假设有 10 天的销售额数据,我们想每三天求一次总和,比如第五天的总和就是第三天 + 第四天 + 第五天的销售额之和,这个时候该怎么做呢?
Series 对象有一个 rolling 方法,专门用来做移动计算,我们来看一下。
import pandas as pd
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(amount.rolling(3).sum())
"""
0 NaN # NaN + NaN + 100
1 NaN # NaN + 100 + 90
2 300.0 # 100 + 90 + 110
3 350.0 # 90 + 110 + 150
4 370.0 # 110 + 150 + 110
5 390.0 # 150 + 110 + 130
6 320.0 # 110 + 130 + 80
7 300.0 # 130 + 80 + 90
8 270.0 # 80 + 90 + 100
9 340.0 # 90 + 100 + 150
dtype: float64
"""
结果和我们想要的是一样的,amount.rolling(3) 相当于创建了一个长度为 3 的窗口,窗口从上到下依次滑动,我们画一张图:
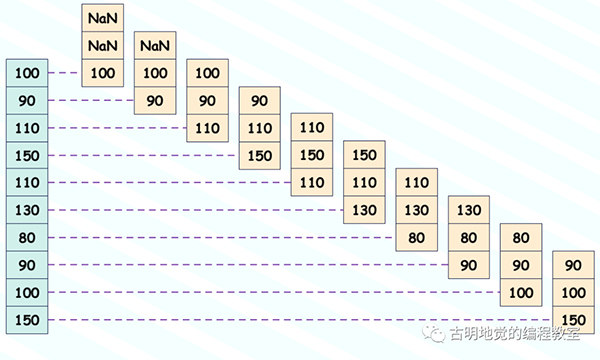
amount.rolling(3) 就做了类似于图中的事情,然后在其基础上调用 sum,会将每个窗口里面的元素加起来,就得到上面代码输出的结果。另外窗口的大小可以任意,这里我们以 3 为例。
除了sum,还可以求平均值、求方差等等,可以进行很多的操作,有兴趣可以自己尝试一下。当然我们也可以自定义函数:
import pandas as pd
import numpy as np
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(
# 调用 agg 方法,传递一个函数
# 参数 x 就是每个窗口里面的元素组成的 Series 对象
amount.rolling(3).agg(lambda x: np.sum(x) * 2)
)
"""
0 NaN # (NaN + NaN + 100) * 2
1 NaN # (NaN + 100 + 90) * 2
2 600.0 # (100 + 90 + 110) * 2
3 700.0 # (90 + 110 + 150) * 2
4 740.0 # (110 + 150 + 110) * 2
5 780.0 # (150 + 110 + 130) * 2
6 640.0 # (110 + 130 + 80) * 2
7 600.0 # (130 + 80 + 90) * 2
8 540.0 # (80 + 90 + 100) * 2
9 680.0 # (90 + 100 + 150) * 2
dtype: float64
"""
agg 里面的函数的逻辑可以任意,但返回的必须是一个数值。
此外我们注意到,开始的两个元素为 NaN,这是因为 rolling(3) 表示从当前位置往上筛选,总共筛选 3 个元素,图上已经画的很清晰了。但如果我们希望元素不够的时候有多少算多少,该怎么办呢?比如:第一个窗口里面的元素之和就是第一个元素,第二个窗口里面的元素之和是第一个元素加上第二个元素。
import pandas as pd
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(
# min_periods 表示窗口的最小观测值
amount.rolling(3, min_periods=1).sum()
)
"""
0 100.0
1 190.0
2 300.0
3 350.0
4 370.0
5 390.0
6 320.0
7 300.0
8 270.0
9 340.0
dtype: float64
"""
添加一个 min_periods 参数即可实现,这个参数表示窗口的最小观测值,即:窗口里面元素的最小数量,默认它和窗口的长度相等。我们窗口长度为 3,但指定了 min_periods 为 1,表示元素不够也没关系,只要有一个就行。
因此元素不够的话,有几个就算几个。如果我们指定 min_periods 为 2 的话,那么会是什么结果呢?显然第一个是 NaN,第二个还是 190.0,因为窗口里面的元素个数至少为 2。
import pandas as pd
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(
# 窗口的最小观测值为 2
amount.rolling(3, min_periods=2).sum()
)
"""
0 NaN
1 190.0
2 300.0
3 350.0
4 370.0
5 390.0
6 320.0
7 300.0
8 270.0
9 340.0
dtype: float64
"""
- 注意:min_periods必须小于等于窗口长度,否则报错。
rolling 里面还有一个 center 参数,默认为 False。我们知道 rolling(3) 表示从当前元素往上筛选,加上本身总共筛选 3 个。
但如果将 center 指定为 True 的话,那么会以当前元素为中心,从两个方向上进行筛选。比如 rolling(3, center=True),那么会往上选一个、往下选一个,再加上本身总共 3 个。所以示意图会变成下面这样:
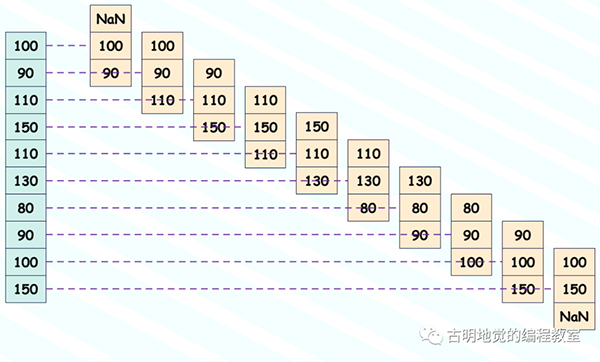
我们来测试一下:
import pandas as pd
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(
amount.rolling(3, center=True).sum()
)
"""
0 NaN
1 300.0
2 350.0
3 370.0
4 390.0
5 320.0
6 300.0
7 270.0
8 340.0
9 NaN
dtype: float64
"""
这里没有指定 min_periods,最小观测值和窗口长度相等,所以 rolling(3, center=True)会使得开头出现一个 NaN,结尾出现一个 NaN。
这时候可能有人好奇了,如果窗口的长度为奇数的话很简单,比如长度为 9,那么往上选 4 个、往下选 4 个,加上本身正好 9 个。但如果窗口的长度为偶数该怎么办?比如长度为 8,这个时候会往上选 4 个、往下选 3 个,加上本身正好 8 个。
另外我们还可以从上往下筛选,比如窗口长度为 3,但我们是希望从当前元素开始往下筛选,加上本身总共筛选 3 个。
import pandas as pd
from pandas.api.indexers import FixedForwardWindowIndexer
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(
amount.rolling(
FixedForwardWindowIndexer(window_size=3)).sum()
)
"""
0 300.0
1 350.0
2 370.0
3 390.0
4 320.0
5 300.0
6 270.0
7 340.0
8 NaN
9 NaN
dtype: float64
"""
通过类FixedForwardWindowIndexer即可实现这一点,当然此时就不可以指定 center 参数了。
调用 amount.rolling() 会返回一个 Rolling 对象,再调用 Rolling 对象的 sum, max, min, mean, std 等方法即可对每个窗口求总和、最大值、最小值等等。当然我们也可以调用 agg 方法,里面传入一个函数,来自定义每个窗口的计算逻辑。然后重点是,agg 里面除了接收一个函数之外,还能接收一个列表,列表里面可以有多个函数,然后同时执行多个操作。
import pandas as pd
import numpy as np
amount = pd.Series(
[100, 90, 110, 150, 110, 130, 80, 90, 100, 150])
print(
amount.rolling(3).agg(
[np.sum, np.mean, lambda x: np.sum(x) * 2])
)
# 执行多个操作,那么会返回一个 DataFrame
"""
sum mean <lambda>
0 NaN NaN NaN
1 NaN NaN NaN
2 300.0 100.000000 600.0
3 350.0 116.666667 700.0
4 370.0 123.333333 740.0
5 390.0 130.000000 780.0
6 320.0 106.666667 640.0
7 300.0 100.000000 600.0
8 270.0 90.000000 540.0
9 340.0 113.333333 680.0
"""
除了 Series 之外,DataFrame 也有 rolling 方法,功能和用法是一样的,只不过后者可以同时作用于多列。但大部分情况下,我们都调用 Series 对象的 rolling 方法。
rolling 方法还有一个强大的功能,就是它可以对时间进行移动分析,因为 pandas 本身就诞生在金融领域,所以非常擅长对时间的操作。
那么对时间进行移动分析的使用场景都有哪些呢?举一个笔者在大四实习时所遇到的问题吧,当时在用 pandas 做审计,遇到过这样一个需求:判断是否存在 30 秒内充值次数超过 1000 次的情况(也就是检测是否存在同时大量充值的情况),如果有就把它们找出来。
因为每一次充值都对应一条记录,每条记录都有一个具体的时间,换句话说就是要判断是否存在某个 30 秒,在这其中出现了超过 1000 条的记录。当时刚实习,被这个问题直接搞懵了,不过有了 rolling 方法就变得简单多了。
import pandas as pd
amount = pd.Series(
[100, 100, 100, 100, 100, 100, 100, 100, 100, 100],
index=pd.DatetimeIndex(
["2020-1-1", "2020-1-3", "2020-1-4", "2020-1-6",
"2020-1-7", "2020-1-9", "2020-1-12", "2020-1-13",
"2020-1-14", "2020-1-15"])
)
print(amount)
"""
2020-01-01 100
2020-01-03 100
2020-01-04 100
2020-01-06 100
2020-01-07 100
2020-01-09 100
2020-01-12 100
2020-01-13 100
2020-01-14 100
2020-01-15 100
dtype: int64
"""
# 这里我们还是算 3 天之内的总和吧
# 为了简单直观我们把值都改成100
print(amount.rolling("3D").sum())
"""
2020-01-01 100.0
2020-01-03 200.0
2020-01-04 200.0
2020-01-06 200.0
2020-01-07 200.0
2020-01-09 200.0
2020-01-12 100.0
2020-01-13 200.0
2020-01-14 300.0
2020-01-15 300.0
dtype: float64
"""
我们来分析一下,首先 rolling("3D") 表示筛选 3 天之内的,而且如果是对时间进行移动分析的话,那么要求索引必须是 datetime 类型。
- 先看 2020-01-01,它上面没有记录了,所以是100(此时就没有NaN了);
- 然后是 2020-01-03,由于上面的 2020-01-01 和它之间没有超过3天,所以加起来总共是200;
- 再看 2020-01-12,由于它只能往上找 2020-01-10, 2020-01-11,然后加在一起。但它的上面是 2020-01-09,已经超过3天了,所以结果是 100(就是它本身);
- 最后看 2020-01-14,3 天之内的话,应该 2020-01-12, 2020-01-13,再加上自身的 2020-01-14,所以结果是300。2020-01-15 也是同理。
怎么样,是不是很简单呢?回到笔者当初的那个问题上来,如果是找出 30 秒内超过 1000 次的记录的话,将交易时间设置为索引、直接 rolling("30S").count()。然后找出大于 1000 的记录,说明该条记录往上的第 1000 条记录的交易时间和该条记录的交易时间之差的绝对值不超过 30 秒(记录是按照交易时间排好序的)。
至于这 30 秒内到底交易了多少次,直接将该条记录的交易时间减去 30 秒,进行筛选就行了。所以用 rolling 方法处理该问题非常方便,但当时不知道,傻了吧唧地写 for 循环一条条遍历。
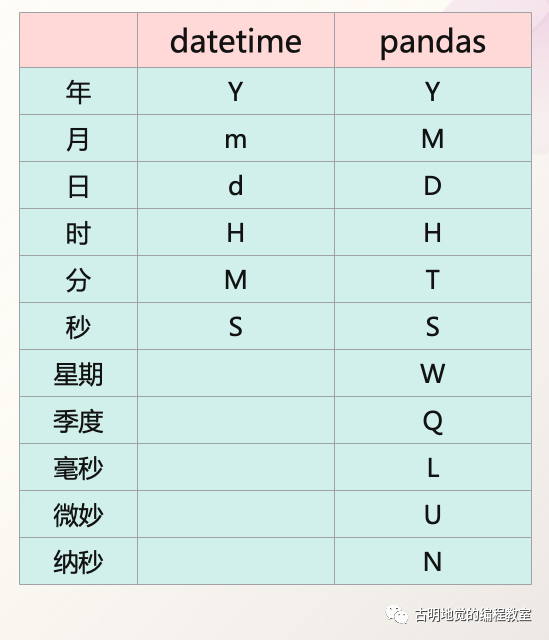
另外,关于 pandas 中表示时间的符号估计有人还不太清楚,最主要的是容易和 Python datetime 在格式化时所使用的符号搞混,下面我们来区分一下。
感觉如何,是不是既好用,功能又强大呢?