













一、前奏
Hadoop是目前大数据领域最主流的一套技术体系,包含了多种技术。
包括HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统),等等。
有些朋友可能听说过Hadoop,但是却不太清楚他到底是个什么东西,这篇文章就用大白话给各位阐述一下。
假如你现在公司里的数据都是放在MySQL里的,那么就全部放在一台数据库服务器上,我们就假设这台服务器的磁盘空间有2T吧,大家先看下面这张图。
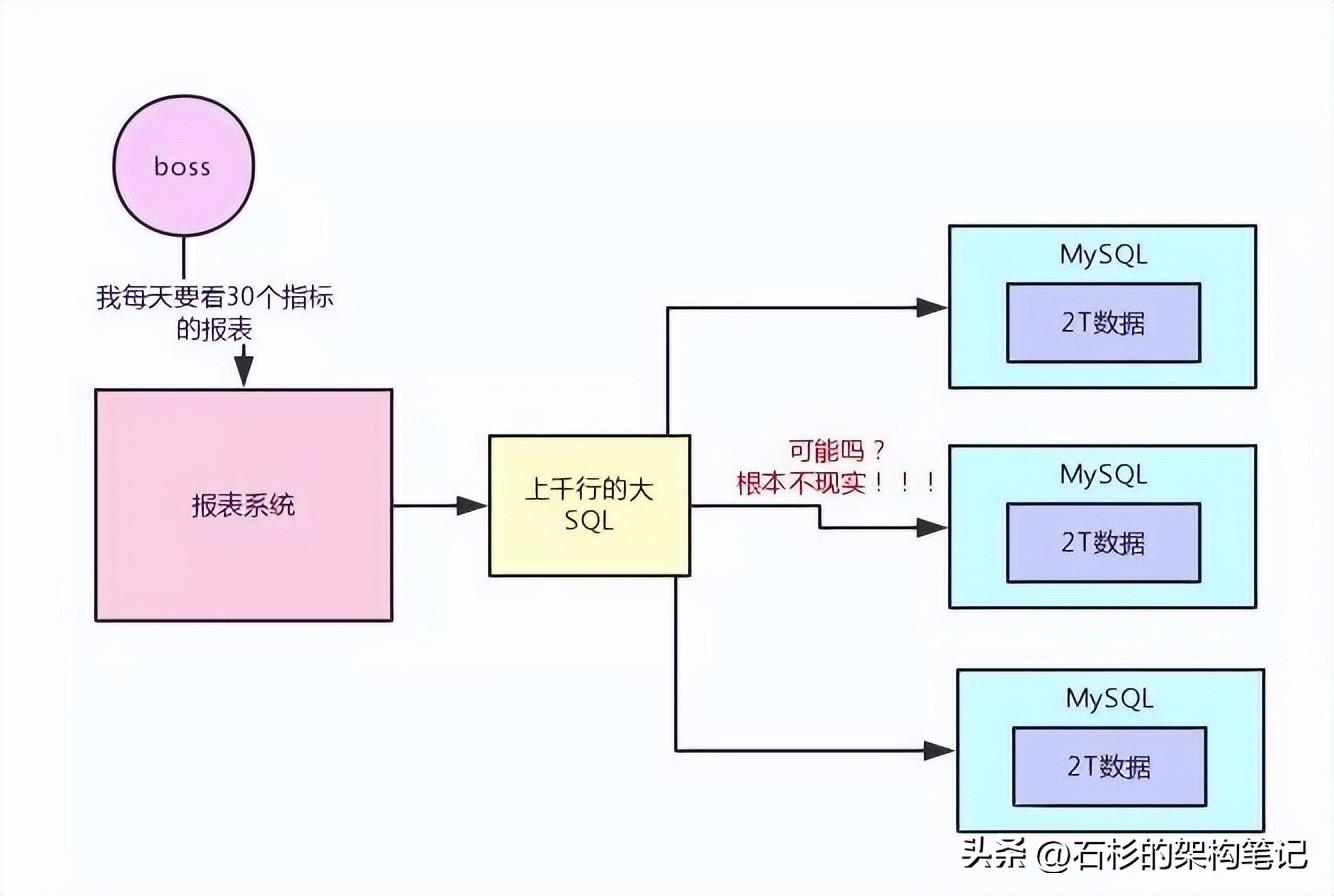
现在问题来了,你不停的往这台服务器的MySQL里放数据,结果数据量越来越大了,超过了2T的大小了,现在咋办?
你说,我可以搞多台MySQL数据库服务器,分库分表啊!每台服务器放一部分数据不就得了。如上图所示!
好,没问题,那咱们搞3台数据库服务器,3个MySQL实例,然后每台服务器都可以2T的数据。
现在我问你一个问题,所谓的大数据是在干什么?
我们来说一下大数据最初级的一个使用场景。假设你有一个电商网站,现在要把这个电商网站里所有的用户在页面和APP上的点击、购买、浏览的行为日志都存放起来分析。
你现在把这些数据全都放在了3台MySQL服务器,数据量很大,但还是勉强可以放的下。
某天早上,你的boss来了。要看一张报表,比如要看每天网站的X指标、Y指标、Z指标,等等,二三十个数据指标。
好了,兄弟,现在你尝试去从那些点击、购买、浏览的日志里,通过写一个SQL来分析出那二三十个指标试试看?
我跟你打赌,你绝对会写出来一个几百行起步,甚至上千行的超级复杂大SQL。这个SQL,你觉得他能运行在分库分表后的3台MySQL服务器上么?
如果你觉得可以的话,那你一定是不太了解MySQL分库分表后有多坑,几百行的大SQL跨库join,各种复杂的计算,根本不现实。
所以说,大数据的存储和计算压根儿不是靠MySQL来搞的,因此,Hadoop、Spark等大数据技术体系才应运而生。
本质上,Hadoop、Spark等大数据技术,其实就是一系列的分布式系统。
比如hadoop中的HDFS,就是大数据技术体系中的核心基石,负责分布式存储数据,这是啥意思?别急,继续往下看。
HDFS全称是Hadoop Distributed File System,是Hadoop的分布式文件系统。
它由很多机器组成,每台机器上运行一个DataNode进程,负责管理一部分数据。
然后有一台机器上运行了NameNode进程,NameNode大致可以认为是负责管理整个HDFS集群的这么一个进程,他里面存储了HDFS集群的所有元数据。
然后有很多台机器,每台机器存储一部分数据!好,HDFS现在可以很好的存储和管理大量的数据了。
这时候你肯定会有疑问:MySQL服务器也不是这样的吗?你要是这样想,那就大错特错了。
这个事情不是你想的那么简单的,HDFS天然就是分布式的技术,所以你上传大量数据,存储数据,管理数据,天然就可以用HDFS来做。
如果你硬要基于MySQL分库分表这个事儿,会痛苦很多倍,因为MySQL并不是设计为分布式系统架构的,他在分布式数据存储这块缺乏很多数据保障的机制。
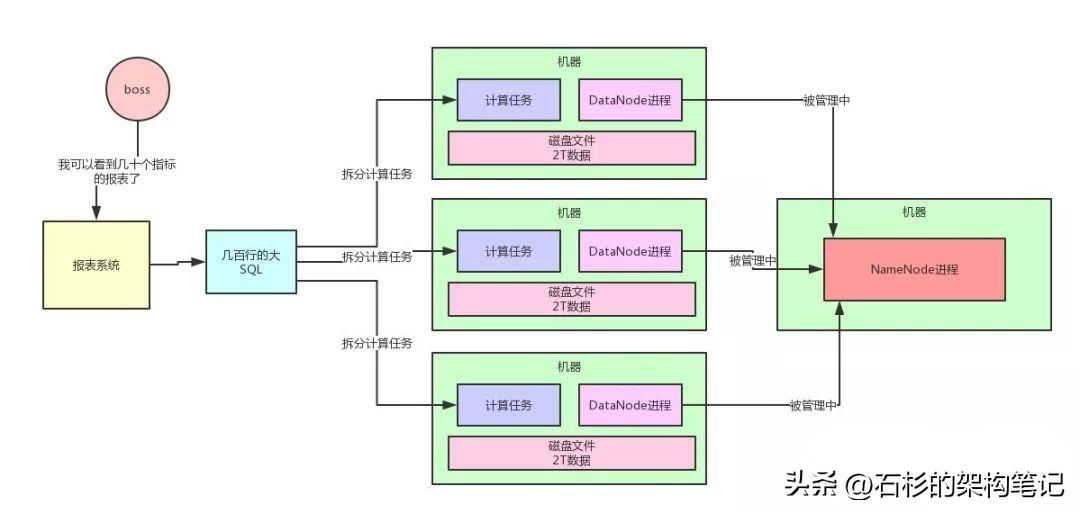
好,你现在用HDFS分布式存储了数据,接着不就是要分布式来计算这些数据了吗?
对于分布式计算:
- 很多公司用Hive写几百行的大SQL(底层基于MapReduce)。
- 也有很多公司开始慢慢的用Spark写几百行的大SQL(底层是Spark Core引擎)。
总之就是写一个大SQL,人家会拆分为很多的计算任务,放到各个机器上去,每个计算任务就负责计算一小部分数据,这就是所谓的分布式计算。
这个,绝对比你针对分库分表的MySQL来跑几百行大SQL要靠谱的多。
对于上述所说的分布式存储与分布式计算,老规矩,同样给大家来一张图,大伙儿跟着图来仔细捋一下整个过程。
二、HDFS的NameNode架构原理
好了,前奏铺垫完之后,进入正题。本文其实主要就是讨论一下HDFS集群中的NameNode的核心架构原理。
NameNode有一个很核心的功能:管理整个HDFS集群的元数据,比如说文件目录树、权限的设置、副本数的设置,等等。
下面就用最典型的文件目录树的维护,来给大家举例说明,我们看看下面的图。现在有一个客户端系统要上传一个1TB的大文件到HDFS集群里。
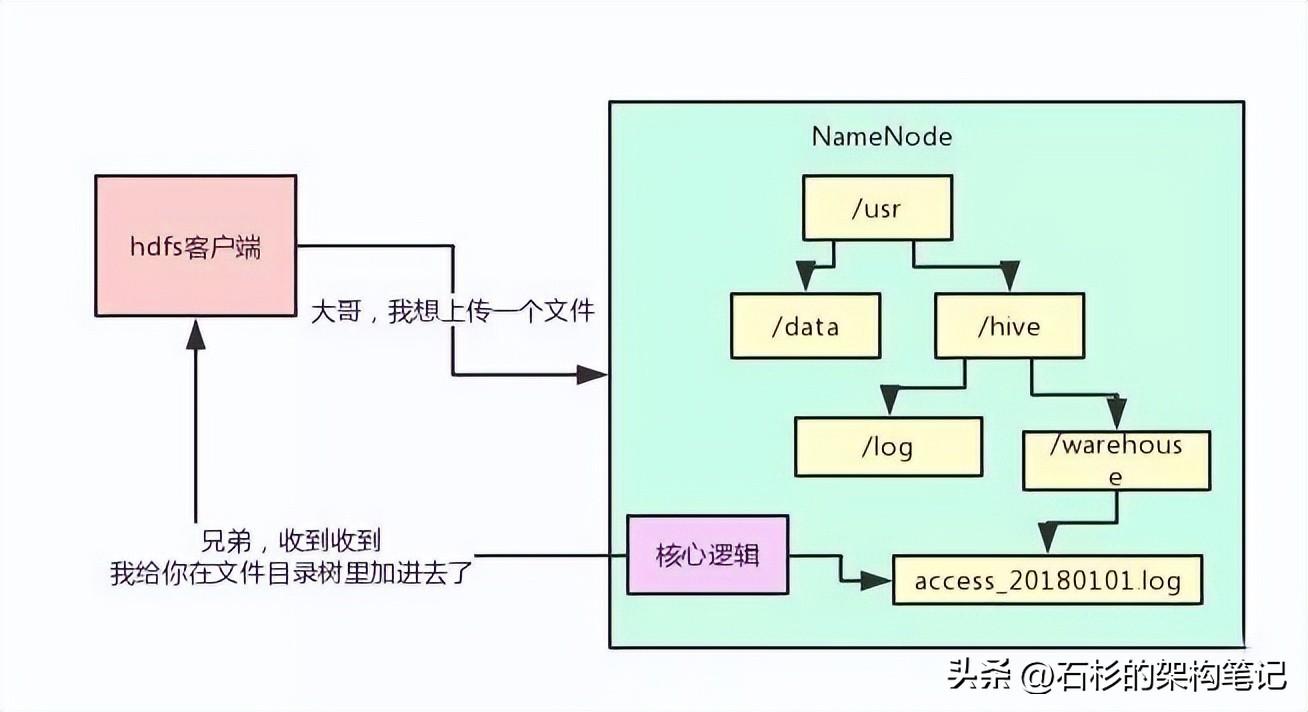
此时他会先跟NameNode通信,说:大哥,我想创建一个新的文件,他的名字叫“
/usr/hive/warehouse/access_20180101.log”,大小是1TB,你看行不?
然后NameNode就会在自己内存的文件目录树里,在指定的目录下搞一个新的文件对象,名字就是“access_20180101.log”。
这个文件目录树不就是HDFS非常核心的一块元数据,维护了HDFS这个分布式文件系统中,有哪些目录,有哪些文件,对不对?
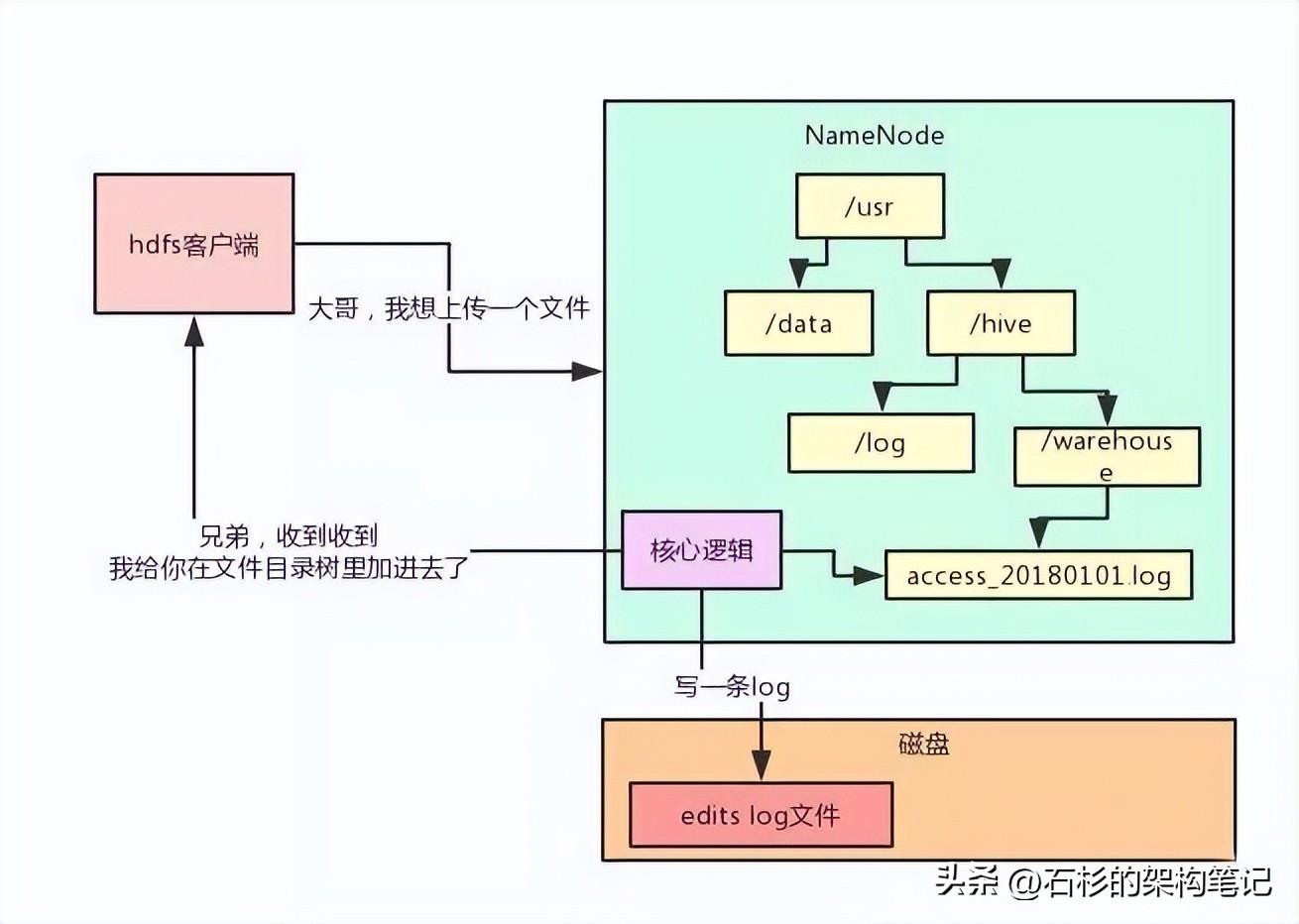
但是有个问题,这个文件目录树是在NameNode的内存里的啊!
这可坑爹了,你把重要的元数据都放在内存里,万一NameNode不小心宕机了可咋整?元数据不就全部丢失了?
可你要是每次都频繁的修改磁盘文件里的元数据,性能肯定是极低的啊!毕竟这是大量的磁盘随机读写!
没关系,我们来看看HDFS优雅的解决方案。
每次内存里改完了,写一条edits log,元数据修改的操作日志到磁盘文件里,不修改磁盘文件内容,就是顺序追加,这个性能就高多了。
每次NameNode重启的时候,把edits log里的操作日志读到内存里回放一下,不就可以恢复元数据了?
大家顺着上面的文字,把整个过程,用下面这张图跟着走一遍。
但是问题又来了,那edits log如果越来越大的话,岂不是每次重启都会很慢?因为要读取大量的edits log回放恢复元数据!
所以HDFS说,我可以这样子啊,我引入一个新的磁盘文件叫做fsimage,然后呢,再引入一个JournalNodes集群,以及一个Standby NameNode(备节点)。
每次Active NameNode(主节点)修改一次元数据都会生成一条edits log,除了写入本地磁盘文件,还会写入JournalNodes集群。
然后Standby NameNode就可以从JournalNodes集群拉取edits log,应用到自己内存的文件目录树里,跟Active NameNode保持一致。
然后每隔一段时间,Standby NameNode都把自己内存里的文件目录树写一份到磁盘上的fsimage,这可不是日志,这是完整的一份元数据。这个操作就是所谓的checkpoint检查点操作。
然后把这个fsimage上传到到Active NameNode,接着清空掉Active NameNode的旧的edits log文件,这里可能都有100万行修改日志了!
然后Active NameNode继续接收修改元数据的请求,再写入edits log,写了一小会儿,这里可能就几十行修改日志而已!
如果说此时,Active NameNode重启了,bingo!没关系,只要把Standby NameNode传过来的fsimage直接读到内存里,这个fsimage直接就是元数据,不需要做任何额外操作,纯读取,效率很高!
然后把新的edits log里少量的几十行的修改日志回放到内存里就ok了!
这个过程的启动速度就快的多了!因为不需要回放大量上百万行的edits log来恢复元数据了!如下图所示。
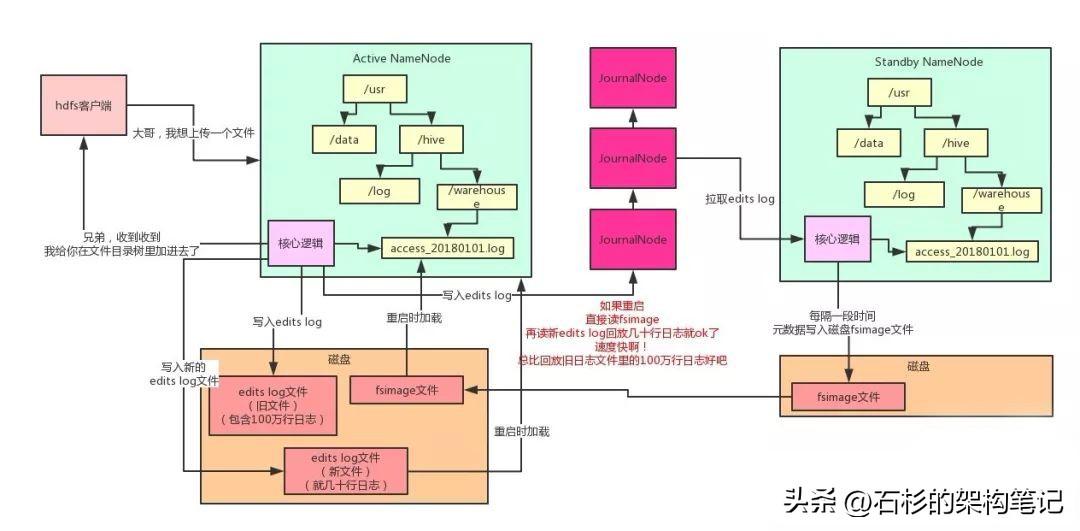
此外,大家看看上面这张图,现在咱们有俩NameNode。
- 一个是主节点对外提供服务接收请求
- 另外一个纯就是接收和同步主节点的edits log以及执行定期checkpoint的备节点。
大家有没有发现!他们俩内存里的元数据几乎是一模一样的啊!
所以呢,如果Active NameNode挂了,是不是可以立马切换成Standby NameNode对外提供服务?
这不就是所谓的NameNode主备高可用故障转移机制么!
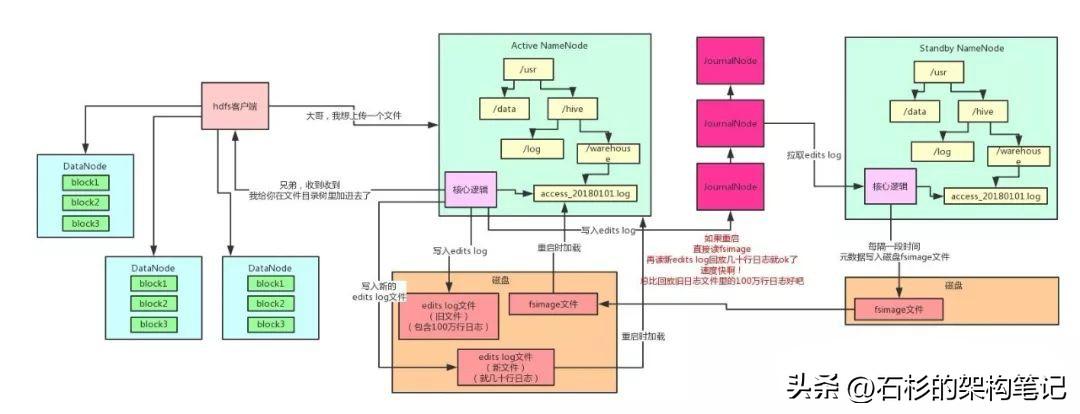
接下来大家再想想,HDFS客户端在NameNode内存里的文件目录树,新加了一个文件。
但是这个时候,人家要把数据上传到多台DataNode机器上去啊,这可是一个1TB的大文件!咋传呢?
很简单,把1TB的大文件拆成N个block,每个block是128MB。1TB = 1024GB = 1048576MB,一个block是128MB,那么就是对应着8192个block。
这些block会分布在不同的机器上管理着,比如说一共有100台机器组成的集群,那么每台机器上放80个左右的block就ok了。
但是问题又来了,那如果这个时候1台机器宕机了,不就导致80个block丢失了?
也就是说上传上去的1TB的大文件,会丢失一小部分数据啊。没关系!HDFS都考虑好了!
它会默认给每个block搞3个副本,一模一样的副本,分放在不同的机器上,如果一台机器宕机了,同一个block还有另外两个副本在其他机器上呢!
大伙儿看看下面这张图。每个block都在不同的机器上有3个副本,任何一台机器宕机都没事!还可以从其他的机器上拿到那个block。
这下子,你往HDFS上传一个1TB的大文件,可以高枕无忧了吧!
OK,上面就是大白话加上一系列手绘图,给大家先聊聊小白都能听懂的Hadoop的基本架构原理
接下来会给大家聊聊HDFS,这个作为世界上最优秀的分布式存储系统,承载高并发请求、高性能文件上传的一些核心机制以及原理。

















