一、前情回顾
上篇文章(《亿流量大考(3):不加机器,如何抗住每天百亿级高并发流量?》)聊了一下系统架构中,百亿流量级别高并发写入场景下,如何承载这种高并发写入,同时如何在高并发写入的背景下还能保证系统的超高性能计算。
这篇文章咱们继续来聊一下,百亿级别的海量数据场景下还要支撑每秒十万级别的高并发查询,这个架构该如何演进和设计?
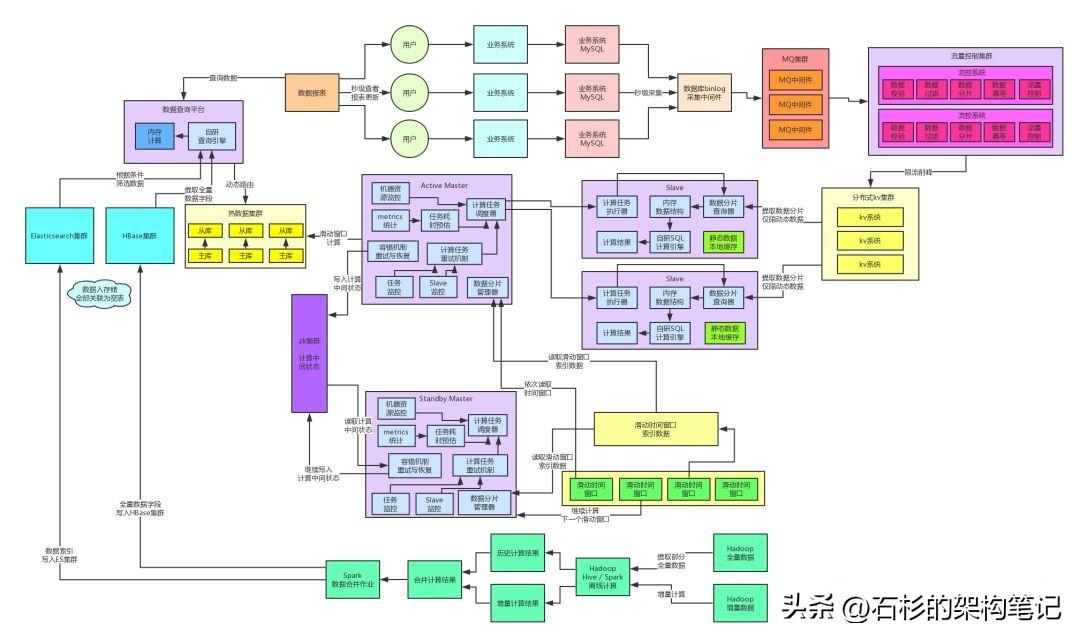
咱们先来看看目前系统已经演进到了什么样的架构,大家看看下面的图:
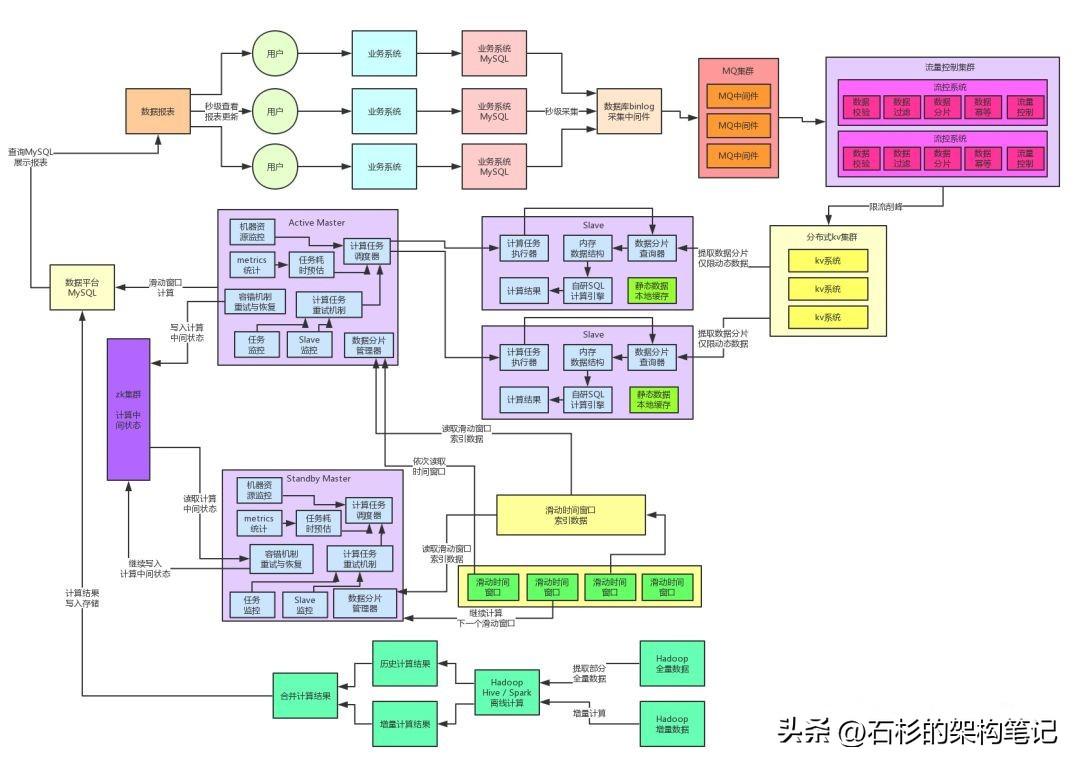
首先回顾一下,整个架构右侧部分演进到的那个程度,其实已经非常的不错了,因为百亿流量,每秒十万级并发写入的场景,使用MQ限流削峰、分布式KV集群给抗住了。
接着使用了计算与存储分离的架构,各个Slave计算节点会负责提取数据到内存中,基于自研的SQL内存计算引擎完成计算。同时采用了数据动静分离的架构,静态数据全部缓存,动态数据自动提取,保证了尽可能把网络请求开销降低到最低。
另外,通过自研的分布式系统架构,包括数据分片和计算任务分布式执行、弹性资源调度、分布式高容错机制、主备自动切换机制,都能保证整套系统的任意按需扩容,高性能、高可用的的运行。
下一步,咱们来研究研究架构里的左侧部分。
二、日益膨胀的离线计算结果
其实大家会注意到,在左侧还有一个MySQL,那个MySQL就是用来承载实时计算结果和离线计算结果放在里面汇总的。
终端的商家用户就可以随意的查询MySQL里的数据分析结果,支撑自己的决策,他可以看当天的数据分析报告,也可以看历史上任何一段时期内的数据分析报告。
但是那个MySQL在早期可能还好一些,因为其实存放在这个MySQL里的数据量相对要小一些,毕竟是计算后的一些结果罢了。但是到了中后期,这个MySQL可是也岌岌可危了。
给大家举一个例子,离线计算链路里,如果每天增量数据是1000万,那么每天计算完以后的结果大概只有50万,每天50万新增数据放入MySQL,其实还是可以接受的。
但是如果每天增量数据是10亿,那么每天计算完以后的结果大致会是千万级,你可以算他是计算结果有5000万条数据吧,每天5000万增量数据写入左侧的MySQL中,你觉得是啥感觉?
可以给大家说说系统当时的情况,基本上就是,单台MySQL服务器的磁盘存储空间很快就要接近满掉,而且单表数据量都是几亿、甚至十亿的级别。
这种量级的单表数据量,你觉得用户查询数据分析报告的时候,体验能好么?基本当时一次查询都是几秒钟的级别。很慢。
更有甚者,出现过用户一次查询要十秒的级别,甚至几十秒,上分钟的级别。很崩溃,用户体验很差,远远达不到付费产品的级别。
所以解决了右侧的存储和计算的问题之后,左侧的查询的问题也迫在眉睫。新一轮的重构,势在必行!
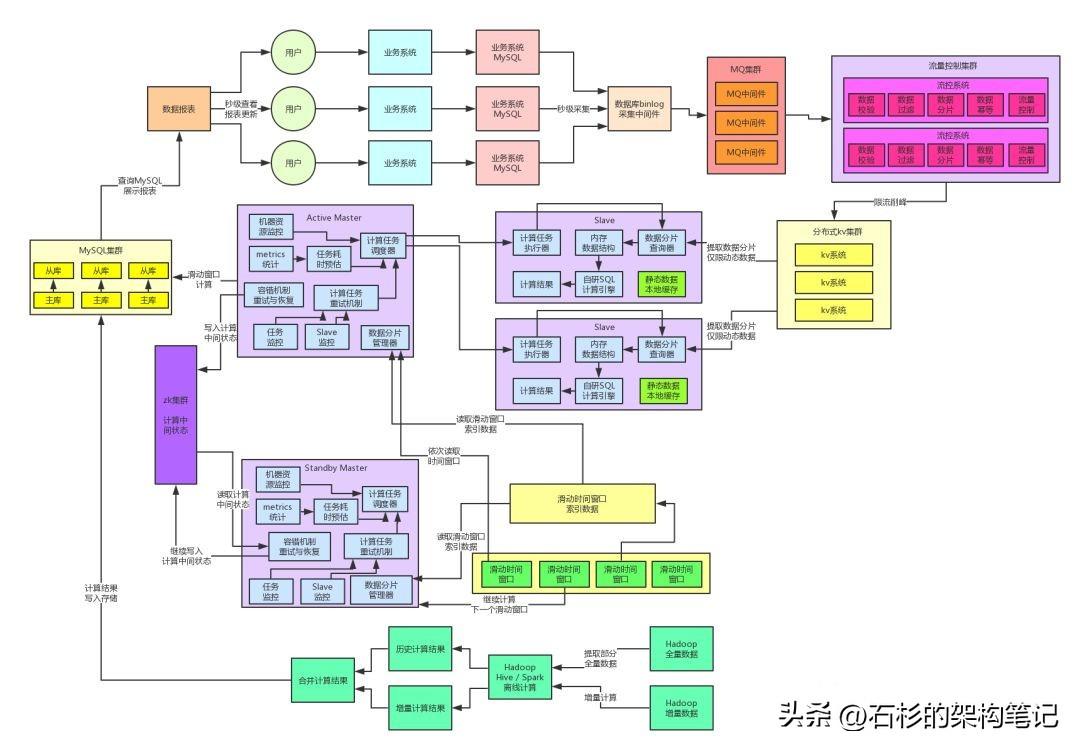
三、分库分表 + 读写分离
首先就是老一套,分库分表 + 读写分离,这个基本是基于MySQL的架构中,必经之路了,毕竟实施起来难度不是特别的高,而且速度较快,效果比较显著。
整个的思路和之前第一篇文章(《亿流量大考(1):日增上亿数据,把MySQL直接搞宕机了...》)讲的基本一致。
说白了,就是分库后,每台主库可以承载部分写入压力,单库的写并发会降低;其次就是单个主库的磁盘空间可以降低负载的数据量,不至于很快就满了;
而分表之后,单个数据表的数据量可以降低到百万级别,这个是支撑海量数据以及保证高性能的最佳实践,基本两三百万的单表数据量级还是合理的。
然后读写分离之后,就可以将单库的读写负载压力分离到主库和从库多台机器上去,主库就承载写负载,从库就承载读负载,这样避免单库所在机器的读写负载过高,导致CPU负载、IO负载、网络负载过高,最后搞得数据库机器宕机。
首先这么重构一下数据库层面的架构之后,效果就好得多了。因为单表数据量降低了,那么用户查询的性能得到很大的提升,基本可以达到1秒以内的效果。
四、每秒10万查询的高并发挑战
上面那套初步的分库分表+读写分离的架构确实支撑了一段时间,但是慢慢的那套架构又暴露出来了弊端出来了,因为商家用户都是开了数据分析页面之后,页面上有js脚本会每隔几秒钟就发送一次请求到后端来加载最新的数据分析结果。
此时就有一个问题了,渐渐的查询MySQL的压力越来越大,基本上可预见的范围是朝着每秒10级别去走。
但是我们分析了一下,其实99%的查询,都是页面JS脚本自动发出刷新当日数据的查询。只有1%的查询是针对昨天以前的历史数据,用户手动指定查询范围后来查询的。
但是现在的这个架构之下,我们是把当日实时数据计算结果(代表了热数据)和历史离线计算结果(代表了冷数据)都放在一起的,所以大家可以想象一下,热数据和冷数据放在一起,然后对热数据的高并发查询占到了99%,那这样的架构还合理吗?
当然不合理,我们需要再次重构系统架构。
五、 数据的冷热分离架构
针对上述提到的问题,很明显要做的一个架构重构就是冷热数据分离。也就是说,将今日实时计算出来的热数据放在一个MySQL集群里,将离线计算出来的冷数据放在另外一个MySQL集群里。
然后开发一个数据查询平台,封装底层的多个MySQL集群,根据查询条件动态路由到热数据存储或者是冷数据存储。
通过这个步骤的重构,我们就可以有效地将热数据存储中单表的数据量降低到更少更少,有的单表数据量可能就几十万,因为将离线计算的大量数据结果从表里剥离出去了,放到另外一个集群里去。此时大家可想而知,效果当然是更好了。
因为热数据的单表数据量减少了很多,当时的一个最明显的效果,就是用户99%的查询都是针对热数据存储发起的,性能从原来的1秒左右降低到了200毫秒以内,用户体验提升,大家感觉更好了。
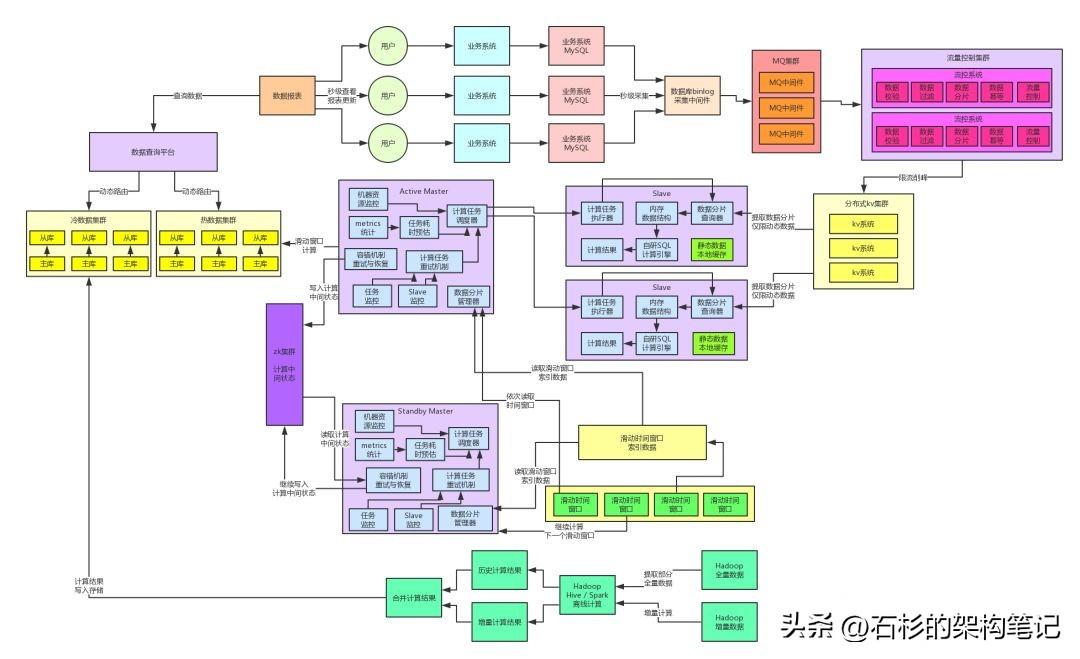
六、自研Elasticsearch+HBase+纯内存的查询引擎
架构演进到这里,看起来好像还不错,但是其实问题还是很多。因为到了这个阶段,系统遇到了另外一个较为严重的问题:冷数据存储,如果完全用MySQL来承载是很不靠谱的。冷数据的数据量是日增长不断增加,而且增速很快,每天都新增几千万。
因此你的MySQL服务器将会面临不断的需要扩容的问题,而且如果为了支撑这1%的冷数据查询请求,不断的扩容增加高配置的MySQL服务器,大家觉得靠谱么?
肯定是不合适的!
要知道,大量分库分表后,MySQL大量的库和表维护起来是相当麻烦的,修改个字段?加个索引?这都是一场麻烦事儿。
此外,因为对冷数据的查询,一般都是针对大量数据的查询,比如用户会选择过去几个月,甚至一年的数据进行分析查询,此时如果纯用MySQL还是挺灾难性的。
因为当时明显发现,针对海量数据场景下,一下子查询分析几个月或者几年的数据,性能是极差的,还是很容易搞成几秒甚至几十秒才出结果。
因此针对这个冷数据的存储和查询的问题,我们最终选择了自研一套基于NoSQL来存储,然后基于NoSQL+内存的SQL计算引擎。
具体来说,我们会将冷数据全部采用ES+HBase来进行存储,ES中主要存放要对冷数据进行筛选的各种条件索引,比如日期以及各种维度的数据,然后HBase中会存放全量的数据字段。
因为ES和HBase的原生SQL支持都不太好,因此我们直接自研了另外一套SQL引擎,专门支持这种特定的场景,就是基本没有多表关联,就是对单个数据集进行查询和分析,然后支持NoSQL存储+内存计算。
这里有一个先决条件,就是如果要做到对冷数据全部是单表类的数据集查询,必须要在冷数据进入NoSQL存储的时候,全部基于ES和HBase的特性做到多表入库关联,进数据存储就全部做成大宽表的状态,将数据关联全部上推到入库时完成,而不是在查询时进行。
对冷数据的查询,我们自研的SQL引擎首先会根据各种where条件先走ES的分布式高性能索引查询,ES可以针对海量数据高性能的检索出来需要的那部分数据,这个过程用ES做是最合适的。
接着就是将检索出来的数据对应的完整的各个数据字段,从HBase里提取出来,拼接成完成的数据。
然后就是将这份数据集放在内存里,进行复杂的函数计算、分组聚合以及排序等操作。
上述操作,全部基于自研的针对这个场景的查询引擎完成,底层基于Elasticsearch、HBase、纯内存来实现。
七、实时数据存储引入缓存集群
好了,到此为止,冷数据的海量数据存储、高性能查询的问题,就解决了。接着回过头来看看当日实时数据的查询,其实实时数据的每日计算结果不会太多,而且写入并发不会特别特别的高,每秒上万也就差不多了。
因此这个背景下,就是用MySQL分库分表来支撑数据的写入、存储和查询,都没问题。
但是有一个小问题,就是说每个商家的实时数据其实不是频繁的变更的,在一段时间内,可能压根儿没变化,因此不需要高并发请求,每秒10万级别的全部落地到数据库层面吧?要全都落地到数据库层面,那可能要给每个主库挂载很多从库来支撑高并发读。
因此这里我们引入了一个缓存集群,实时数据每次更新后写入的时候,都是写数据库集群同时还写缓存集群的,是双写的方式。
然后查询的时候是优先从缓存集群来走,此时基本上90%以上的高并发查询都走缓存集群了,然后只有10%的查询会落地到数据库集群。
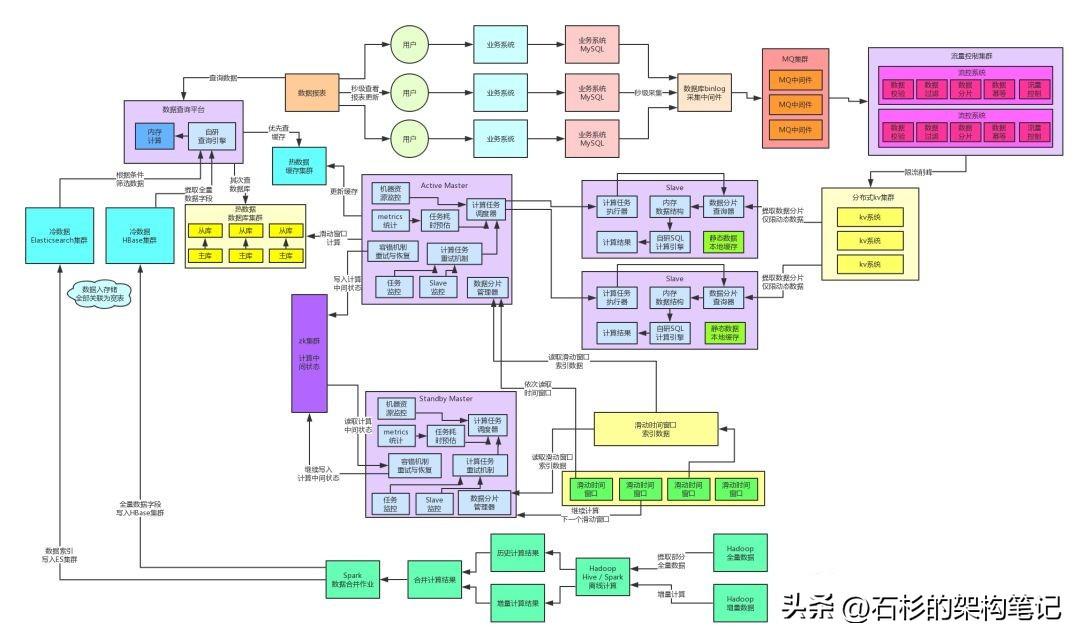
八、阶段性总结
好了,到此为止,这个架构基本左边也都重构完毕:
- 热数据基于缓存集群+数据库集群来承载高并发的每秒十万级别的查询。
- 冷数据基于ES+HBase+内存计算的自研查询引擎来支撑海量数据存储以及高性能查询。
经实践,整个效果非常的好。用户对热数据的查询基本多是几十毫秒的响应速度,对冷数据的查询基本都是200毫秒以内的响应速度。
九、下一阶段的展望
其实架构演进到这里已经很不容易了,因为看似这么一张图,里面涉及到无数的细节和技术方案的落地,需要一个团队耗费至少1年的时间才能做到这个程度。
但是接下来,我们要面对的,就是高可用的问题,因为付费级的产品,我们必须要保证超高的可用性,99.99%的可用性,甚至是99.999%的可用性。