最近参与公司项目研发,在其中发现对于数据的管理存在一些小问题,根据以往经验,在这里记录下微服务数据设计模式。
微服务架构中的服务是松耦合的,可以独立开发、部署和扩展。每个微服务都需要不同类型的数据和存储方式,也因为这样每个微服务都有自己的数据库。
一、每个服务的数据库
每个微服务都有自己的数据库,可以自由选择如何管理数据。
1、每个服务都有一个数据库的好处
- 松耦合,各自服务可以更加专注自己的专业领域
- 自由选择数据库类型,如 MySQL 等 RDBMS、Cassandra 等宽列数据库、MongoDB 等文档数据库、Redis 等键值存储和 Neo4J 等图形数据库。
是否需要为每个服务使用不同的数据库服务器?这不是一个硬性要求。让我们看看我们能做些什么。
2、如果您使用的是 RDMS,那么就包括以下特性:
- 专用表—每个服务拥有一组表,只能由该服务访问。
- 专用数据库架构—每个服务都有一个私有的数据库架构。
- 专用数据库服务器—每个服务都有自己的数据库服务器。
3、每个服务都有一个数据库的挑战
需要连接多个数据库的查询 —以下数据模式可以克服这一挑战。
- 事件溯源
- API 组成
- 命令查询职责分离 (CQRS)
跨多个数据库事务 —为了解决这个问题,我们可以使用Saga 模式。
二、事件溯源
通过事件溯源,业务实体的状态由一系列状态变化的事件跟踪。每当业务实体的状态发生变化时,都会将新事件添加到事件列表中。由于保存事件是一个单一的操作,它本质上是原子的。通过重放事件,应用程序重建实体的当前状态。
应用程序将事件保存在事件存储中,事件存储是事件数据库。可以使用其 API 从存储中添加和检索事件。事件存储也充当消息代理。服务可以通过其 API 订阅事件。当服务在事件存储中保存一个事件时,它会发送给所有感兴趣的订阅者。当实体有大量事件时,应用程序可以定期保存实体当前状态的快照以优化加载。应用程序查找最近的快照以及自该快照以来发生的事件以重建当前状态。这减少了要重播的事件的数量。
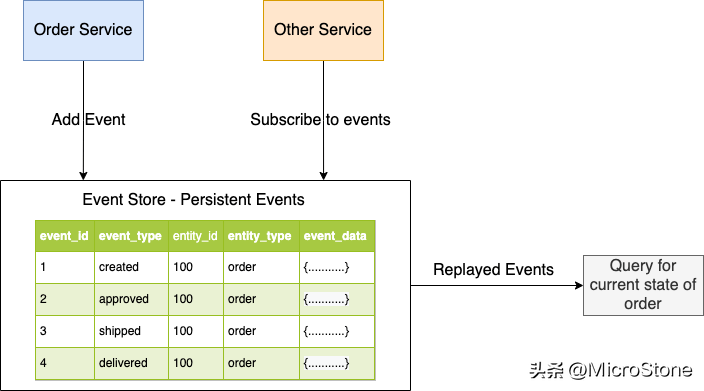
1、事件溯源的好处
- 使用它解决了事件驱动架构的关键挑战之一,并使得在状态变化时可靠地发布事件。
- 避免了对象关系阻抗不匹配问题,持久化事件而不是域对象。
- 对实体提供 100% 可靠的审计日志。
- 允许执行确定实体在任何时间点的状态的时间查询。
- 基于事件溯源的业务逻辑涉及交换事件的松散耦合实体。使从单体应用程序迁移到微服务架构变得容易得多。
2、事件溯源的缺点
- 有一定学习成本,目前还是一种不太成熟的技术。
- 查询事件存储很困难,需要一个典型的查询来重建实体状态。可能会导致低效和复杂的查询。因此,应用程序必须使用命令查询职责分离 (CQRS) 来实现查询。反过来,这意味着应用程序必须处理最终一致的数据。
三、API 组成
您可以使用 API 组合模式实现从多个服务中检索数据的查询操作。在这个模式中,通过调用拥有数据的服务然后组合结果来实现查询操作。
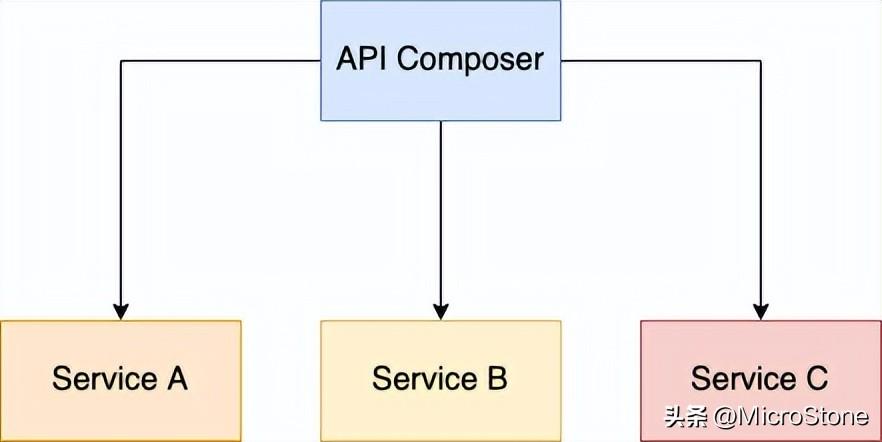
1、API 组合的好处
在微服务架构中查询数据的一种便捷方式。
2、API组合的缺点
有时,查询会导致大型数据集的低效内存连接。
四、命令查询职责分离 (CQRS)
RDBMS 通常用作记录事务系统和文本搜索数据库,例如用于文本搜索查询的 Elasticsearch 或 Solr。一些应用程序通过同时写入两者来保持数据库同步。其他人定期将数据从 RDBMS 复制到文本搜索引擎。基于此架构构建的应用程序利用了多个数据库的优势、RDBMS 的事务属性以及文本数据库的查询能力。CQRS 概括了这种架构。
微服务架构在实现查询时面临三个常见挑战。
- 使用 API 组合模式检索分散在多个服务中的数据,从而导致成本高昂且效率低下的内存连接。
- 数据以不能有效支持拥有数据的服务所需查询的格式或数据库中存储。
- 分离关注点意味着拥有数据的服务不应该负责实现查询操作。
这三个问题都可以通过使用 CQRS 模式来解决。
CQRS 的主要目标是分离或分离关注点。因此,持久数据模型分为两部分:命令端和查询端。
创建、更新和删除操作由命令端模块和数据模型实现。查询由查询端模块和数据模型实现。通过订阅命令行发布的事件,查询端保持其数据模型与命令端同步
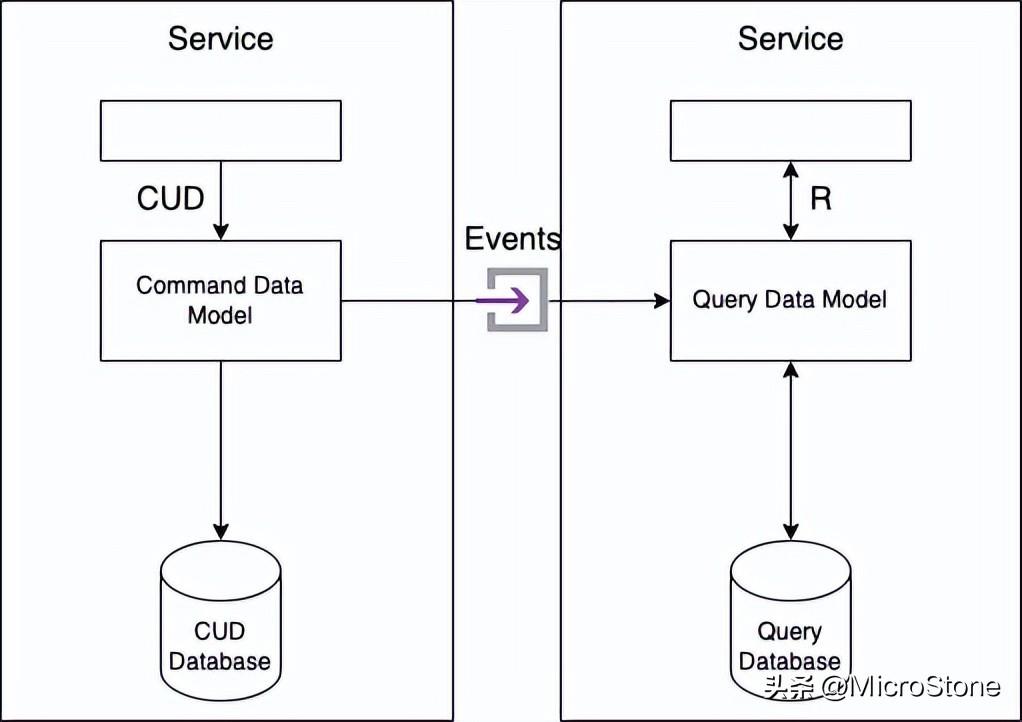
1、CQRS 的好处
- 实现高效查询实现—如果您使用 API 组合模式来实现查询,您可能会遇到大型数据集的高成本、低效的内存连接。对于这些查询,使用预先来自连接两个或更多服务数据的CQRS 视图更有效。
- 能够有效实现多种查询—通常很难使用单一持久数据模型来支持所有查询。在CQRS 中,定义一个或多个视图有效地实现特定查询,消除了单个数据存储的限制。
- 实现基于事件溯源的应用程序中查询—CQRS 还克服了事件溯源的一个重要限制。事件存储仅支持基于主键的查询。CQRS 模式通过定义一个或多个聚合视图来解决此限制,这些视图通过订阅由事件源聚合发布的事件流来保持最新。
- 关注点分离改进—域模型和持久数据模型不支持命令和查询。CQRS 将服务的命令和查询端分离为单独的代码模块和数据库模式。
2、CQRS 的缺点
- 更复杂的架构—为了更新和查询视图,开发者需要编写查询端服务。应用程序可能使用不同类型的数据库,这增加了开发人员和 DevOps 的复杂性。
- 处理复制延迟—在从命令端发布事件到由查询端处理事件以及更新视图之间存在延迟。
五、Saga模式
使用 sagas,您可以在不使用分布式事务的情况下保持微服务架构中数据的一致性。您为跨多个服务更新数据的每个命令定义一个 saga。saga 是一系列本地事务。本地事务使用ACID事务框架更新单个服务中的数据。
Sagas 利用补偿事务来回滚更改。假设saga的第n个交易失败。必须撤消前 (n-1) 个事务。结果,总共 (n-1) 个补偿事务将被启动以以相反的顺序回滚更改。
1、Saga协调
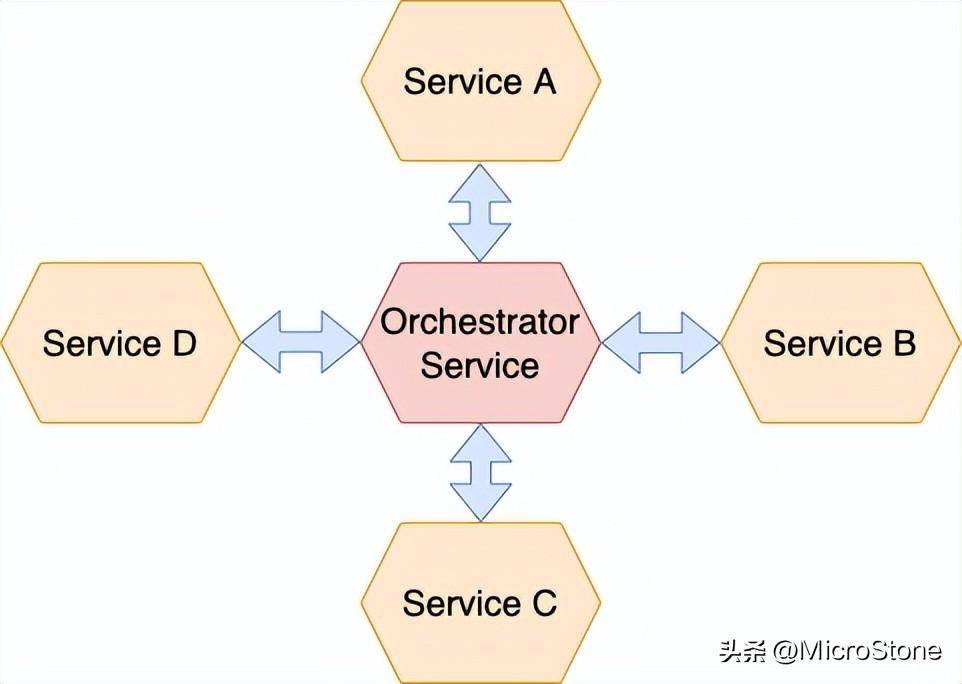
为了实现一个 saga,它需要逻辑来协调其步骤。一旦系统命令启动了一个 saga,协调逻辑必须选择并指示第一个 saga 执行本地事务。一旦该事务完成,编排协调就会选择并调用下一个 saga 参与者。这个过程一直持续到传奇完成。如果本地事务失败,saga 必须以相反的顺序执行补偿事务。
2、有几种方法可以构建 saga 的协调逻辑:
编排 :在saga的参与者之间分配决策和排序。他们主要通过交换事件进行通信。
(1)基于编排的saga优势
- 简单性—当创建、更新或删除业务对象时,服务会发布事件。
- 简单依赖关系—不引入循环依赖关系。
- 松耦合—服务实现由编排器调用的 API,因此它不需要知道 saga 参与者发布的事件。
- 简化业务逻辑—在 saga 编排器中,saga 协调逻辑是本地化的。领域对象不知道它们所涉及的 sagas。
(2)基于编排的缺点
- 更难理解—编排将 saga 的实现分布在服务之间,每个服务都是独立的这就需要每个管理对每个服务都需要了解。
- 服务之间的循环依赖—saga 参与者订阅彼此的事件,这通常会产生循环依赖。
- 紧密耦合的风险—saga的参与者必须订阅所有影响他们的事件。
编排 —一个 saga 的协调逻辑应该集中在一个 saga 编排器类中。在 saga 期间,编排器向参与者发送命令消息,告诉他们应该执行哪些操作。