总会有面试官问:你知道 MySQL 如何保障数据不丢的吗?实际上这个问题是十分不准确的,MySQL 保障数据不丢的手段可太多了。但通常面试官想听的内容就是 redo log 两段式提交是如何保障数据不丢的。(不过个人感觉这么说还是不太准确)
所谓「redo log」,意即「重做日志」,也就是用来恢复数据用的日志。所谓「两段式提交」,也被称作「两阶段提交」(Two-Phase Commit,简称 2PC)。本文主要讲 MySQL 内部 XA 事务中 redo log 两段式提交的细节。为了让大家饱餐一顿,我会先为大家上亿点点前菜,虽然有点多,但是相信会很开胃。
开胃前菜
你知道什么是存储引擎、随机 IO 和顺序 IO吗?你知道 MySQL 中的缓冲池吗?binlog、redo log 听说过吗?都有什么用?什么?你都不知道?面试结束了。
什么是存储引擎?
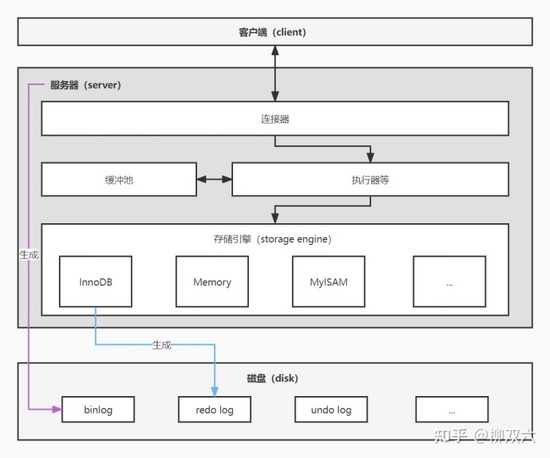
存储引擎是 MySQL 中直接与磁盘交互部分。页是存储引擎读写数据的最小单位,一个页里可以有一条或多条表记录。MySQL 中的存储引擎有很多种,比如 InnoDB、MyISAM、Memory 等。其中最常用的是 InnoDB。而 InnoDB 是 MySQL 中唯一能够完整支持事务特性的存储引擎,也是一个高性能的存储引擎。本文要讲的「两段式提交」就发生在 InnoDB 中。
什么是随机 IO 和顺序 IO?
磁盘读写数据的两种方式。随机 IO 需要先找到地址,再读写数据,每次拿到的地址都是随机的。就像送外卖,每一单送的地址都不一样,到处跑,效率极低。而顺序 IO,由于地址是连贯的,找到地址后,一次可以读写许多数据,效率比较高。就像送外卖,所有的单子地址都在一栋楼,一下可以送很多,效率很高。
什么是缓冲池?
关系型数据库的特点就是需要对磁盘中大量的数据进行存取,所以有时候也被叫做基于磁盘的数据库。正是因为数据库需要频繁对磁盘进行 IO 操作,为了改善因为直接读写磁盘导致的 IO 性能问题,所以引入了缓冲池。
缓冲池是一片内存区域,存储引擎在读取数据时,会先将页读取到缓冲池中。下次读取时,先判断是否在缓冲池,如果在,则直接读取,否则从磁盘中读取。在修改数据时,如果缓冲池中不存在所需的数据页,则从磁盘读入缓冲池,否则直接对缓冲池中的数据页进行修改。
这样的好处是,如果我们频繁修改某一个位于磁盘的数据页,我们可以不用每次都去磁盘读写(注意是读和写)该页,而是直接对缓冲池中的内容修改,在一定的时机再把数据刷新到磁盘。这样就会使得对磁盘的多次操作变为一次。即便修改的内容在磁盘中相距较远的不同数据页上,我们也可以将对多次对磁盘的 IO 合并为一次随机 IO。被修改的数据页会与磁盘上的数据产生短暂的不一致,我们称此时缓冲池中的数据页为 脏页 ,将该页刷到磁盘的操作称为 刷脏页 (本句是重点,后面要吃)。这个刷脏页的时机我们看看就好:[^1]
innodb_max_dirty_pages_pct由于这个刷脏页的过程还是异步的,这样更新操作就不需要等待磁盘的 IO 操作了。因此这些特点极大地提升了 InnoDB 的性能。
什么是binlog?
binlog 是 MySQL 服务器层面实现的一种二进制日志,用于记录所有对数据库的更改操作(这种日志被称为逻辑日志)。比如你 update 一条记录,服务器就会记录一条对应的信息到 binlog。但在 InnoDB 中,这个 binlog 是以事务为单位刷新到磁盘的[^2]。基于 binlog 的这种特性,一般我们会将 binlog 用于以下几个方面:[^2]
数据库增量备份与恢复:在使用备份还原数据后,可以使用 binlog 中记录的内容对备份时间点(简称备份点)后的数据进行恢复。因为 binlog 会还会记录下更改操作的时间,所以 binlog 可以恢复到某一具体时间点的数据。这就为我们删库后提供了除跑路以外的第二个选项:使用 binlog 恢复数据。
主从复制:MySQL 从服务器可以通过订阅 binlog 实现对主服务器的增量复制。
审计:通过对 binlog 中的数据进行审计,判断是否存在安全问题,比如 SQL 注入。
使用 binlog 进行恢复的流程是:[^5]
- 先通过最新的备份恢复数据库的数据,并记录下备份文件备份的时间点。
- 在 binlog 中找到这个时间点,提取这个时间点以后的数据用于实现对备份点后数据的恢复(这个特性被称为 Point in Time,简称 PIT)。
各个部分之间的关系
正餐开始
食欲打开了,后面的内容我们就能吃的下了。
什么是 redo log?
前面我们讲到数据页在缓冲池中被修改会变成脏页。如果这时宕机,脏页就会失效,这就导致我们修改的数据丢失了,也就无法保证事务的持久性。保证数据不丢,就是 redo log 的一个重要功能。我们已经了解,如果我们修改了缓冲池中的数据页就立刻刷脏页,会产生大量随机 IO,导致磁盘性能变差;但如果我们先写缓冲,一段时间后再刷脏页,就有可能造成数据丢失,无法保证事务的持久性。这可有点难了。
于是救世主来了,救世主的名字叫 WAL(Write-Ahead Logging,日志先行) 。即:事务提交前先写日志,再修改页(修改页的时机就是刷脏页的时机)。这里所谓的日志,就是 redo log。redo log 不会记录对整个页的修改,而是大概像这种:
xx 表空间,xx 页,xx 位置,xx 值
记录下对磁盘中某某页某某位置数据的修改结果(这种日志被称为物理日志),这样会节省很多磁盘空间。 由于 redo log 是顺序写(顺序 IO),因此能有效提升 IO 效率;又因为每次事务提交前会先写 redo log,因此可以保障更新的数据不丢失。
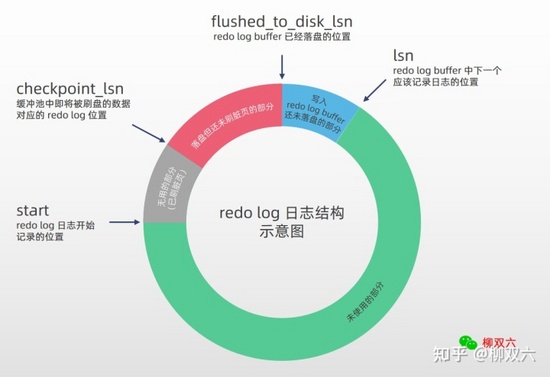
我们知道,一旦脏页刷新,磁盘上对应的 redo log 就会失效,所以 redo log 用完后,可以再回头使用,这样更节省空间。直到需要刷 redo log buffer 时发现接下来的 redo log 对应的脏页未被刷新,此时会强制刷新脏页。缓冲池的好处我们前面已经讲过,所以 redo log 弄了个类似作用的 redo log buffer。在写 redo log 时会先写 redo log buffer,并在以下时机将 redo log 刷新到磁盘:[^3]
- 每秒刷新一次
- 事务提交时
- redo log buffer 剩余空间小于 1/2 时
我们理应想到,如果脏页没刷完,数据库宕机了,那么必然是需要使用 redo log 来恢复数据的。那么 redo log 应该从哪开始恢复数据呢?为解决这个问题 InnoDB 为 redo log 记录了序列号,这被称为 LSN(Log Sequence Number),可以理解为偏移量,越新的日志 LSN 越大。InnoDB 用检查点( checkpoint_lsn )指示未被刷盘的数据从这里开始,用 lsn 指示下一个应该被写入日志的位置。不过由于有 redo log buffer 的缘故,实际被写入磁盘的位置往往比 lsn 要小。
为了大家能有个更整体的概念,咱们再多吃一道配菜:undo log。InnoDB 能够保证对事务的完整支持,这主要就得益于 redo log 和 undo log。redo log 我们讲了,能够保证缓冲池中被修改的数据页不丢以及在数据库宕机后对丢失的数据进行自动恢复。而 undo log 则用于实现 MVCC 和事务回滚。在事务执行的过程中,不但会记录 redo log,还会记录 undo log。至于更多细节,大家自行去了解吧。
那么 redo log 到底如何保障数据不丢的?
如何保障数据不丢?
假设我们有一个表 t1,数据如下:
mysql> select * from t1;
+----+------+
| id | name |
+----+------+
| 1 | a |
+----+------+
当我们执行如下 update 语句时:
mysql begin; update t1 set name='aa' where id=1; commit;
InnoDB 内部的流程是这样的:
- 服务器收到事务开始的指令,为事务生成一个全局唯一的事务 id。这个事务 id 在记录 binlog 和 redo log 时都会使用。
- 如果缓存池中没有 id=1 所在数据页的数据,从磁盘中找到对应的数据页(注意,这里是一个数据页,不是一条记录),把数据页加载到缓存。
- 修改缓存数据页中 id=1 的数据。
- 记录数据到 redo log buffer[^4]、binlog cache[^2]。根据 redo log 刷盘的策略,这个过程中 redo log buffer 可能会被刷新到磁盘。
- 服务器收到事务提交的指令。
- 刷新 redo log buffer 到磁盘,并标记该事务的状态为 prepare。此操作称为 redo log prepare。
- 刷新 binlog cache 到磁盘。
- 刷新 redo log buffer 到磁盘,并标记该事务的状态为 commit。此操作称为 redo log commit。
- 向客户端返回事务执行的结果。
这样 redo log 先 prepare,再刷新 binlog ,再 redo log commit 的过程就是一次两段式提交。这种只在 MySQL 内部组件间保障数据一致性的操作,也被称作内部 XA 事务;与之对应的是,保障跨服务器间数据一致性的两段式提交,被称为外部 XA 事务,即分布式事务。
注:XA 事务属于分布式事务中两段式提交事务的一种实现
在宕机后,重启 MySQL 时,InnoDB 会自动恢复 redo log 中 checkpoint_lsn 后的,且处于 commit 状态的事务。如果 redo log 中事务的状态为 prepare,则需要先查看 binlog 中该事务是否存在,是的话就恢复,否则就回滚(通过 undo log 回滚。脏页一直在刷,更新了脏页,但事务没提交就宕机了,所以需要回滚)。
消化一下
发生宕机怎么办?
MySQL 宕机可能会发生在整个过程中的任意时刻。以刚才的流程为例,假设宕机发生在第 5 步后、第 6 步前。此时服务器还未向客户端返回事务的结果,而 redo log 中可能记录了该事务的 redo log,也可能没有。但是只要该事务没有被标记为 prepare,我们就认为该事务没有执行完,否则 redo log 用于恢复事务的数据可能是不完整的。因此,只要此时我们选择抛弃未 prepare 的 redo log,不会导致任何数据一致性的问题。
那么后面的步骤宕机会怎样呢?这就涉及到为什么非得要两阶段提交了。
为什么非得要两阶段提交?
在说明以前,我们还需要弄清两个问题:
- 有 binlog 为什么还要 redo log ?
- 有 redo log 为什么还要 binlog?
有 binlog 为什么还要 redo log ?
- binlog 不知道数据库究竟是在哪一时刻丢失了哪部分数据,只能从备份点开始对 binlog 记录重放来恢复数据,比较耗时。
- binlog 恢复是需要我们手动执行的,而 redo log 可以在服务器重启后自动恢复数据。
- WAL + 先写缓冲 + 异步刷脏页有效提升了磁盘的 IO 效率。
有 redo log 为什么还要 binlog?
- binlog 是服务器层面的功能,redo log 是 innoDB 的功能。redo log 帮助 InnoDB 实现了性能提升、自动恢复。但其他存储引擎是无法使用 redo log 的能力的。
- 我们也可以关闭 binlog,但大多数情况下我们都会开启,因为开启的好处更多。比如,主从模式需要订阅 binlog 进行主从复制,以及可以通过 binlog 进行数据库的增量备份和恢复。
redo log 有很多好处,所以我们不能放弃;binlog 也有很多好处,我们也不能放弃。也就是说,这两个功能我们都需要开启。既然都要开启,那么 我们必须保证 redo log 和 binlog 数据的一致性。 如果 binlog 有 redo log 没有,那么 redo log 宕机自动恢复时的数据就会缺少;反之,redo log 有,binlog 没有,如果开启了主从模式,主服务器因为 redo log 恢复了数据,但从服务器靠消费 binlog 保证和主服务器数据一致,这就导致从服务器比主服务器数据少。
那么为什么非得要写两次,我们能不能只写一次 redo log?
这样仍然会有不一致问题。比方说,先写 binlog 再写 redo log:
此时如果有大量并发,我们 binlog 噌噌噌往上写,redo log 还没写完,宕机机了,两者的数据就会出现大量不一致现象。此外,因为 binlog 数据最完整,这样会导致我们必须从 binlog 回滚,而且还得是手动回滚。InnoDB 本来是可以自恢复的存储引擎,这样一来,自恢复的特性不是没了,redo log 不是白开发了?使用 binlog 恢复 redo log 更不用想了,因为 binlog 根本不知道从何处开始恢复(它没有 checkpoint_lsn )。
再说先写 redo log 再写 binlog:
不一致性的问题与上述内容相似。另外还会导致 redo log 在恢复时,每次都需要去 binlog 查看该事务是否已写入,严重影响性能。而如果是两阶段提交,处于 commit 阶段的事务都会直接恢复,处于 prepare 阶段才需要去看 binlog。
那用 redo log 恢复 binlog 不行吗?
第一,binlog 是服务器的特性,redo log 是 InnoDB 的特性,两者并不在一个层面上,能不能这么做,很难说。第二,即便可以,也增加了很大的复杂度, redo log 中记录的数据(物理日志)能不能复原 SQL 语句,如何复原,这都是需要思考的问题。远远不如直接使用两阶段提交方便。
两段式提交会不会影响性能?
InnoDB 使用了组提交的方式,尽量降低了两阶段提交带来的性能影响。在并发事务较多的情况下,MySQL 会将多个事务的 redo log 放在一起提交,大大节省了磁盘 IO。具体就不在此展开了。binlog 刷盘时同样也会采取类似的策略。
吃点饭后甜点吧
如果你搞明白了上面的内容,你会发现「基于事务消息的分布式事务」使用的就是典型的 2PC 思想,你又会发现「基于本地消息的分布式事务」使用的就是典型的 WAL 思想。如果你不了解,马上去学一下吧!