视频是一种无处不在的媒体内容源,涉及到人们日常生活的许多方面。越来越多的现实世界的视频应用,如视频字幕、内容分析和视频问答(VideoQA),都依赖于能够将视频内容与文本或自然语言联系起来的模型。
其中,视频问答模型尤其具有挑战性,因为它需要同时掌握语义信息,比如场景中的目标,以及时间信息,比如事物如何移动和互动。这两种信息都必须在拥有特定意图的自然语言问题的背景下进行。 此外,由于视频有许多帧,处理全部的帧来学习时空信息,可能在计算上成本过高。

论文链接:https://arxiv.org/pdf/2208.00934.pdf 为了解决这个问题,在「Video Question Answering with Iterative Video-Text Co-Tokenization」一文中,谷歌和MIT的研究人员介绍了一种视频-文本学习的新方法,称为「迭代共同标记」,能够有效地融合空间、时间和语言信息,用于视频问答的信息处理。

这种方法是多流的,用独立的骨干模型处理不同规模的视频,产生捕捉不同特征的视频表示,例如高空间分辨率或长时间的视频。 模型应用「共同认证」模块,从视频流与文本的融合中学习有效表示。模型计算效率很高,只需67GFLOPs,比以前的方法至少低了50%,同时比其他SOTA的模型有更好的性能。
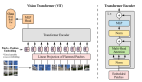
视频-文本迭代
该模型的主要目标是从视频和文本(即用户问题)中产生特征,共同允许它们的相应输入进行互动。第二个目标是以有效的方式做到这一点,这对视频来说非常重要,因为它们包含几十到几百帧的输入。
该模型学会了将视频-语言的联合输入标记为较小的标记集,以联合和有效地代表两种模式。在标记化时,研究人员使用两种模式来产生一个联合的紧凑表示,该表示被送入一个转换层以产生下一级的表示。
这里的一个挑战,也是跨模态学习中的典型问题,就是视频帧往往并不直接对应于相关的文本。研究人员通过增加两个可学习的线性层来解决这个问题,在标记化之前,统一视觉和文本特征维度。这样一来,研究人员就可以让视频和文本都能制约视频标记的学习方式。
此外,单一的标记化步骤不允许两种模式之间的进一步互动。为此,研究人员使用这个新的特征表示与视频输入特征互动,并产生另一组标记化的特征,然后将其送入下一个转化器层。 这个迭代过程中会创建新的特征或标记,表示对两种模式的联合表示的不断完善。最后,这些特征被输入到生成文本输出的解码器中。

按照视频质量评估的惯例,在对个别视频质量评估数据集进行微调之前,研究人员对模型进行预训练。 在这项工作中,研究人员使用基于语音识别的文本自动注释的视频,使用HowTo100M数据集,而不是在大型VideoQA数据集上预训练。这种较弱的预训练数据仍然使研究人员的模型能够学习视频-文本特征。
高效视频问答的实现
研究人员将视频语言迭代共同认证算法应用于三个主要的VideoQA基准,MSRVTT-QA、MSVD-QA和IVQA,并证明这种方法比其他最先进的模型取得了更好的结果,同时模型不至于过大。另外,迭代式共同标记学习在视频-文本学习任务上对算力的需求也更低。

该模型只用67GFLOPS算力,是3D-ResNet视频模型和文本时所需算力(360GFLOP)的六分之一,是X3D模型效率的两倍多。并且生成了高度准确的结果,精度超过了最先进的方法。
多流视频输入
对于VideoQA或其他一些涉及视频输入的任务,研究人员发现,多流输入对于更准确地回答有关空间和时间关系的问题很重要。
研究人员利用三个不同分辨率和帧率的视频流:一个低分辨率、高帧率的输入视频流(每秒32帧,空间分辨率64x64,记作32x64x64);一个高分辨率、低帧率的视频(8x224x224);以及一个介于两者之间的(16x112x112)。
尽管有三个数据流需要处理的信息显然更多,但由于采用了迭代共同标记方法,获得了非常高效的模型。同时,这些额外的数据流允许提取最相关的信息。
例如,如下图所示,与特定活动相关的问题在分辨率较低但帧率较高的视频输入中会产生较高的激活,而与一般活动相关的问题可以从帧数很少的高分辨率输入中得到答案。

这种算法的另一个好处是,标记化会根据所问问题的不同而改变。
结论
研究人员提出了一种新的视频语言学习方法,它侧重于跨视频-文本模式的联合学习。研究人员解决了视频问题回答这一重要而具有挑战性的任务。研究人员的方法既高效又准确,尽管效率更高,但却优于目前最先进的模型。
谷歌研究人员的方法模型规模适度,可以通过更大的模型和数据获得进一步的性能改进。研究人员希望,这项工作能引发视觉语言学习方面的更多研究,以实现与基于视觉的媒体的更多无缝互动。