














一、前情提示
上一篇文章《高并发+海量数据下如何实现系统解耦?【上】》,给大家初步讲述了一套大规模复杂系统中,两个核心子系统之间一旦耦合,会发生哪些令人崩溃的场景。如果还没看上篇文章的,建议先看一下。
这篇文章,咱们就给大家来说一说通过MQ消息中间件的使用,如何重构系统之间的耦合,让系统具备高度的可扩展性。
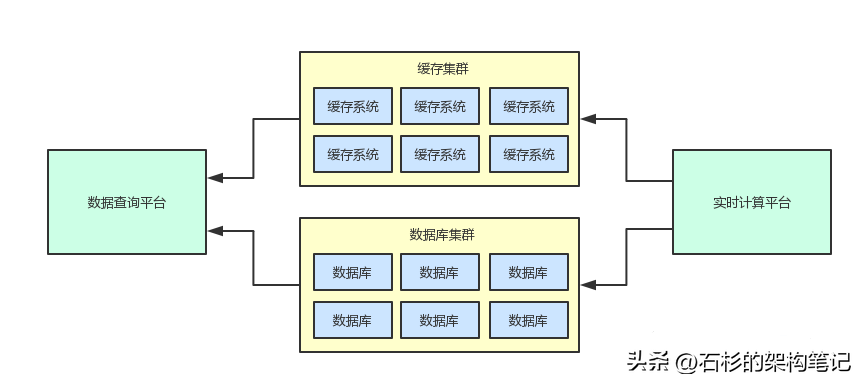
首先来回看一下之前画的一张两个系统之间进行耦合的一个大图,从这个图里我们可以看到两个系统完全通过一套共享存储(数据库集群+缓存集群)进行了耦合。
二、清晰的划分系统边界
只要有耦合,一旦要解决耦合,那么第一个要干的事儿就是先划分清楚系统之间的边界。
比如上面那两套系统都共享了一套存储集群,那么大家可以先思考一下,两个系统之间的边界应该如何划分?也就是说,中间那套缓存集群和数据库集群,到底应该是属于哪个系统?
首先我们看一下,缓存集群和数据库集群主要是给谁用的?
很明显就是给数据查询平台用的,说白了,那两套集群都是数据查询平台赖以生存的核心底层数据存储,这里存储的数据也都是属于数据查询平台的核心数据。
对于实时计算平台来说,他只不过是将自己计算后的结果写入到缓存集群和数据库集群罢了。
实时计算平台只要写入过后,后续就不会再管那些数据了,所以这两套集群明显是不属于实时计算平台的。
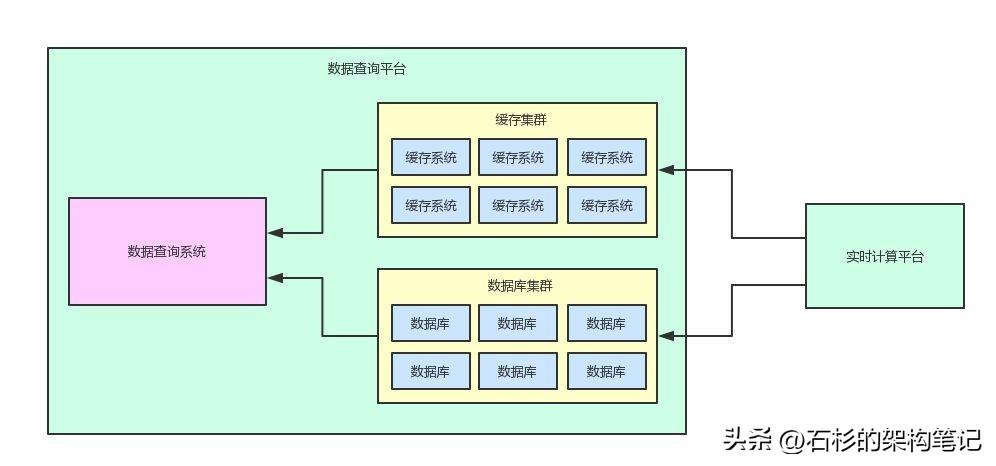
好,那么系统之间的边界就很清晰的划分清楚了,大家看一下如下的图。首先从系统整体架构的架构而言,两套系统之间的关系应该是下面这样子的。
三、引入消息中间件解耦
只要划分清楚了系统之间的边界,接着下一步,就是引入消息中间件来进行解耦了。
如果大家对消息中间件的使用场景还不太熟悉的,可以参考之前的一篇文章:哥们,你们的系统架构中为什么要引入消息中间件?这篇文章里面,对消息中间件的各种使用场景都有说明。
我们只要引入一个消息中间件,然后让实时计算平台将计算好的数据按照预设的格式直接写入到消息中间件即可。
同时,数据查询平台需要增加一个数据接入服务,这个数据接入服务就是负责将消息中间件里的数据消费出来,然后落地写入到本地的缓存集群和数据库集群。
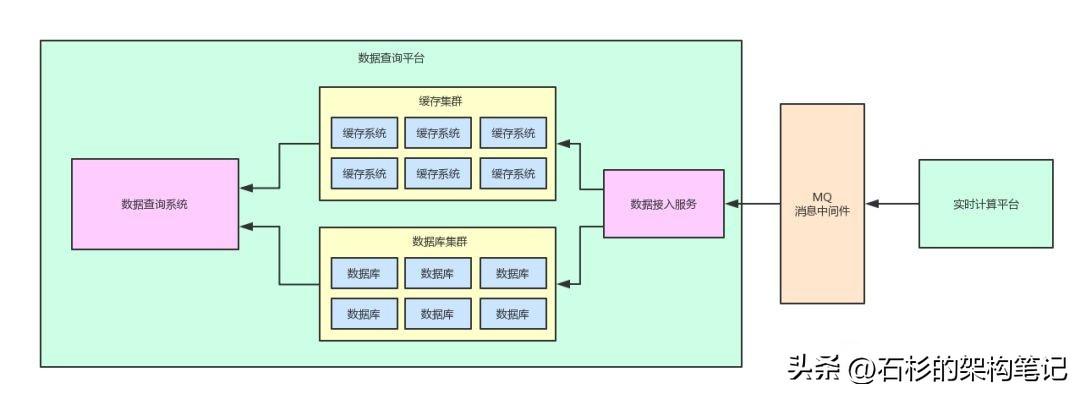
如上图所示,此时两个系统之间已经不再直接基于共享数据存储进行耦合了,中间加入了MQ消息中间件。
这个消息中间件仅仅就是用于两个系统之间的数据交互和传输,职责简单,清晰明了。
这样做最大的好处,就是数据查询平台自身可以对涌入自身平台的数据按照自己的需求进行定制化的管控了,不会像之前那样的被动。
实际上在上述架构之下,涌入数据查询平台的所有数据,都需要经过数据接入服务那一关。在数据接入服务那里就可以随意根据自己的情况进行管理。
四、利用消息中间件削峰填谷
还记得上一篇文章我们提到,这两个系统之间第一个大痛点,就是实时计算平台会高并发写入数据查询平台,之前不做任何管控的时候,导致各种意外发生。
举个例子,比如快速增长的写库压力导致数据查询平台必须优先cover住分库分表那块的架构,打破自己的架构演进节奏;
比如突然意外出现的热数据因为不做任何写入管控,一下子差点把数据库服务器击垮。
因此一旦用消息中间件在中间挡了一层之后,我们就可以进行削峰填谷了。
那什么叫做削峰填谷呢?其实很简单,我们先来看看,如果不做任何管控,实时计算平台写入数据库集群的写并发曲线图,大概如下面所示。
在高峰期,写入会有一个陡然上升的尖峰。
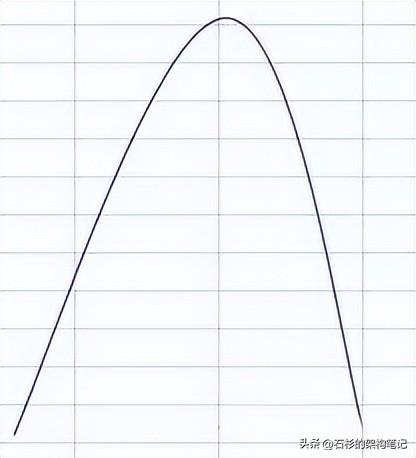
就好比说,平时每秒写入并发就500,但是高峰期写入并发请求有5000,那么大家就会看到上面的那张图,在高峰期突然冒出来一个尖峰,一下子涌入并发5000请求,此时数据查询平台的数据库集群可能就会受不了。
但是,如果我们在数据接入服务里做一个限流控制呢?
也就是说,在数据接入服务里,根据当前数据查询平台的数据库集群能承载的并发上限,比如说就是最多承载每秒3000。
好!那么数据接入服务自己就控制好,每秒最多就往自己本地的数据库集群里写入最多每秒3000的请求压力。
此时就会出现削峰填谷的效果,大家看下面的图。

因为在高峰期瞬时写入压力最大有5000/s,但是数据接入服务做了流量控制,最多就往本地数据库集群写入3000/s,那么每秒就会有2000条数据在消息中间件里做一个积压。
但是积压一会儿不要紧,最起码保证说在高峰期,这个向上的尖峰被削平了,这就是所谓的削峰。
然后在高峰期过了之后,本来每秒可能就100/s的写入压力,但是此时数据接入服务会持续不断的从消息中间件里取出来数据然后持续以最大3000/s的写入压力往本地数据库集群里写入。
那么在低峰期,大家看到还会持续一段时间是3000/s的写入速度往本地数据库里写。
原来的图里在低峰期是谷底,现在谷底被填平了,这就是所谓的填谷。
通过这套削峰填谷的机制,就可以保证数据查询平台完全能够以自己接受的了的速率,均匀的把MQ里的数据拿出来写入自己本地数据库集群中。
这样子无论实时计算平台多高的并发请求压力过来,哪怕是那种异常的热数据,瞬间上万并发请求过来也无所谓了。
因为MQ中间件可以抗住瞬间高并发写入,但是数据查询平台永远都是稳定匀速的写入自己本地数据库。
这样的话,数据查询平台就不需要去过多的care实时计算平台带给自己的压力了,可以按照自己的节奏规划好整体架构的演进策略,按照自己的脚本去迭代架构。
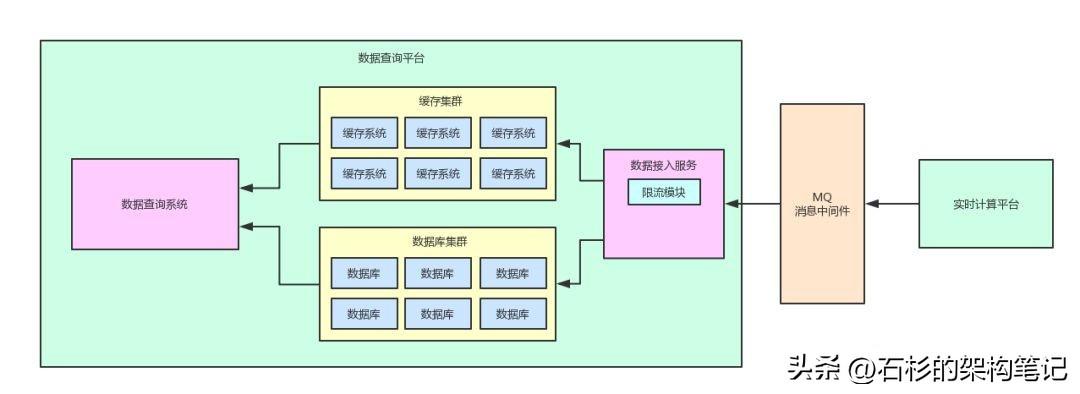
说了那么多,老规矩!给大家来一张图,此时的架构图如下所示。
大伙儿可以直观的感受一下,在数据接入服务中多了一个限流的模块。
五、手动流量开关配合数据库运维操作
现在基于消息中间件将两个系统隔离开来之后,另外一个大的好处就是:数据查询平台做任何数据运维的操作,比如说DDL、分库分表扩容、数据迁移,等等诸如此类的操作,已经跟实时计算平台彻底无关了。
实时计算平台主要就是简单的往消息中间件写入,其他的就不用管了。
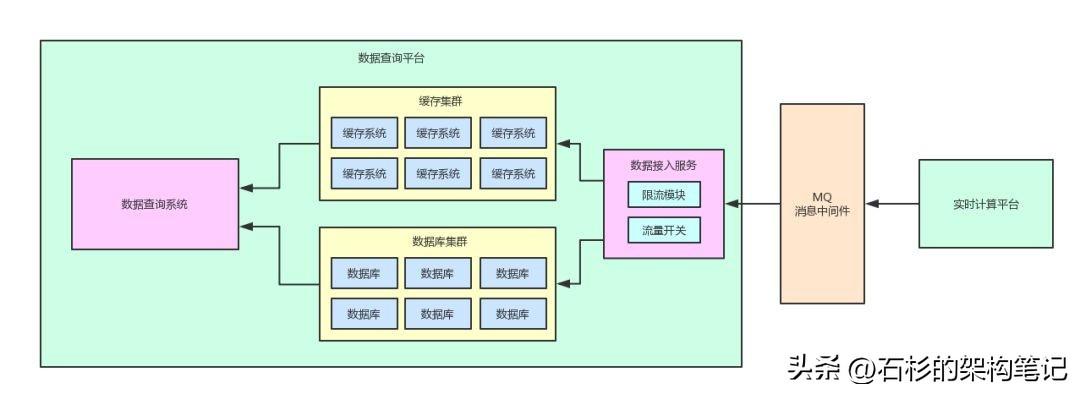
然后如果数据查询平台要做一些数据库运维的操作,此时就可以通过在数据接入服务中加入一个手动流量开关,临时将流量开关关闭一会儿。
比如选择一个下午大家都在工作或者午睡的时候,相对低峰的时期,半小时内关闭流量开关。
然后此时数据接入服务就不会继续往本地数据库写入数据了,此时写入操作就会停止,然后就在半小时内迅速完成数据库运维操作。
等相关操作完成之后,再次打开流量开关,继续从MQ里消费数据再快速写入到本地数据库内即可。
这样,就可以完全避免了同时写入数据,还同时进行数据库运维操作的窘境。否则在早期耦合的状态下,每次进行数据库运维操作,还得实时计算平台团队的同学配合一起进行各种复杂操作,才能避免线上出现故障,现在完全不需要人家的参与了,自己团队就可以搞定。
整个过程,我们还是用一张图,给大家呈现一下:
六、支持多系统同时订阅数据
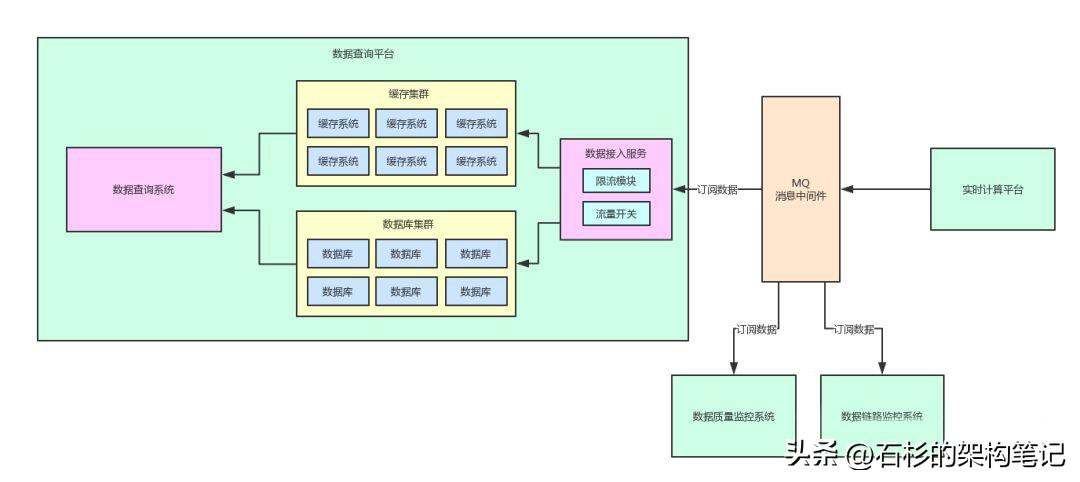
引入消息中间件之后,还有另外一个好处,就是其他的一些系统也可以按照自己的需要去MQ里订阅实时计算平台计算好的数据。
举个例子,在这套平台里,还有数据质量监控系统,需要获取计算数据进行数据结果准确性和质量的监控。
另外,还有数据链路监控系统,同样需要将MQ里的数据作为数据计算链路中的一个核心点数据采集过来,进行数据全链路的监控和自动追踪。
如果没有引入MQ消息中间件概念的话,那么是不是就会导致实时计算平台除了将数据写入一份到数据库集群,还需要通过接口发送给数据质量监控系统?还需要发送给数据链路监控系统?这样简直是坑爹到不行,N个系统全部耦合在一起。
之前的文章《哥们,你们的系统架构中为什么要引入消息中间件?》就阐述了这种多系统订阅同一份数据,但是通过接口调用耦合在一起的窘境。
这样每次要是有一点变动,各个系统的负责人都在一起开会商讨,修改代码,修改接口,考虑各种调用细节,等等。
但是现在有了消息中间件,完全可以通过MQ支持的“Pub/Sub”消息订阅模型,不同的系统都可以来订阅同一份数据,大家自己按需消费,按需处理,各个系统之间完全解耦。
整个系统的可扩展性瞬间提升了很多,因为各个系统各自迭代和演进架构,都不需要强依赖其他的系统了。
七、系统解耦后的感受
云开雾散!各个团队的同学终于不用天天扯皮,今天说你的系统影响了我,明天是我的系统影响了你。
同时也压根儿不用去关注其他的系统,只要有一个总架构师把控好整体架构,各个team都按照这个分工协作来做即可。
消息中间件的引入,消除了系统的耦合性,大幅度提升了系统的可扩展性,各个team都可以快速的独立的迭代扩展自己的架构和系统。


























