Flink和Strom都是时下较为流行的数据流平台,考虑以下一种应用场景:已经使用Strom完成了对于某一逻辑功能的开发,如果现在期望使用Flink实现相同的逻辑,那么就需要考虑如何使用Flink来对Strom任务的逻辑功能进行最简单的复现测试。

使用Flink来测试Strom任务的逻辑主要存在两个最基本的问题:第一,Storm通过自定义的Bolt类实现自定义的逻辑,在Flink中如何实现?第二,Storm按照自定义标准实现数据分发的逻辑,在Flink中如何实现?
本文主要通过两个最基本的Flink程序实例对上述两个使用Flink测试Strom任务逻辑存在的基本问题进行解答。
第一个问题,我们可以通过Flink的ProcessFuction类进行实现,通过继承该类,在该类的processElement方法中实现自定义逻辑。ProcessFuction类如下图所示,我们可以通过var1这个参数直接获取当前流中的数据,然后进行自定义的逻辑加工,再通过Collector类var3的collect方法将处理后的数据发送到下一个流中。

假设某一Strom任务的功能逻辑是:① 对初始数据源(一个字符串)末尾添加一个字符串。② 然后再次添加另一个字符串。
我们以上述对字符串加工的Strom任务为例,说明Flink程序如何通过ProcessFuction类对该任务实现复现测试。
(1)Flink主程序,假设初始数据源为“abc”。

(2)第一个业务加工类,给数据流末尾添加“def”。

(3)第二个业务加工类,给数据流末尾添加“ghi”。

(4)执行Flink程序,观察输出结果,“abc”被二次加工为“abcdefghi”。

第二个分发数据的问题,我们假设某一Strom任务的功能逻辑是对数据源(股票对象)进行分类,将股价高于X的分为一类,将股价小于等于X的分为另一类。
我们以上述对股票数据对象分类处理的Strom任务为例,说明Flink程序如何通过旁路输出特性实现对数据流按照自定义标准分类,输出到不同的子数据流中处理。
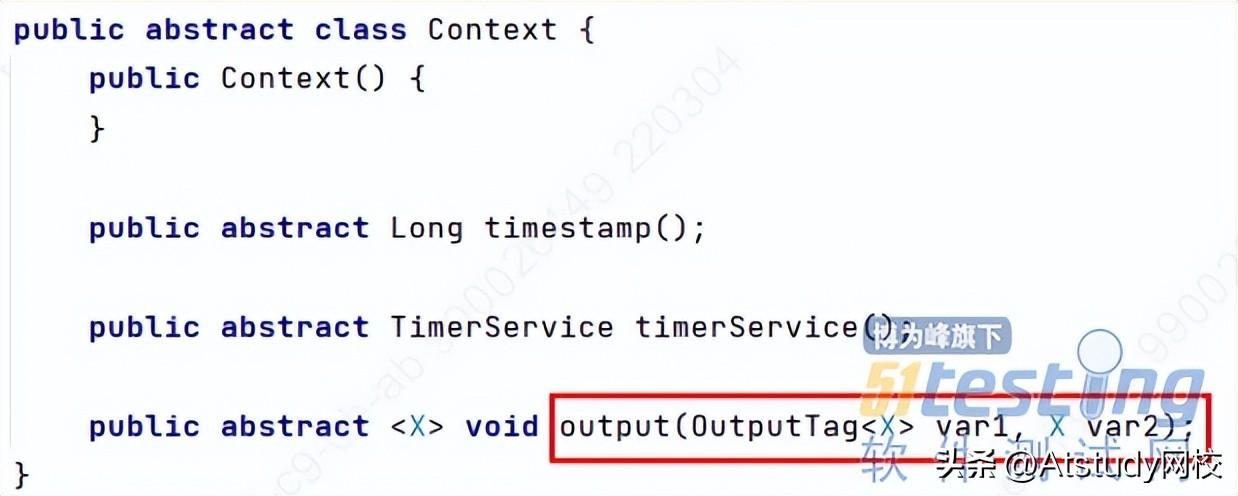
Flink 的旁路输出依然涉及ProcessFunction类的processElement方法,该方法的Context类型的var2参数的主要作用是利用其output方法进行旁路输出(我们用于进行数据分流)。
Flink的旁路输出特性可以用来对数据进行分流,通过创建一个流的标签(OutputTag),再利用这个OutputTag标签对象作为参数,调用初始/父级数据流的getSideOutput(OutputTag)方法获取子数据流。
每个流标签都有一个id,也可以不创建对象,只要流标签的id相同,其中的数据就相同。因此,可以通过匿名内部类的形式来获取子数据流。第一个参数是id,第二个参数是数据类型(不能省略)。
(1)创建股票类Stock,属性包括名称和价格。

(2)创建消费消息的Flink程序。

(3)创建生产消息的Flink程序。

我们用“STOCK_LOW_PRICE”和“STOCK_HIGH_PRICE”这两个ID作为两个旁路输出标签的ID。
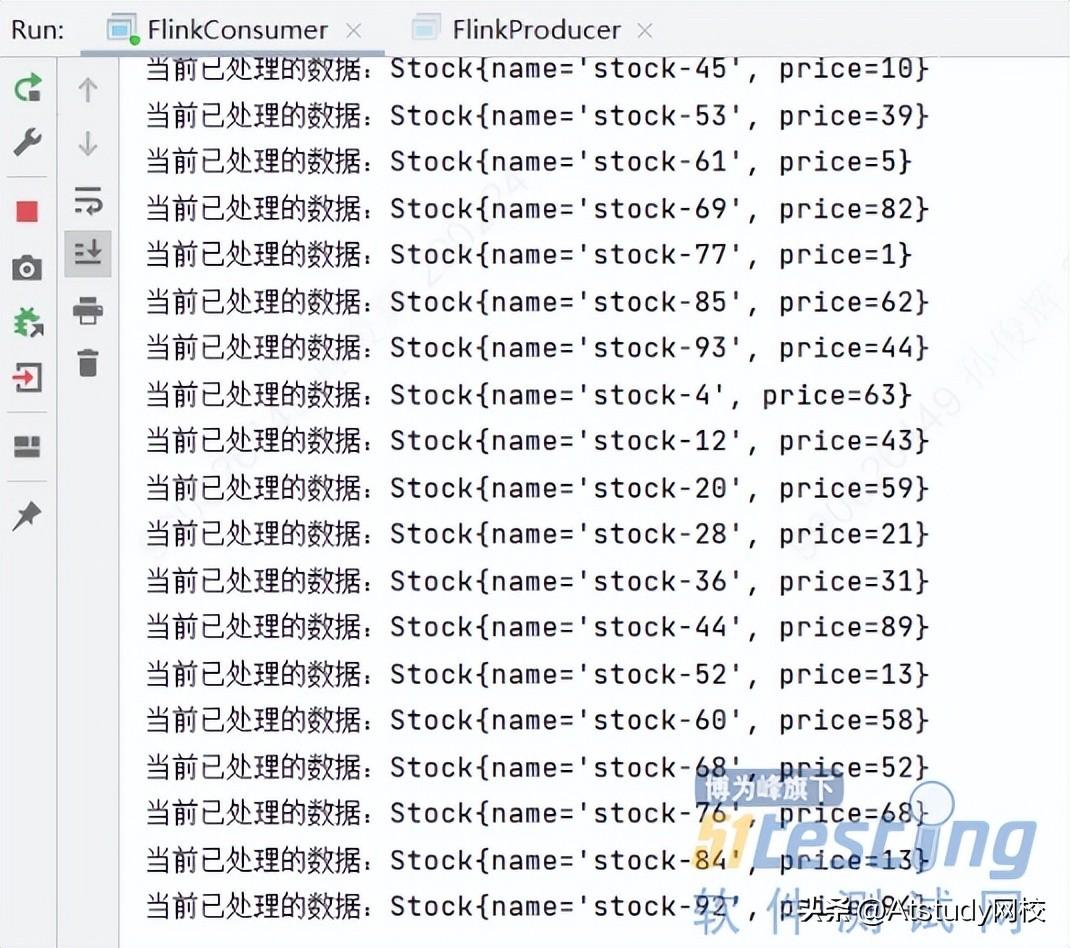
在processElement方法中,我们通过判断股票的价格是否大于50区分出低价股和高价股,利用Context对象的output方法进行旁路输出,把price小于50的Stock对象输出到ID为“STOCK_LOW_PRICE”的低价股标签旁路中,而把price大于等于50的Stock对象输出到ID为“STOCK_HIGH_PRICE”的高价股标签旁路中。

(4)依次启动消费者程序、生产者程序,观察消费者程序控制台中的输出:
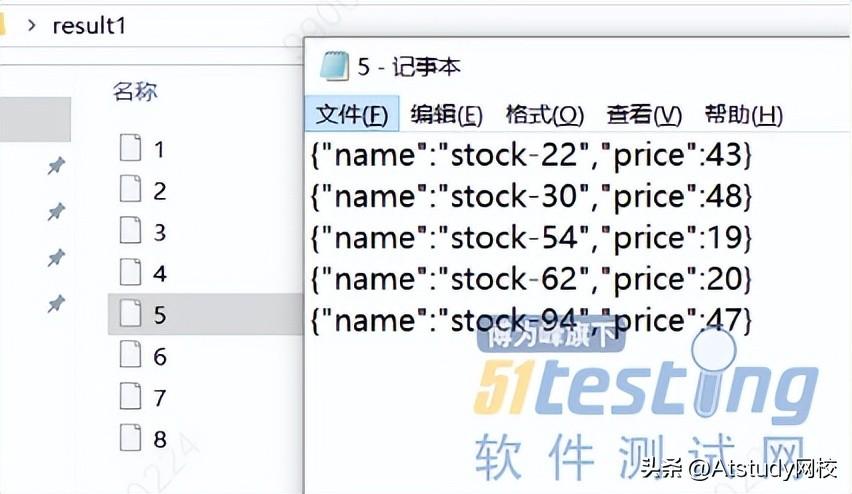
此时,桌面生成了两个文件夹,当中记录了股票数据,result1记录了小于50的低价股,result2中记录了股价大于等于50的高价股。