Labs 导读
随着云原生的普及,越来越多的后端应用进行了容器化迁移,并通过k8s进行编排管理。而最近这几年,大数据领域比如Flink,Spark等计算引擎也纷纷表示对k8s的支持,使得大数据应用从传统的yarn时代转变为云原生时代。本文以Flink和k8s为主要技术手段,介绍如何搭建一个云原生计算平台。
Part 01 K8s概述
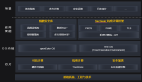
Kubernetes,又称为k8s或者kube,是一种可自动实施Linux容器操作的开源平台。它可以帮助用户省去应用容器化过程的许多手动部署和扩展操作。也就是说,您可以将运行Linux容器的多组主机聚合在一起。由k8s帮助您轻松高效地管理这些集群。而且,这些集群可跨公共云、私有云或混合云部署主机。其架构图如下:

注:
- kubectl: 使用Kubernetees API与Kubernetes集群的控制面通信的命令行工具。
- ETCD: 一种分布式健值存储,用于分布式系统或计算机集群的🎉配置、服务发现和调度协调。
- Node(节点): 负责执行请求和所分配任务的计算机。
- Pod(容器集): 被部署在单个节点上的,且包含一个或多个容器的容器组。
- Kubelet: 运行在节点上的服务,可读取容器清单,确保指定的容器启动并运行。
1.在Master上,是由Controller,API Server,Scheduler 以及包括做存储的Etcd等构成。Etcd可以算成Master,也可以作为独立于Master之外的存储来对待。Master的Controller、API Server、Scheduler都是单独的进程模式。这和Yarn有一些不同,Yarn的整个Master是一个单进程的模式。K8s的Master还可以在多个Master之间完成自发的选举,然后由active状态的Master对外提供服务。
2.在Slave上,它主要是包括Kube proxy、Kubelet,以及Docker等相关的组件,每个Node上部署的相关组件都是类似的,通过它来管理上面运行的多个Pod。
3.根据不同用户的习惯,可以通过UI或者CLI的方式向K8s提交任务。用户可以通过K8s提供的Dashboard Web UI的方式将任务进行提交,也可以通过Kubectl命令行的方式进行提交。
Part 02 Flink概述
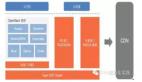
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。其架构图如下:

Flink整个系统包含三个部分:
Client:Flink Client主要给用户提供向Flink系统提交用户任务(流式作业)的能力。
TaskManager:Flink系统的业务执行节点,执行具体的用户任务。TaskManager可以有多个,各个TaskManager都平等。
JobManager:Flink系统的管理节点,管理所有的TaskManager,并决策用户任务在哪些Taskmanager执行。JobManager在HA模式下可以有多个,但只有一个主JobManager。
Part 03 Flink on K8s部署模式
Flink的部署方式有很多,支持Local,Standalone,Yarn,Docker,Kubernetes模式等。而根据Flink job的提交模式,又可以分为三种模式:

模式1:Application Mode
Flink提交的程序,被当做集群内部Application,不再需要Client端做繁重的准备工作。(例如执行main函数,生成JobGraph,下载依赖并分发到各个节点等)。main函数被提交给JobManager执行。一个Application一个Cluster实例。
模式2:Per-Job Mode
可以理解为 Client 模式的Application Mode,利用资源管理框架,例如Yarn,Mesos等,资源隔离性更强。一个Job一个Cluster实例。逐渐被废弃。
模式3:Session Mode
也是由Client提交,做一些预备工作。但是Cluster的实例已经被创建,是所有Job共享的。一个Job导致的JobManager失败可能会导致所有的Job失败。
总的来说,在k8s上可以运行以下四种模式:standalone session,standalone application, native session和native application。其特点如下:

根据以上特点,一般生产采用native application模式部署。其启动流程图如下:

1.首先创建出了 Service、Master 和 ConfigMap 这几个资源以后,Flink Master Deployment 里面已经带了一个用户 Jar,这个时候 Cluster Entrypoint 就会从用户 Jar 里面去提取出或者运行用户的 main,然后产生 JobGraph。之后再提交到 Dispatcher,由 Dispatcher 去产生 Master,然后再向 ResourceManager 申请资源,后面的逻辑的就和 Session 的方式是一样的。
2.它和 Session 最大的差异就在于它是一步提交的。因为没有了两步提交的需求,如果不需要在任务起来以后访问外部 UI,就可以不用外部的 Service。可直接通过一步提交使任务运行。通过本地的 port-forward 或者是用 K8s ApiServer 的一些 proxy 可以访问 Flink 的 Web UI。此时,External Service 就不需要了,意味着不需要再占用一个 LoadBalancer 或者占用 NodePort。
Part 04 Flink on native k8s部署实战
部署Flink之前需要一个正在运行的k8s集群,且满足以下几点需求:
- Kubernetes >= 1.9。
- KubeConfig,它可以列出、创建、删除 Pod 和服务,可通过 ~/.kube/config 进行配置。您可以通过运行 kubectl auth can-i <list|create|edit|delete> pods 来验证权限。
- 启用 Kubernetes DNS。
- 具有创建、删除 Pod 的 RBAC 权限的默认服务帐户。
在有了以上的k8s集群后,接下去我们需要执行以下步骤来启动一个k8s native application任务:
1.创建一个名字为flink-cluster的namespace
kubectl create namespace flink-cluster
2.创建一个账户
Kubectl create serviceaccount flink -n flink-cluster
3.Service account和角色绑定
kubectl create clusterrolebinding flink-role-binding-flink \
--clusterrole=edit \
--serviceaccount=flink-cluster:flink
4.编写Dockerfile文件
# base image
FROM apache/flink:1.14.5-scala_2.11
RUN mkdir -p $FLINK_HOME/usrlib
RUN mkdir -p $FLINK_HOME/hadoopconf
COPY flink-1.14.5/examples/streaming/TopSpeedWindowing.jar $FLINK_HOME/usrlib/TopSpeedWindowing.jar
COPY core-site.xml $FLINK_HOME/hadoopconf
COPY hdfs-site.xml $FLINK_HOME/hadoopconf
# 添加hdfs的相关的jar,为了读取hdfs
COPY flink-shaded-hadoop2-uber-2.8.3-1.8.3.jar $FLINK_HOME/lib
# 配置HADOOP_CONF_DIR为了获取hadoop的core-site.xml and hdfs-site.xml ,因为checkpoint是存在hdfs的,需要读写hdfs
ENV HADOOP_CONF_DIR=$FLINK_HOME/hadoopconf:$HADOOP_CONF_DIR
5.打镜像
docker build -t apache/flink:v0.1 .
打镜像的目录下存在的文件
core-site.xml
Dockerfile
flink-1.14.5
flink-shaded-hadoop2-uber-2.8.3-1.8.3.jar
hdfs-site.xml
6.启动application mode的任务
./flink-1.14.5/bin/flink run-application \
--target kubernetes-application \
-Dkubernetes.namespace=flink-cluster \
-Dkubernetes.jobmanager.service-account=flink \
-Dkubernetes.cluster-id=my-first-application-cluster \
-Dkubernetes.high-availability=org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory \
-Dkubernetes.cluster-id=my-first-application-cluster \
-Dhigh-availability.storageDir=hdfs://${your hdfs cluster name}/flink/recovery \
-Dkubernetes.container.image=apache/flink:v0.1 \
-Dkubernetes.rest-service.exposed.type=NodePort \
-Dstate.backend=rocksdb \
-Dstate.checkpoints.dir=hdfs://${your hdfs cluster name}/flink/flink-checkpoints \
-Dstate.backend.incremental=true \
local:///opt/flink/usrlib/TopSpeedWindowing.jar
启动之后会在最后出现如下的日志,最后的地址就是该任务的web ui地址
2022-07-27 16:45:00,320 INFO org.apache.flink.kubernetes.KubernetesClusterDescriptor [] - Create flink application cluster my-first-application-cluster successfully, JobManager Web Interface: http://ip:port
启动之后我们会看到k8s启动了以下的flink的组件
[root@master1 ~]# kubectl get svc -n flink-cluster
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-first-application-cluster ClusterIP None <none> 6123/TCP,6124/TCP 1h
my-first-application-cluster-rest ClusterIP ip xxxx <none> 8082/TCP 46h
[root@master1 ~]# kubectl get deployments -n flink-cluster
NAME READY UP-TO-DATE AVAILABLE AGE
my-first-application-cluster 1/1 1 1 1h
[root@master1 ~]# kubectl get pods -n flink-cluster
NAME READY STATUS RESTARTS AGE
my-first-application-cluster-7c4d9d7994-6vwjr 1/1 Running 0 1h
my-first-application-cluster-taskmanager-1-1 1/1 Running 0 461h
这样,就表示Flink启动成功了。我们看到在k8s上有2个pod,分别是jobmanger和taskmanger,一个service用于端口映射。
Part 05 Flink平台k8s改造实践
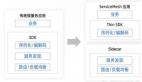
在k8s改造之前,我们已经有了一个Flink计算平台。其主要包含3个部分,web ui用于用户提交SQL任务或者JAR任务,web服务端用于解析SQL或者JAR,然后生成Flink Client提交命令,最后执行命令提交任务到集群上去。

如上图所示,我们的平台已经有Yarn和Standalone模式提交。那么支持云原生,只需要在原先基础上增加一个native k8s提交方式即可。在代码层面就是在提交任务抽象类上增加一个native k8s的实现。
下图为具体的一个native k8s SQL任务提交页面。只需要设置运行模式、运行参数和依赖的第三方jar包,再加上具体的SQL脚本即可完成一个Flink任务的提交。

文献来源
[1]Flink官网,《Flink Documentation》
[2]Kubernetes官网,《kubernetes Documentation》、
[3]腾讯云开发者社区,《原生的在K8s上运行Flink》
[4]腾讯云开发者社区,《Flink 1.13 在Native k8s的部署实践》
[5]51CTO,《网易游戏 Flink SQL 平台化实践》