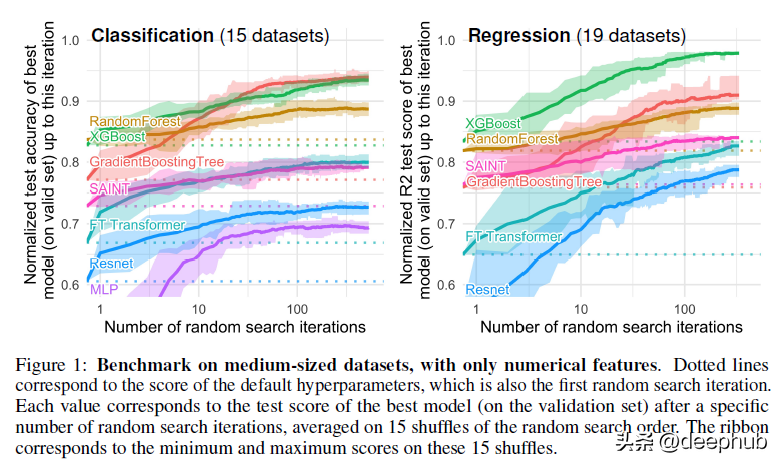
有关基于树的方法(RandomForests)和深度学习者之间决策边界差异的更具体示例,请查看下图 -
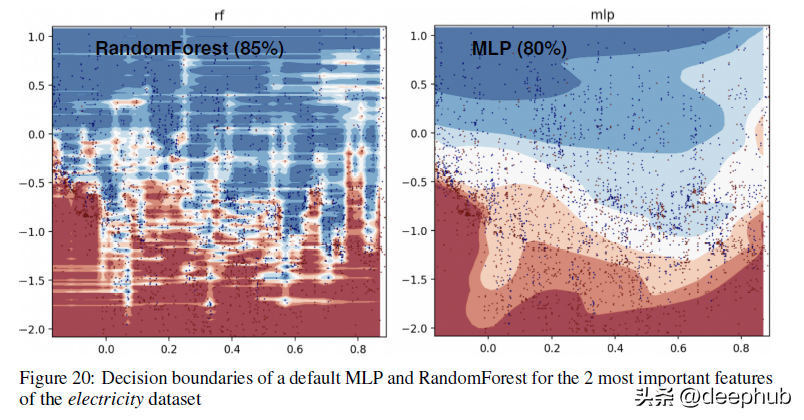
在附录中,作者对上述可视化进行了下面说明:
在这一部分中,我们可以看到 RandomForest 能够学习 MLP 无法学习的 x 轴(对应日期特征)上的不规则模式。 我们展示了默认超参数的这种差异,这是神经网络的典型行为,但是实际上很难(尽管并非不可能)找到成功学习这些模式的超参数。
2、无信息特性会影响类似mlp的神经网络
另一个重要因素,特别是对于那些同时编码多个关系的大型数据集的情况。如果向神经网络输入不相关的特征结果会很糟糕(而且你会浪费更多的资源训练你的模型)。这就是为什么花大量时间在EDA/领域探索上是如此重要。这将有助于理解特性,并确保一切顺利运行。
论文的作者测试了模型在添加随机和删除无用特性时的性能。基于他们的结果,发现了2个很有趣的结果
删除大量特性减少了模型之间的性能差距。这清楚地表明,树型模型的一大优势是它们能够判断特征是否有用并且能够避免无用特征的影响。
与基于树的方法相比,向数据集添加随机特征表明神经网络的衰退要严重得多。ResNet尤其受到这些无用特性的影响。transformer的提升可能是因为其中的注意力机制在一定程度上会有一些帮助。
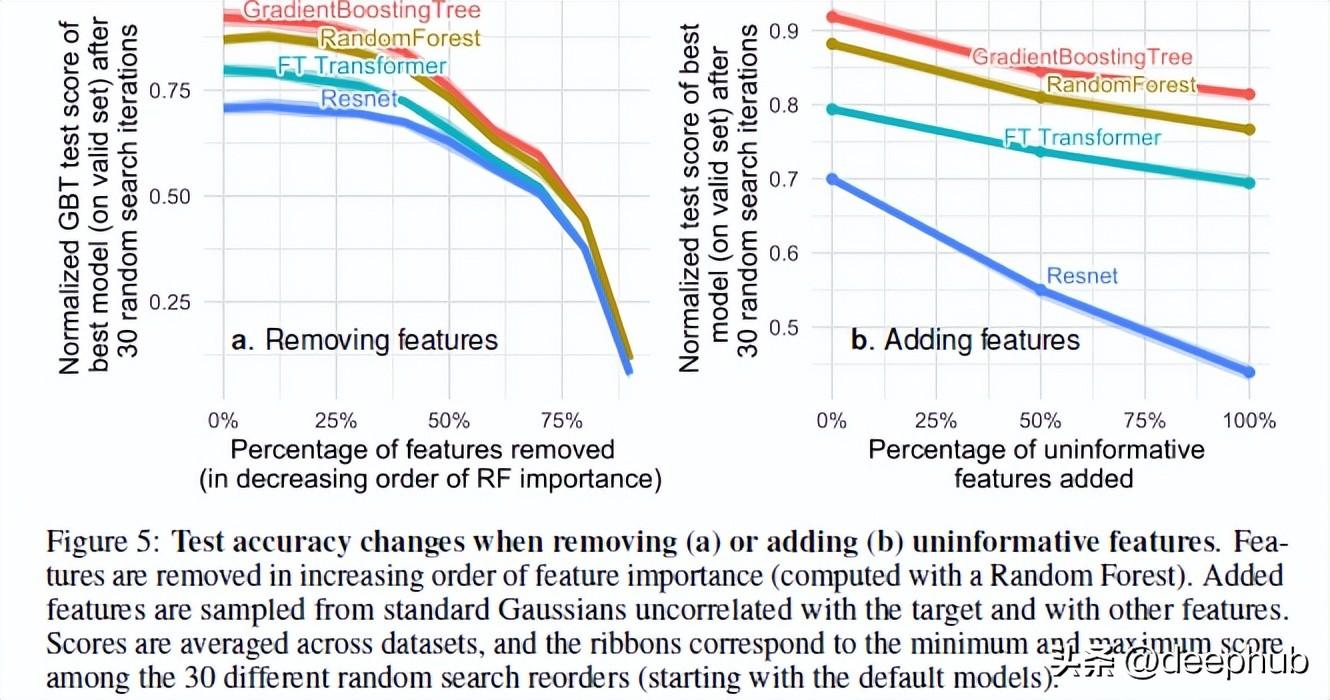
对这种现象的一种可能解释是决策树的设计方式。 任何学习过 AI 课程的人都会知道决策树中的信息增益和熵的概念。这使得决策树能够通过比较剩下的特性来选择最佳的路径。
回到正题,在表格数据方面,还有最后一件事使 RF 比 NN 表现更好。 那就是旋转不变性。
3、NNs 是旋转不变性的,但是实际数据却不是
神经网络是旋转不变的。 这意味着如果对数据集进行旋转操作,它不会改变它们的性能。 旋转数据集后,不同模型的性能和排名发生了很大的变化,虽然ResNets一直是最差的, 但是旋转后他保持原来的表现,而所有其他模型的变化却很大。
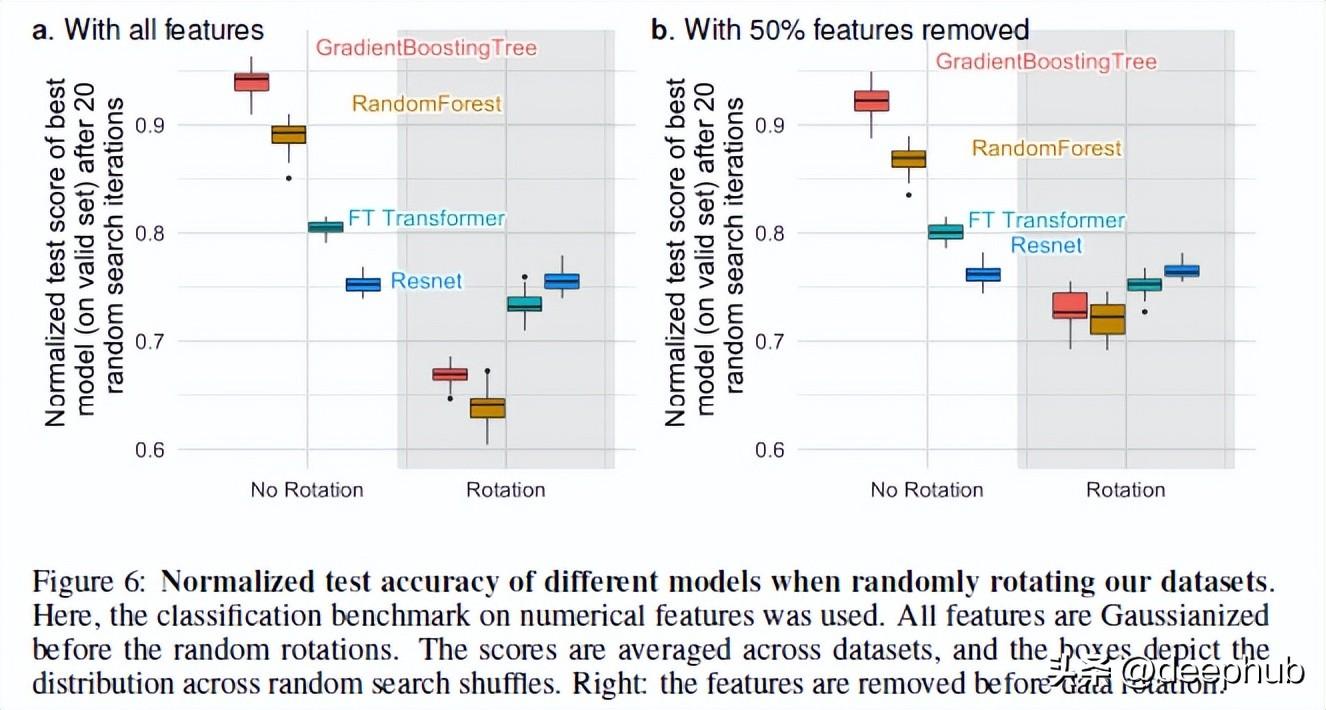
这很现象非常有趣:旋转数据集到底意味着什么?整个论文中也没有详细的细节说明(我已经联系了作者,并将继续跟进这个现象)。如果有任何想法,也请在评论中分享。
但是这个操作让我们看到为什么旋转方差很重要。根据作者的说法,采用特征的线性组合(这就是使ResNets不变的原因)实际上可能会错误地表示特征及其关系。
通过对原始数据的编码获得最佳的数据偏差,这些最佳的偏差可能会混合具有非常不同的统计特性的特征并且不能通过旋转不变的模型来恢复,会为模型提供更好的性能。
总结
这是一篇非常有趣的论文,虽然深度学习在文本和图像数据集上取得了巨大进步,但它在表格数据上的基本没有优势可言。论文使用了 45 个来自不同领域的数据集进行测试,结果表明即使不考虑其卓越的速度,基于树的模型在中等数据(~10K 样本)上仍然是最先进的。