1. 什么是Ceph?
首先,我们从 Ceph的官方网站上,可以看到:“Ceph is a unified, distributed storage system designed for excellent performance, reliability and scalability.” 从它的定义上我们可以明确它是一种存储系统,而且可以明确它所具备的两点特性:
(1)统一性( unified ):意味着可以同时提供对象存储、块存储和文件系统存储三种接口功能。
(2)分布式( distributed ):意味着其内部节点架构是以分布式集群算法为依托的。
接下来,我们从其架构原理以及读写原理上来分析其如何支撑定义当中所提到的各个特性。
2. Ceph的架构原理
2.1 Ceph存储功能架构
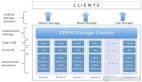
从功能角度来讲,Ceph本身的架构比较清晰明了,主要分应用接口层、存储基础接口层以及存储对象层,接口层主要对客户端的访问负责,分为本地语言绑定接口(C/C++, Java, Python)、RESTful (S3/Swift)、块存储设备接口、文件系统接口。从这个点上,其完整诠释了“统一性( unified )”的特性。
具体如图2.1所示:

图2.1 Ceph存储系统功能图
(1)基础存储系统(RADOS)
RADOS是理解Ceph的基础与核心。
物理上,RADOS由大量的存储设备节点组层,每个节点拥有自己的硬件资源(CPU、内存、硬盘、网络),并运行着操作系统和文件系统。逻辑上,RADOS是一个完整的分布式对象存储系统,数据的组织和存储以及Ceph本身的高可靠、高可扩展、高性能等使命都是依托于这个对象。
(2)基础库(LIBRADOS)
LIBRADOS是基于RADOS对象在功能层和开发层进行的抽象和封装。
从使用功能上,其向上提供使用接口API(RADOSGW、RBD、FS)。从开发上功能上,其向上直接提供本地开发语言的API,主要包括C、C++、JAVA、Python等。这样应用上的特殊需求变更就不会涉及到Ceph存储本身,保障其安全性并且解除了存储系统和上层应用的耦合性。
(3)存储应用接口( RADOS GW、 RBD 、 Ceph FS )
存储应用接口层 包括了三个部分:RADOS Gateway、 Reliable Block Device 、 Ceph FS,其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端 直接 使用的上层接口。其中,RADOS GW是一个提供S3 RESTful API的 网关 ,以供相应的对象存储应用 使用;RBD则提供了一个标准的块设备接口 ;Ceph FS是一个POSIX兼容的分布式文件系统。
读到此处,可能很多人都会有一个疑问:“既然Librados API能提供对象存储应用可以使用的接口,为什么还要搞一个RadosGW API?”
其实这个是基于不同使用者维度来考虑的,就像应用系统的使用者和开发者两个不同维度。使用者仅仅需要知道这个应用系统提供了什么功能,到什么界面去完成使用就可以了。但是开发者可能需要从后台代码当中去解决一系列基于性能、并发量、易用易维护性等维度出现的问题。同样,对于RadosGW API来讲,它仅仅提供了一些通用、固定、易用的少数使用维度的接口,而Librados API则是一个丰富的具备各种使用、开发等维度的接口库。
2.2 Ceph物理组件架构
RADOS是Ceph的核心,我们谈及的物理组件架构也是只RADOS的物理架构。
如图2.2所示,RADOS集群是由若干服务器组成,每一个服务器上都相应会运行RADOS的核心守护进程(OSD、MON、MDS)。具体守护进程的数量需要根据集群的规模和既定的规则来配置。

图2.2 RADOS物理组件架构
结合图2.2,我们首先来看每一个集群节点上面的守护进程的主要作用:
OSD Daemon:两方面主要作用,一方面负责数据的处理操作,另外一方面负责监控本身以及其他OSD进程的健康状态并汇报给MON。OSD守护进程在每一个PG(Placement Group)当中,会有主次(Primary、Replication)之分,Primary主要负责数据的读写交互,Replication主要负责数据副本的复制。其故障处理机制主要靠集群的Crush算法来维持Primary和Replication之间的转化和工作接替。所有提供磁盘的节点上都要安装OSD 守护进程。
MON Daemon:三方面主要作用,首先是监控集群的全局状态(OSD Daemon Map、MON Map、PG Map、Crush Map),这里面包括了OSD和MON组成的集群配置信息,也包括了数据的映射关系。其次是管理集群内部状态,当OSD守护进程故障之后的系列恢复工作,包括数据的复制恢复。最后是与客户端的查询及授权工作,返回客户端查询的元数据信息以及授权信息。安装节点数目为2N+1,至少三个来保障集群算法的正常运行。
MDS Daemon:它是Ceph FS的元数据管理进程,主要是负责文件系统的元数据管理,它不需要运行在太多的服务器节点上。安装节点模式保持主备保护即可。
2.3 Ceph数据对象组成
Ceph的数据对象组成这部分主要是想阐述从客户端发出的一个文件请求,到Rados存储系统写入的过程当中会涉及到哪些逻辑对象,他们的关系又是如何的?首先,我们先来列出这些对象:
(1)文件(FILE):用户需要存储或者访问的文件。对于一个基于Ceph开发的对象存储应用而言,这个文件也就对应于应用中的“对象”,也就是用户直接操作的“对象”。
(2)对象(Object):RADOS所看到的“对象”。Object指的是最大size由RADOS限定(通常为2/4MB)之后RADOS直接进行管理的对象。因此,当上层应用向RADOS存入很大的file时,需要将file切分进行存储。
(3)PG(Placement Group):PG是一个逻辑概念,阐述的是Object和OSD之间的地址映射关系,该集合里的所有对象都具有相同的映射策略;Object & PG,N:1的映射关系;PG & OSD,1:M的映射关系。一个Object只能映射到一个PG上,一个PG会被映射到多个OSD上。
(4)OSD(Object Storage Device):存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略;支持两种类型:副本和纠删码。
接下来,我们以更直观的方式来展现在Ceph当中数据是如何组织起来的,如图2.3:

图2.3 RADOS物理组件架构
结合图2.3所示,我们来看数据的详细映射过程:
(1) File > Object
本次映射为首次映射,即将用户要操作的File,映射为RADOS能够处理的Object。
具体映射操作本质上就是按照Object的最大Size对File进行切分,每一个切分后产生的Object将获得唯一的对象标识Oid。Oid的唯一性必须得到保证,否则后续映射就会出现问题。
(2) Object > PG
完成从File到Object的映射之后, 就需要将每个 Object 独立地映射到 唯一的 PG 当中 去。
Hash(Oid)& Mask > PGid
根据以上算法, 首先是使用Ceph系统指定的一个静态哈希函数计算 Oid 的哈希值,将 Oid 映射成为一个近似均匀分布的伪随机值。然后,将这个伪随机值和 Mask 按位相与,得到最终的PG序号( PG id)。根据RADOS的设计,给定PG的总数为 X(X= 2的整数幂), Mask=X-1 。因此,哈希值计算和按位与操作的整体结果事实上是从所有 X 个PG中近似均匀地随机选择一个。基于这一机制,当有大量object和大量PG时,RADOS能够保证object和PG之间的近似均匀映射。
(3) PG > OSD
最后的 映射就是将PG映射到数据存储单元OSD。RADOS采用一个名为CRUSH的算法,将 PGid 代入其中,然后得到一组共 N 个OSD。这 N 个OSD即共同负责存储和维护一个PG中的所有 Object 。和“object -> PG”映射中采用的哈希算法不同,这个CRUSH算法的结果不是绝对不变的,而是受到其他因素的影响。
① 集群状态(Cluster Map):系统中的OSD状态 。数量发生变化时, CLuster Map 可能发生变化,而这种变化将会影响到PG与OSD之间的映射。
② 存储策略配置。系统管理员可以指定承载同一个PG的3个OSD分别位于数据中心的不同服务器乃至机架上,从而进一步改善存储的可靠性。
到这里,可能大家又会有一个问题“为什么这里要用CRUSH算法,而不是HASH算法?”
这一次映射,我们对映射算法有两种要求:
一方面,算法必须能够随着系统的节点数量位置的变化,而具备动态调整特性,保障在变化的环境当中仍然可以保持数据分布的均匀性;另外一方面还要有相对的稳定性,也就是说大部分的映射关系不会因为集群的动态变化发生变化,保持一定的稳定性。
而CRUSH算法正是符合了以上的两点要求,所以最终成为Ceph的核心算法。
3. Ceph的读写原理
3.1 Ceph IO流程
Ceph的IO框架当中会涉及到三个角色:客户端(Client)、元数据节点(MON)、数据节点(OSD)。这个有点类似于Hadoop。客户端首先发送数据读写请求到元数据节点上进行存储空间的寻址,元数据节点根据数据请求获取数据的地址空间信息,然后客户端根据地址空间分布信息分别到所涉及的数据节点上查找相应数据片或者是将数据写入相应数据节点的存储空间地址。如图3.1所示,

图3.1 Ceph IO流程图
结合图3.1,具体说来,包括如下几个详细步骤:
- Client创建Cluster Handle。
- Client读取配置文件。
- Client连接上元数据节点,获取集群上的数据映射信息。
- Client根据CRUSH算法,计算获得数据的所有OSD节点(Primary),然后进行数据读写。
- 如果是数据的写操作,Primary OSD会同时写入另外两个副本节点数据。
- Primary OSD等待另外两个副本节点写完数据状态返回并将ACK信息返回客户端。
3.2 Ceph故障IO流程
从正常的IO场景下到发生故障后的IO处理,会经过正常读写、故障过度、集群稳定三个阶段。正常阶段的数据读写会通过(Client > Monitor,Client > OSD Primary > OSD Replic)这样的流程,在整个过程中OSD Primary是数据处理的核心角色。如果OSD Primary 发生故障,就会通过故障侦测机制发现故障节点,然后通过CRUSH算法重新分配新的OSD Primary,重新同步数据一系列过程。如果这个时候客户端恰好要读取数据,就会需要新的机制满足客户端的读请求。具体如图3.2所示:

图3.2 Ceph故障场景下的IO流程图
首先,我们来看从正常场景到发生OSD主节点故障的这个阶段:
- 集群内部通过心跳机制发现故障,这个心跳机制分两种:Monitor和OSD之间的主动和被动检测机制,OSD之间的相互检测机制;
- 新的OSD Primary节点接受任务并选择合适的OSD Replic节点进行数据同步;
- 新的OSD Primary节点通知Monitor临时的数据处理方案(将OSD Replic 节点作为临时主节点响应客户端的数据请求处理)。
当新的OSD Primary节点数据同步完成后,进入到正常阶段:
- 通知Monitor更新集群映射配置信息。
- 正式接管数据读写任务,成为Primary OSD节点,集群恢复新的稳定状态。
4. 结语
从Ceph的架构原理上来看,我们不难看出其定义当中的“扩展性、稳定性”。但是关于“优秀性能”这个描述的特性来讲,其实是需要斟酌其语境的。我们不能从其架构的分布式模式上简单判断多个节点服务的性能一定是最优秀的。如果单从架构上来看,对一些可以直接以对象方式存储及访问的场景来说,Ceph的IO深度以及接口的衔接维度看,更利于发挥其性能的优势。对于一些大文件存储读取场景来讲,可以通过2M/4M这样粒度的切分使得读写的性能更容易被横向扩展的架构发挥出来。但是如果是RBD的模式,尤其是小数据事务处理场景(例如关系数据库),由于对象可切分的粒度有限,横向并发读写的优势就发挥不出来了,而且现实业务场景当中的热点数据问题往往集中在某一部分小粒度的数据片上,很有可能压力会落到某个或者某几个OSD上。因此,多维度去看Ceph,才能挖掘其真正价值,后续继续挖掘其他维度上的优劣。