一、背景
在大数据时代,规范地进行数据资产管理已成为推动互联网、大数据、人工智能和实体经济深度融合的必要条件。贴近业务属性、兼顾研发各阶段要点的研发规范,可以切实提高研发效率,保障数据研发工作有条不紊地运作。而不完善的研发流程,会降低研发效率,增加成本与风险。
数据研发规范旨在为广大数据研发者、管理者提供规范化的研发流程指导方法,目的是简化、规范日常工作流程,提高工作效率,减少无效与冗余工作,赋能企业、政府更强大的数据掌控力来应对海量增长的业务数据,从而释放更多人力与财力专注于业务创新。
二、数据开发流程
鉴于对日常数据仓库研发工作的总结与归纳,将数据仓库研发流程抽象为如下几点:
需求阶段:数据产品经理应如何应对不断变化的业务需求。
设计阶段:数据产品经理、数据开发者应如何综合性能、成本、效率、质量等因素,更好地组织与存储数据。
开发阶段:数据研发者如何高效、规范地进行编码工作。
测试阶段:测试人员应如何准确地暴露代码问题与项目风险,提升产出质量。
发布阶段:如何将具备发布条件的程序平稳地发布到线上稳定产出。
运维阶段:运维人员应如何保障数据产出的时效性和稳定性。
具体开发流程
- 需求:与运营产品讨论需求。业务方把需求提交到JIRA,并且和产品沟通过。
- PRD评审:产品评审PRD文档。
- 技术方案讨论:最好是负责人先沟通一个初级的方案,然后找大家一起讨论(可能比直接头脑风暴效率搞,根据负责人的经验来讨论);然后找大家一起讨论。
- 技术设计评审:设计评审叫上测试。
- 设计评审的原则是,评审会议应该是设计方案大家基本认同的前提下,做方案的文档。
- 设计接口:重点准确描述输入和输出。
- 设计字段:根据需求定义字段,并确定字段指标和获取来源,建立数据字典。
- 开发:开分支,写代码。做好测试case的建立,然后自测。
- 代码review:叫上测试和一个其他开发同学,给出review的结果。目的是让其他同学帮忙review其中的逻辑。
- 提测:给出提测报告,包括罗列测试点。
- 上线:提前告知运维,提前申请机器资源,根据业务预估好CPU、存储、带宽等资源。
- 文档:开发完成后,文档记录一下流程以及提供数据表字段说明,方便重构。
数据需求流程
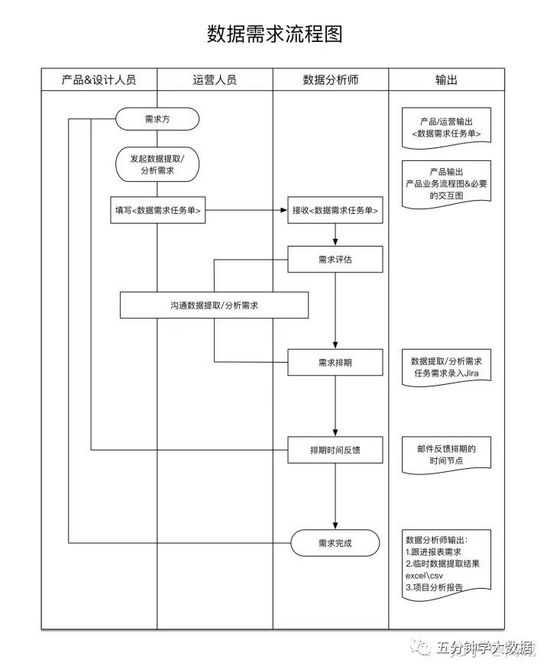
各个角色职责

这个流程针对的是项目是开发,在项目立项的开始,就需要明确各个角色的职责,而且需要和多个角色进行配合。作为数据开发人员,需要协调和各个角色之间的交互:
- 需要和产品评估该需求的合理性,现有技术栈能否支持该需求,例如:公司想要做个实时数据大盘,如果没有实时数仓的架构,是没法完成这块需求。一旦确定开发,需要协调资源,包含开发资源、设备资源等等。
- 需要和业务方、产品方评估数据可行性,数据开发的数据源并不是凭空出现的,需要和业务方明确已有数据能否支撑需求开发,如果缺少数据,则需要另行规划缺失数据的抽取方案。
- 需要自己评估技术可行性,数据开发可能涉及到数据传输、数据同步、ETL、实时开发、离线开发等等,要评估从数据源获取到数据展现一套流程的可行性,例如:数据源如果为多个地方产出,可能需要从binlong获取、Kafka读取、业务库同步、HDFS读取等等,数据输出也可能到各个地方,例如:mysql、hive、ES、Kafka、redis等等多个存储,需要在开发之前确定整套数据的流程。
- 需要确定是否满足安全与合规要求,对于一些敏感数据如何处理,是一个很重要的组成部分,作为数据开发人员,可能接触的数据比较多,但是哪些数据可以展现、哪些数据脱敏后可以展现、哪些数据不能落地等等,而且在数据流转过程中,也要关注数据的安全性,能否落地、能否转存等等。
- 需要和测试同学同步数据处理逻辑,并将一些逻辑的SQL进行文档化,方便测试同学进行单元测试,在交付测试之前,需要对代码进行自测,以便保障流入到测试执行环节的代码达到一定的质量标准。同时最好能让代码通过配置在不同环境进行切换,方便测试同学在测试环境、预发环境进行测试,测试通过后同一套代码能够直接上线。
三、日常数据支撑
除了项目式的开发外,数据开发人员大部分情况下都会面对产品提出来的一些临时性的数据需求,例如拉去一下近半年的销售情况、用户访问情况等等,这部分数据支撑不需要后端配合、可能也不需要进行测试,而是在已明确的数据指标的基础上,定期或者不定期的提供一个数据报表。这部分的数据开发模式相对来说比较简单和快速,但是也需要明确:
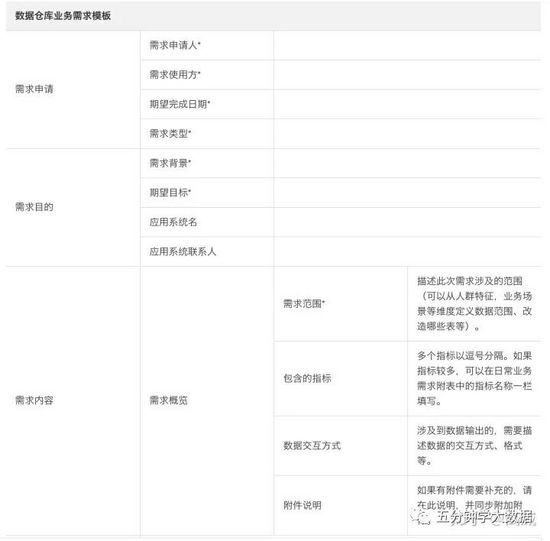
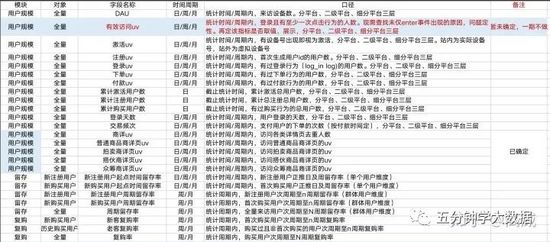
- 明确数据需求模板、常规需求申请单等等,提供需求单的目的是避免长时间的沟通,特别是已经有的数据指标,只需要让产品提供一份详细的数据需求单,按照需求单的模版进行提供数据即可。模版如下:
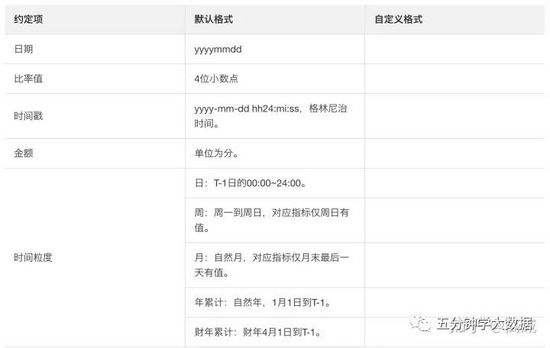
指标需求中通常会涉及到下表中的约定项,如果需要自定义约定项,可以在自定义格式列进行填写。
- 明确需求的指标含义,和所需求的字段明细、统计周期、开发周期等。
四、注意
- 需求评审完成后,如果发生需求变更或者迭代, 一 定需要提供迭代/变更的需求申请单 ,或者提供JIRA,避免需求不可追溯。

- 对于一些重要指标的定义,就算文档中写了,也要和产品进行确定,例如产品需要近半年的所有销量,那么要明确这个销量是否包含退款、是按照成交时间还是付款时间来计算等等。避免数据指标不匹配,导致二次开发。
- 开发过程中,文档要规范,先设计在开发,而且在做系统建设的时候,要有全局视野,不局限某一个点,并不是发布完成了,就算结束,代码开发完成只是第一步,后续的文档建设、代码复盘、数据监控、数据告警、稳定性等等,都需要在开始规划好。
- 及时反馈,在开发过程,不论进行到哪个阶段,项目期间每天都需要和前后端同步一下进度,避免延期的风险。
- 故障处理,在程序上下后,可能会因为客观或者代码的原因出现一些BUG,不同的故障处理方案不同,但是注意复盘和故障记录,避免下次出现相同的BUG。
故障等级定义:
P0:
1.全局问题,影响所有用户,例如系统必现崩溃,主要功能不可用,严重影响用户正常交易。
2.涉及到用户资金损失的问题。
解决时间:2小时内。
反馈时间:0.5小时。
反馈方式:comments自动邮件方式+即时通信:例如QQ\微信\钉钉\电话
P1:
1.全局问题,影响所有用户,例如系统次要功能不可用,系统偶现崩溃且崩溃率超过50%。
2.局部问题,影响超过20%的用户,例如系统主要功能不可用,系统必现崩溃。解决时间:待定不过夜。
反馈时间:1小时。
反馈方式:comments自动邮件方式+即时通信:例如QQ\微信\钉钉\电话
P2:
1.局部问题,影响用户10%-20%,例如系统次要功能不可用,或者系统某一个逻辑不可用,系统崩溃率20-50%。
解决时间:待定48小时。
反馈方式:comments自动邮件方式。
P3:
1.局部问题,影响用户10%以下,例如系统次要功能不可用,系统部分逻辑不正常,仅在某一单一机型或单一用户出现的问题。
解决时间:待定下个版本发布。
反馈方式:下个版本的需求计划中体现。
P4:
1.系统文本错误,系统样式错误,系统交互友好性等不影响用户正常使用的功能。(包含全局性质)
解决时间:下个版本上线时。
反馈方式:下个版本的需求计划中体现。
P0\P1级别问题在规定时间内无法解决的,需要该问题的研发同学在问题comments内说明无法在规定时间内解决的合理的解释,并告知该问题具体的解决时间点同时邮件说明。
五、数据监控与告警
背景
监控系统的一般套路:采集->存储->展示->告警。
监控系统对于大数据平台的重要性不言而喻,一般是对大数据整个架构、各个数据的输入输出流、中间件的稳定性、数据的准确性、资源的使用情况、任务的执行情况进行监控。一般的监控告警通过采集告警日志、错误数据、关键词匹配等获取错误的数据进行实时展现并告警。
常见的监控系统以 Grafana 为基础,主要功能是将收集存储的数据按照不同维度、不同应用、不同用户进行配置化的展示;为了保证数据安全,每个团队只能看到自己的应用数据。同时对不同维度的数据,可以进行报警配置,根据最常用的报警方式,提供了钉钉报警、邮件报警、webhook报警三种方式。
不过最近在使用Flink的时候有一个业务场景,需要对历史数据进行监控,方便查看各个实时任务的表是否有数据产生。所以提供一个python脚本版的监控各个业务表的数据,并做钉钉告警的功能。
介绍
在做实时数据开发过程中,由于对接了不同的业务方,起了多个实时任务的程序,而数据的监控在运维那边,但运维同学只有针对整个集群的监控,对单个作业的监控还没建立起来,所以会初选一些实时任务在集群上runing的状态,但是对Kafka的消费却丢失,而Kafka目前只保留7天的数据,一旦数据丢失,需要通过离线任务去校验,会非常的耗时。
所以在这个背景上,单独做了针对自己输出的业务报表数据的监控,每天输出一些数据产生异常的表,并钉钉告警,方便快速处理。
整体的架构图如下:
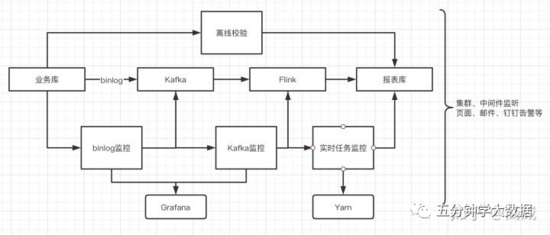
如果业务没有离线校验的情况下,如何去监控数据表是否产生。

例如以钉钉告警为例:
1、建立钉钉机器人
钉钉开发文档:https://open.dingtalk.com/document/org/application-types
2、完成安全设置后,复制出机器人的Webhook地址,可用于向这个群发送消息,格式如下:
https://oapi.dingtalk.com/robot/send?access_token=XXXXXX
同时指定全设置,一般选择关键词,例如:监控报警等,这个机器人所发送的消息,必须包含监控报警 这个词,才能发送成功。建立成功后显示:

3、编写监控数据库表的脚本:
# coding=utf-8
import datetime
import sys
import os
import requests
import json
import pymysql
class test_monitor():
def __init__(self):
self.database='warehouse'
self.host='localhost'
self.username='test'
self.password='123456'
self.table_list = [
{
"table_name": "ods_tgc_scu_index_online",
"ds": "date_create"
},
{
"table_name": "mid_jx_order_detail_online_result",
"ds": "created_at"
}
]
def get_data(self,table_name,ds_time):
try:
db = pymysql.connect(self.host, self.username, self.password, self.database, charset='utf8')
cursor = db.cursor()
yesterday = (datetime.datetime.now() - datetime.timedelta(days=1)).strftime("%Y-%m-%d")
today = datetime.datetime.now().strftime("%Y-%m-%d")
sql = 'select count(1) from '+ table_name + ' where ' + ds_time + ' >= %s and '+ ds_time + ' < %s'
cursor.execute(sql,(yesterday,today))
data = cursor.fetchone()
if(data[0] > 0):
num = data[0]
return num
else:
num = 0
return num
cursor.close()
db.close()
except pymysql.InternalError as error:
code, message = error.args
print(">>>>>>>>>>>>>", code, message)
return -1
def push_data(self,table_name,result):
day = (datetime.datetime.now() - datetime.timedelta(days=1)).strftime("%Y-%m-%d")
db = pymysql.connect(self.host, self.username, self.password, self.database, charset='utf8')
cursor = db.cursor()
sql = 'INSERT INTO souche_enable_market_monitor (datab,table_name,num,ds) value (%s,%s,%s,%s)'
cursor.execute(sql,(self.database,table_name,result,day))
db.commit()
cursor.close()
db.close()
def run(self):
def dingmessage(self):
webhook = "https://oapi.dingtalk.com/robot/send?access_token=XXXXXXXXX"
header = {
"Content-Type": "application/json",
"Charset": "UTF-8"
}
message = {
"msgtype": "text",
"text": {
"content":self
},
"at": {
"atMobiles": [ #此处为需要@什么人。填写具体用户
"此处为需要@什么人。填写具体用户",
],
"isAtAll": True #此处为是否@所有人 True 所有人 False 无需所有人
}
}
message_json = json.dumps(message)
info = requests.post(url=webhook,data=message_json,headers=header)
print('发送成功')
print(info.json())
day = (datetime.datetime.now() - datetime.timedelta(days=1)).strftime("%Y-%m-%d")
for table in self.table_list:
table_name = table['table_name']
ds_time = table['ds']
result = self.get_data(table_name,ds_time)
self.push_data(table_name,result)
dingmessage('监控报警:\n'+day+'\n'+table_name+"数据量为:"+str(result))
if __name__ == '__main__':
test_monitor().run()
4、任务结果和监控

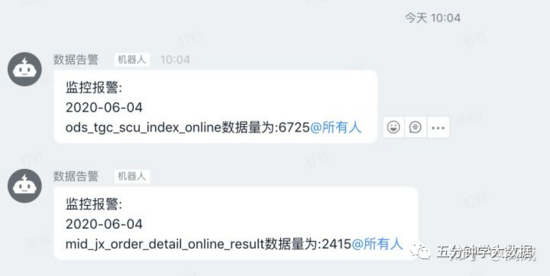
这样就可以每天看到昨天的数据是否产生,也可以设置阀值,将没达到阀值的表输出告警,然后方便去排查原因和恢复。
优化
上面的脚本是需要将配置文件写到脚本里面的,如果设计到的业务比较多,那么需要很多人同时修改这个脚本,没法做到数据安全的问题,所以下一步准备将这个配置文件生成一张表,每个人可以通过数据库insert的操作去添加自己需要监控的表。而且除了钉钉告警还可以发邮件。
例如:
Mysql数据条数的检测
- 目的:每天早上检查配置表中各条记录是否大于等于阈值,每天一条的,阈值写1即可。
- 结果:将不超过阀值的数据钉钉告警
1、表结构设计
CREATE TABLE `warehouse.dj_rpt_check_conf` (
`db` varchar(8) NOT NULL COMMENT '数据库别名,例如bi,online,warehouse结果库)' ,
`tbl` varchar(64) NOT NULL COMMENT '表名',
`condition` varchar(256) NOT NULL COMMENT '筛选条件',
`threshold` bigint(20) NOT NULL DEFAULT 0 COMMENT '阈值',
`owner` varchar(16) NOT NULL default 'nobody' COMMENT '负责人:每个人自己固定用一个名字',
`ptype` varchar(8) NOT NULL COMMENT '检查周期,例如:d(天),w(周,周一),m(月,1号)',
unique index tbl_db (tbl,db)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4;
插入数据:
insert into dj_rpt_check_conf values ('bi','dj_share_category_di','stat_date="${ds}"',20,'dy','d');
2、监控脚本
# coding: utf-8
from djtool import *
import pandas as pd
import sqlalchemy as sq
from sqlalchemy import exc
import sys
import requests
import json
import copy
owner_mobile={'gw':'123456789'}
def check_table(conn,table,condition,threshold):
try:
cursor = conn.cursor()
check_sql= 'select count(1) from ' + table + ' where ' + condition
cursor.execute(check_sql)
data = cursor.fetchone()
if(data[0]<threshold):
return data[0]
else:
return None
except pymysql.InternalError as error:
code, message = error.args
print(">>>>>>>>>>>>>", code, message)
return -1
ds= sys.argv[1]
check_conf = pd.read_sql_table('dj_rpt_check_conf',get_sqlalchemy_conn('mysql','bg'))
check_conf['condition'] = check_conf.condition.str.replace('\$\{ds\}',ds)
check_conf['real_cnt'] = 0
check_conf['failed'] = 0
for db in check_conf.db.unique():
db_conn=get_pymysql_conn("mysql_"+db)
for index,row in check_conf[(check_conf.db==db) & (check_conf.ptype=='d')].iterrows():
real_cnt = check_table(db_conn,row['tbl'],row['condition'],row['threshold'])
if(real_cnt is not None):
check_conf.loc[index,'real_cnt']=real_cnt
check_conf.loc[index,'failed']=1
mail_text = '''
配置表:`warehouse.dj_rpt_check_conf`
'''
fail_conf = check_conf[(check_conf.failed==1)]
if(fail_conf.shape[0]>0):
send_mail(['data@idongjia.cn'],[],ds+'--BI任务失败列表',mail_text + fail_conf.to_html())
else:
send_mail(['data@idongjia.cn'],[],ds+'--已经加入监控的BI任务完成:)',mail_text)
headers = {'Content-Type': 'application/json'}
ding_url = 'https://oapi.dingtalk.com/robot/send?access_token=xxxxxxx'
msg={
"msgtype": "markdown",
"markdown": {"title":"BI任务失败了:"+ds,
"text":"#### BI任务失败了:"+ds+" \n @mobile 失败任务:\n- fail_task "
},
"at": {
"atMobiles": [
"88888"
]
}
}
for owner in fail_conf.owner.unique():
tmp_msg = copy.deepcopy(msg)
tmp_msg['at']['atMobiles']=[owner_mobile[owner]]
tmp_msg['markdown']['text']=tmp_msg['markdown']['text'].replace('mobile',owner_mobile[owner])
tmp_msg['markdown']['text']=tmp_msg['markdown']['text'].replace('fail_task',"\n- ".join(fail_conf[(fail_conf.owner==owner)].tbl.values.tolist()))
requests.post(ding_url, headers=headers,data=json.dumps(tmp_msg))
3、处理钉钉发邮件,可以通过自定义的方式发送邮件
# -*- coding: UTF-8 -*-
import smtplib
import sys
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import Header
from email.utils import formataddr
from sys import argv
def main():
sender = 'test'
receivers = ['gaowei@test.cn']
password = 'xxxxxxxx'
message = MIMEMultipart()
message['From'] = formataddr(["数据组",sender])
message['To'] = formataddr(["数据组成员",receivers])
subject = 'rest'
message['Subject'] = Header(subject, 'utf-8')
message.attach(MIMEText(sys.argv[1]+'数据见附件\n', 'plain', 'utf-8'))
att1 = MIMEText(open("aa.csv", 'rb').read(), 'base64', 'utf-8')
att1["Content-Type"] = 'application/octet-stream'
att1["Content-Disposition"] = 'attachment; '+'filename='+sys.argv[1]+'.csv'
message.attach(att1)
try:
server=smtplib.SMTP_SSL("smtp.exmail.qq.com", 465)
server.login(sender, password)
server.sendmail(sender,receivers,message.as_string())
print "邮件发送成功"
except smtplib.SMTPException:
print "Error: 无法发送邮件"
if __name__ == '__main__':
main()
不过这个执行过程,需要将要发的文本先下载到本地,然后才能发送,所以一般的执行脚本如下:
export JAVA_HOME=/opt/jdk1.8.0_121
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin:{JRE_HOME}/bin:$PATH
export PATH=$PATH:/opt/mysql/bin
dateStrDay=$1
if [ -z "$1" ] ; then
dateStrDay=`date +%Y-%m-%d`
fi
echo $dateStrDay
dateStr=`date +%Y-%m-%d-%M-%S`
hadoop fs -rm -r /tmp/gaowei/test
cd /opt/task/gaowei/warehouse/test
rm *.csv
spark2-submit --class cn.idongjia.data.auction.AuctionOrder --master yarn --deploy-mode cluster /opt/task/gaowei/warehouse/test/datawarehouse_2.11-1.0.jar
hadoop fs -getmerge /tmp/gaowei/test/* /opt/task/gaowei/warehouse/test/bb.csv
sed '1i\用户id,拍卖订单数,跑单数,异常订单数,是否禁言禁拍(0表示否,1表示是),是否在白名单(0表示否,1表示是),是否屏蔽(0表示否,1表示是,时间)' /opt/task/gaowei/warehouse/test/bb.csv > /opt/task/gaowei/warehouse/test/aa.csv
python Email.py ${dateStrDay}
扩展
除了python发邮件,Scala和Java也可以直接发邮件,代码如下:
package spark_tmp.utils
import java.io.File
import com.typesafe.config.ConfigFactory
import org.apache.spark.rdd.RDD
import play.api.libs.mailer._
object TaskSendMail {
/**
* 定义一个发邮件的人
* @param host STMP服务地址
* @param port STMP服务端口号
* @param user STMP服务用户邮箱
* @param password STMP服务邮箱密码
* @param timeout setSocketTomeout 默认: 60s
* @param connectionTimeout setSocketConnectionTimeout 默认:60s
* @return 返回一个可以发邮件的用户
*/
def createMailer(host:String, port: Int, user: String, password: String, timeout:Int = 10000, connectionTimeout:Int = 10000):SMTPMailer ={
// STMP服务SMTPConfiguration
val configuration = new SMTPConfiguration(
host, port, false, false, false,
Option(user), Option(password), false, timeout = Option(timeout),
connectionTimeout = Option(connectionTimeout), ConfigFactory.empty(), false
)
val mailer: SMTPMailer = new SMTPMailer(configuration)
mailer
}
/**
* 生成一封邮件
* @param subject 邮件主题
* @param from 邮件发送地址
* @param to 邮件接收地址
* @param bodyText 邮件内容
* @param bodyHtml 邮件的超文本内容
* @param charset 字符编码 默认:utf-8
* @param attachments 邮件的附件
* @return 一封邮件
*/
def createEmail(subject:String, from:String, to:Seq[String], bodyText:String = "ok", bodyHtml:String = "", charset:String = "utf-8", attachments:Seq[Attachment] = Seq.empty): Email = {
val email = Email(subject, from, to,
bodyText = Option[String](bodyText), bodyHtml = Option[String](bodyHtml),
charset= Option[String](charset),attachments = attachments
)
}
/**
* 生成一个附件
* @param name 附件的名字
* @param fileStr 以本地文件为附件相关参数
* @param rdd 以hdfs文件或rdd或df为附件相关参数
* @return
*/
def createAttachments(name: String, fileStr: String = "", rdd:RDD[String] = null): Attachment = {
var attachment: Attachment = null
if(fileStr.contains(":")){
val file: File = new File(fileStr)
attachment = AttachmentFile(name, file)
}else{
val data: Array[Byte] = rdd.collect().mkString("\n").getBytes()
// 根据文件类型选择MimeTypes对应的值
val mimetype = "text/plain"
attachment = AttachmentData(name, data, mimetype)
}
attachment
}
/**
* 主要针对日常简单结果的快速发送
* @param subject 邮件主题名字
* @param toStr 邮件的接收人,多名以,分割
* @param bodyText 邮件的内容
* @return 用户设备 <510109769.1.1561635225728@RAN>
*/
def dailyEmail(subject:String, toStr:String, bodyText: String):String={
val to = toStr.split(",").toList
// 阿里云企业 邮箱
val host = "smtp.189.cn"
val port = 25
val user = "18968044961@189.cn"
val password = "xxxxxxxxxx"
val from = user
val mailer: SMTPMailer = TaskSendMail.createMailer(host, port, user, password)
val email: Email = TaskSendMail.createEmail(subject, from, to, bodyText = bodyText)
val userdev: String = mailer.send(email)
userdev
}
}