服装数据集
服装数据集和MNIST数据集很像,有需要的可以查看教程《MNIST数据集》,包含70000个灰度图,每个图片28 x 28像素。

时装数据集
在这里将使用60000张图片进行训练,使用10000张图片进行评估,可以直接使用Keras进行加载。
fashion_mnist = tf.keras.datasets.fashion_mnist(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
所有的图片可分为10个种类:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
数据预处理:
在将数据送入到神经网络训练之前,需要对数据进行预处理,查看一张训练的图片,像素值的分布范围为[0, 255]
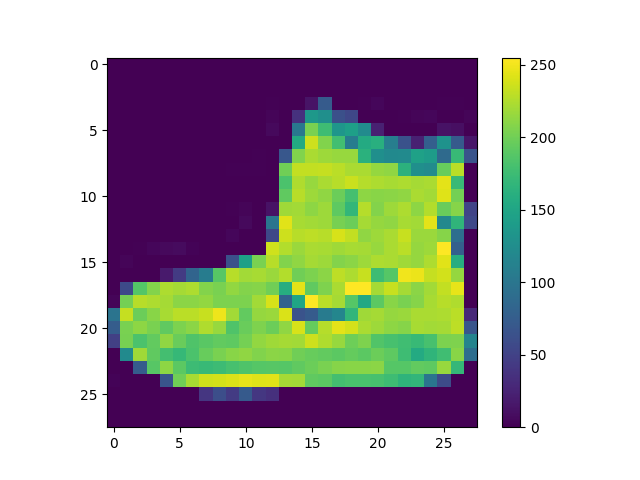
鞋子
对数据进行归一化处理:
train_images = train_images / 255.0test_images = test_images / 255.0
为了验证数据的正确性,展示前25张图片以及图片的分类:

服装
建立模型
神经网络基础模块就是层(Layer),层会从传递的数据中提取特征,这些特征对问题的解决很有帮助。
很多深度学习都是由一系列简单的层串联而成,大部分的层比如Dense,在训练过程中有可学习的参数。
model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10)])
Flatten层将二维(28 x 28)的图片转化为一维的数组,这一层没有参数可以学习,仅仅只是格式化数据。
第一个Dense层有128个节点或者说神经元,第二个Dense层返回长度为10的数组,每个节点包含当前图片属于哪个分类的得分。
模型编译
模型需要进行三个设置:
- 损失函数 - 这个主要用于评估模型在训练过程中的准确性
- 优化器 - 模型如何更新
- 量度 - 用于监测训练和测试步骤
model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
填入训练数据:
model.fit(train_images, train_labels, epochs=10)
评估模型的正确性:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)print('Test accuracy:', test_acc)
显示结果:
Test accuracy: 0.8835999965667725
训练过程输出:
1875/1875 [==============================] - 1s 523us/step - loss: 0.2379 - accuracy: 0.9110
可以看到测试数据的正确性是要略低于训练数据的正确性的,这个训练和测试的差距叫做overfitting(过拟合),过拟合发生在机器学习模型对于没有处理过的数据表现更差。
预测
模型训练之后,你可以使用它来对一些图片进行预测,添加一个Softmax层将结果转换为置信度,它更容易被理解
predictions = probability_model.predict(test_images)print(predictions[0])
可以看到第0张测试图片属于每个分类的置信度:
[4.7003473e-07 2.8711662e-09 1.8403462e-08 3.7643213e-09 2.0236126e-08 8.2177273e-04 1.0194674e-06 9.5114678e-02 2.8414237e-07 9.0406173e-01]
第9个数据的置信度最高,通过打印图片的标签也是9,说明预测正确。
随机选择一些图片输出:
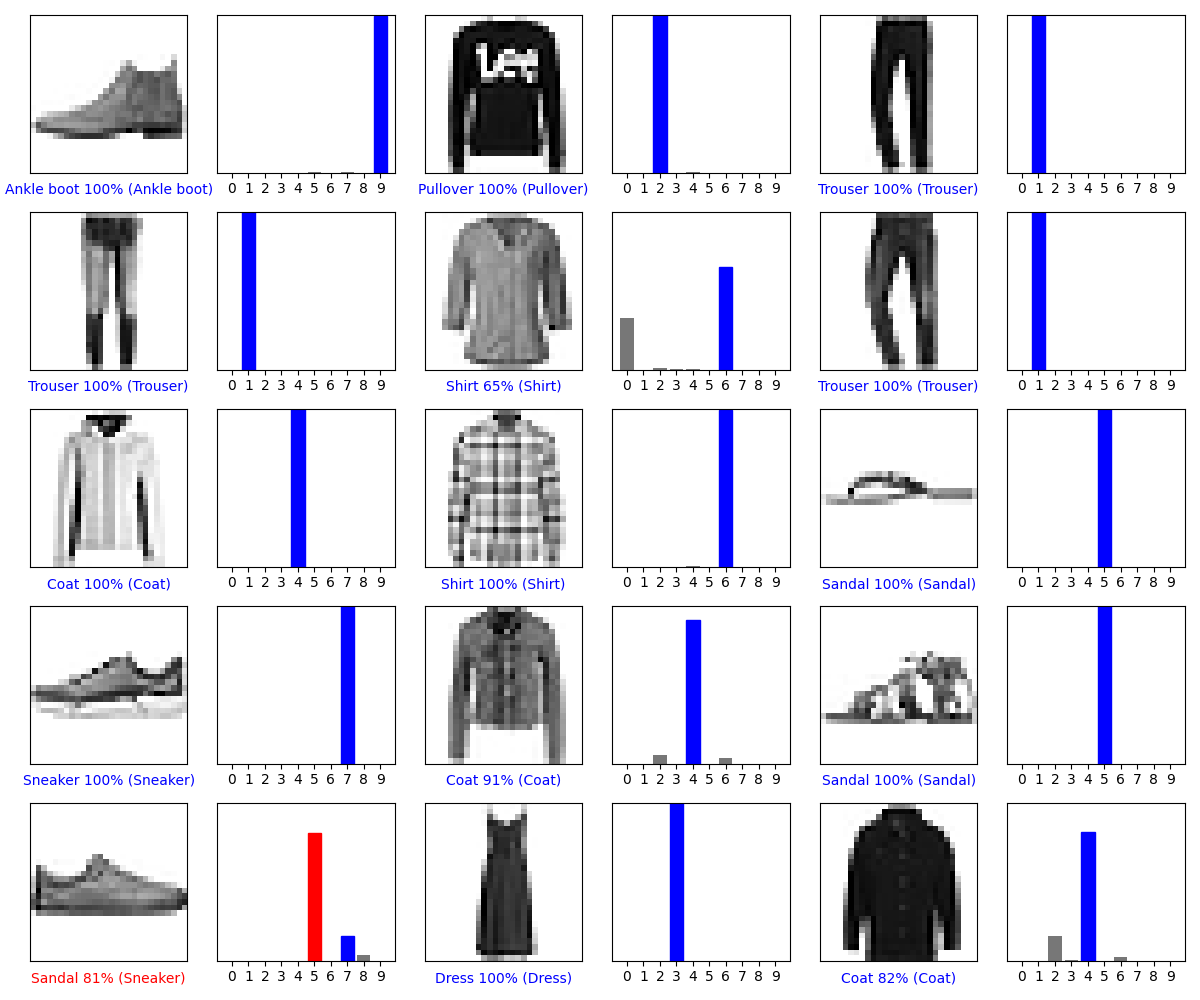
置信度分布
第13张图片81%的可能性是凉鞋,说明机器学习预测错误,它应该是跑鞋。
也可以对单张图片进行预测,虽然是单张图片,但是Keras仍然需要数组进行传递,将图片添加到集合中。
img = (np.expand_dims(img, 0))
进行预测:
predictions_single = probability_model.predict(img)
总结
以上就是建立神经网络的简单过程,分为数据处理、模型的训练、预测等几个步骤。