












当前,人工智能在企业规模化应用中,存在诸多难点,比如:研发上线周期长,效果不及预期,数据和模型难匹配等。在此背景下,MLOps应运而生。MLOps作为帮助在企业中扩展机器学习的一项关键技术正在崛起。
日前,由51CTO组织的AISummit 全球人工智能技术大会成功举办。在会议开设的“MLOps最佳实践”专场,开放原子基金会 TOC副主席谭中意、第四范式系统架构师卢冕、网易云音乐人工智能研究员吴官林、中国工商银行软件开发中心大数据和人工智能实验室副主任黄炳带来了各自的主题演讲,围绕研发运维周期、持续训练和持续监控、模型版本和血缘、数据线上线下一致性、高效数据供给等热点方向,探讨了MLOps的实战效果和前沿趋势。
MLOps的定义和评估
Andrew NG曾在多个场合表达过AI已经从model centric 转到 data centric,数据是AI落地最大的挑战。如何保证数据的高质量供给是关键问题,而要解决好这个问题,需要利用MLOps的实践来帮助AI多快好省的落地。
那么,MLOps解决哪些问题?如何评估MLOps项目的成熟度?开放原子基金会 TOC副主席、LF AI & Data TAC成员谭中意带来了主题演讲《从model centric 到 data centric — MLOps帮助AI多快好省的落地》,对此进行了详细的介绍。
谭中意首先分享了一批业内科学家和分析师的观点。Andrew NG认为,提高数据质量比提高模型算法,更能提升AI落地效果,在他看来,MLOps最重要的任务就是在机器学习生命周期的各个阶段,始终保持高质量的数据供给。
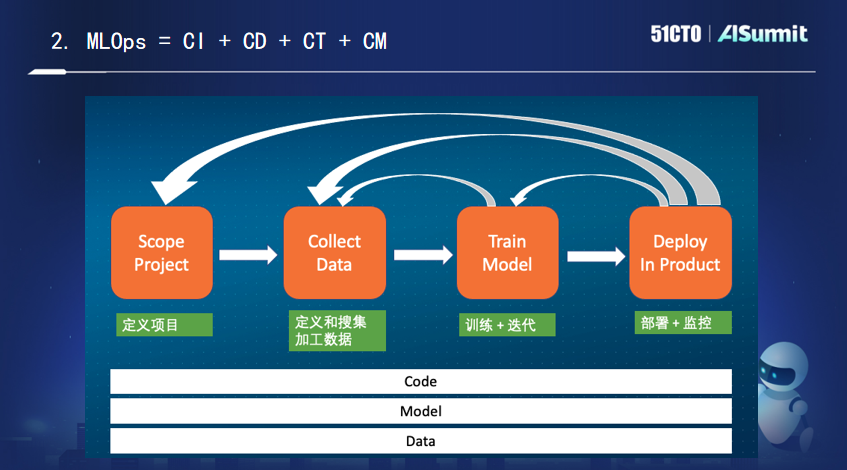
要实现AI的规模化落地,必须发展MLOps。至于到底什么是MLOps,业内莫衷一是,他给出了自己的解释:它是“代码+模型+数据的持续集成、持续部署、持续训练和持续监控”。
接着,谭中意重点介绍了机器学习领域特有的平台Feature Store(特征平台)的特性,以及目前市面上主流的特征平台产品。
最后谭中意就MLOps的成熟度模型进行了简要阐述。他提到,微软Azure按照机器学习全流程的自动化程度的高低,把MLOps的成熟模型分成了(0、1、2、3、4)这几个等级,其中0是没有自动化的,123是部分自动化,4是高度自动化。
线上线下一致的生产级特征平台
在很多机器学习场景中,面临着实时特征计算的需求。从数据科学家离线开发的特征脚本,到线上实时特征计算,AI 落地的成本非常高。
针对这一痛点,第四范式系统架构师、数据库团队和高性能计算团队负责人卢冕在主题演讲《开源机器学习数据库 OpenMLDB:线上线下一致的生产级特征平台》中重点展示了 OpenMLDB如何实现机器学习特征开发即上线的目标,以及如何保证特征计算的正确性、高效性。
卢冕指出,随着人工智能工程化落地的推进,在特征工程环节,线上线上的一致性校验带来了高昂的落地成本。而OpenMLDB恰恰提供了低成本的开源解决方案,它不仅解决了核心问题-机器学习线上线下的一致性,解决了正确性的问题,而且实现了毫秒级的实时的特征计算。这是其核心价值所在。
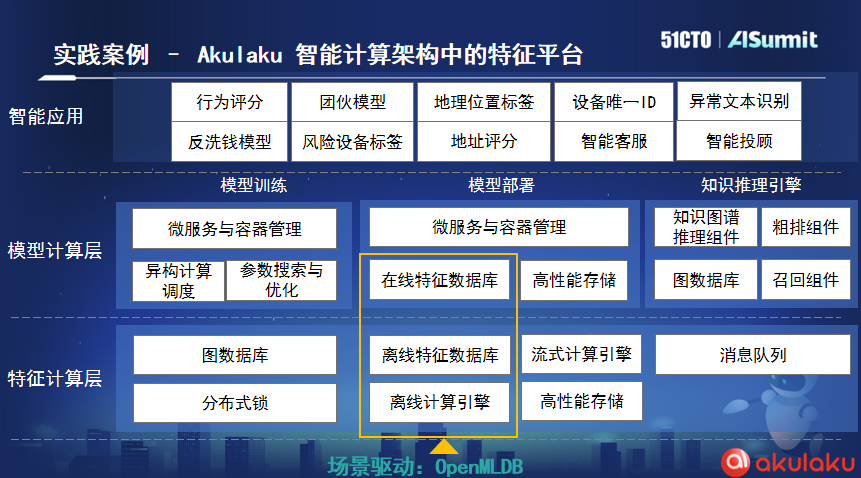
据卢冕介绍,印尼线上支付公司Akulaku是OpenMLDB开源以后的第一个社区企业用户,他们把OpenMLDB整合在其智能计算架构中。在实际业务中,Akulaku平均一天要处理将近10亿条订单数据,使用OpenMLDB后,其处理数据的延迟仅仅在4毫秒,充分满足了他们的业务需求。
构建端到端机器学习平台
依托网易云音乐海量数据、精准算法、实时系统的基础,服务于内容分发和商业化多场景,同时满足既要建模效率高,也要使用门槛低,还要模型效果显著等一系列算法工程追求,为此网易云音乐算法工程团队结合音乐业务开始了端到端机器学习平台的实践落地。
网易云音乐人工智能研究员、技术总监吴官林带来了主题演讲《网易云音乐特征平台技术实践》,从云音乐业务背景出发,阐释模型实时化落地方案,结合Feature Store进一步和与会者分享了其思考。
吴官林提到,在云音乐模型算法工程的建设中,主要面临实时化程度低、建模效率低、线上线下不一致导致模型能力受限三大痛点。针对这些痛点,他们从模型实时化开始,在模型实时化覆盖业务的过程中去构建相应的Feature Store平台。
吴官林介绍,他们首先进行了模型实时化在直播场景上的探索并取得了一定成效。在工程上,也探索出一个完整的链路,并落地了一些基础工程建设。但模型实时化聚焦在精排实时场景,但80%以上场景是离线模型。在全链路建模过程中,每个场景开发者都从原点做数据开始,导致了建模周期长,效果还不可预期,新手开发门槛高等问题。考虑到一个模型上线周期,80%时间在做数据相关,其中特征占比高达50%。他们开始着手沉淀特征平台Feature Store。
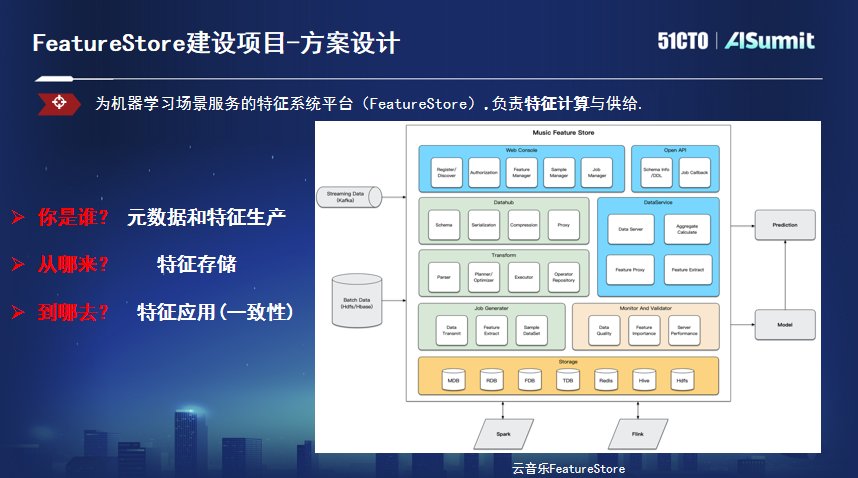
Feature Store主要解决了三方面的问题:一是定义元数据,统一特征血缘、计算、推送过程,实现基于批流一体的高效特征生产链路;二是针对特征的特性进行改造,解决特征存储问题,根据实际使用场景对延迟和吞吐量的不同,提供各种类型的存储引擎;三是解决特征一致性的问题,从统一的API读取指定格式的数据,作为机器学习模型的输入,用于推理、训练等。
金融智能化发展的新基建
中国工商银行软件开发中心大数据和人工智能实验室副主任黄炳在其主题演讲《筑牢金融智能化创新发展的人工智能新基建》重点介绍了工商银行的MLOps实践,涵盖模型研发、模型交付、模型管理、模型迭代运营的全生命周期管理体系的建设流程及技术实践。
之所以需要MLOps,是因为人工智能如火如荼的发展背后,很多已经发生或潜在的“AI技术债”不容忽视。黄炳认为,MLOps的理念是可以解决这些技术债的,“如果说DevOps是解决软件系统技术债问题的利器,DataOps是打开数据资产技术债问题的钥匙,那么脱胎于DevOps理念的MLOps就是治疗机器学习技术债问题的良药”。
在建设过程中,工商银行的MLOps实践经验可以总结为四点:夯实公共能力之“基”,建设企业级数据中台,实现数据沉淀共享;降低应用门槛之“器”,建设相关的建模和服务组装流水线,形成流程化、积木组装化的研发模式;建立AI资产沉淀共享之“法”,最大限度降低AI建设的成本,形成共享共建生态的关键所在;形成模型运营迭代之“术”,根据数据驱动、按照业务价值驱动,建立模型运营体系,是模型质量持续迭代和量化评价的基础。
演讲尾声,黄炳做了两点展望:第一,MLOps需要更安全、更合规。未来企业发展需要非常多的模型来实现数据驱动的智能决策,因此会衍生出更多与模型相关的开发、运维、权限管控、数据隐私、安全性和审计等企业级需求;第二,MLOps需要与其他Ops结合。解决技术债问题是一个复杂的过程,DevOps方案、DataOps方案和MLOps方案必须协调联动,互相赋能,才能充分发挥三者的全部优势,实现“1+1+1>3”的效果。
写在最后
据IDC预测,到2024年将有60%的企业使用MLOps来实施机器学习工作流。IDC分析师Sriram Subramanian曾如此评价:“MLOps将模型速度缩短到几周——有时甚至是几天,就像使用DevOps加快应用构建的平均时间一样,这就是为什么你需要MLOps。”
当前,我们正处在人工智能快速扩展的拐点上。企业通过采用MLOps可以构建更多模型、更快地实现业务创新,更加多快好省地推进AI的落地。千行百业正在见证和验证着这样一个事实:MLOps正在成为企业AI规模化的催化剂。更多精彩内容请点击查看。





















