前言
G行某平台类应用系统提供高并发、低延迟的服务请求,该系统的的响应时间在1毫秒左右,目前最大TPS在2.5万左右,为保证该系统的快速响应,系统设置的超时时间为30毫秒。在一次巡检中发现,该系统的几台服务器超时交易笔数在逐渐增加,为避免系统运行风险,协调网络、操作系统等专家一同分析,在分析过程中补充学习了大量Linux操作系统内核的知识,现将分析过程及其中用到的知识点记录下来,以便为解决类似的问题提供一个通用的解决思路。
一、应用系统超时现象
外部系统将请求发送到前端服务,前端服务进行业务逻辑后重新组装报文,将请求发送到后端服务。交易处理超时体现在前端服务对后台服务的请求上,但是根据网络设备的镜像网络包分析,后端服务的处置时间没有异常,前端发送给后端的请求,后端都可以快速的处理。因此问题还是出现在前端服务上。

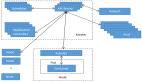
图1 系统逻辑架构
由于该系统的交易量大、响应时间低,所以对处理过程的日志记录较少,根据前端服务的应用日志无法定位根本原因。针对前端服务到后台服务的请求,选一段超时交易较多的时间段的网络镜像包进行分析。发现超时交易集中在两个固定的时间点,分别为:11:29:4.200,超时9笔,平均TCPack_rtt为5毫秒;11:29:54.100,超时2笔,平均TCPack_rtt为6毫秒,在这两个时间段超时交易的rtt都大于30毫秒,没有超时的交易也有部分ack的rtt相对较长。其他正常交易时间段的ack_rtt在0.06毫秒左右。

图2 网络镜像包异常现象
根据这个现象初步怀疑在网络收发包上出现了拥堵问题,操作系统网络协议栈对收到的网络包没有及时处理。具体处理过程为前端发送请求到后端服务,后端服务立即进行了响应并返回响应包,由于协议栈没有及时处理响应包,导致相应的ack包没有及时返回,同时导致前端服务没有及时收到后端服务的返回,从而出现超时的现象。
为验证怀疑的方向,将一台服务器进行物理重启,重启后超时现象消失;同时将另外一台服务器只重启应用系统,超时现象没有出现缓解。因此可以确定交易的超时现象是由于操作系统的原因导致,和应用系统的处理性能无关。
二、问题排查
由于怀疑和操作系统的协议栈处理有关,为便于问题排查,同时避免对生产的稳定运行造成影响,我们使用perf和hping3进行异常的复现和问题分析。perf是Linux的一款性能分析工具,能够进行系统内核函数级和指令级的热点查找,可以用来分析程序中热点函数的CPU占用率,从而定位性能瓶颈。Hping3是一个开源网络工具,通过rawSocket直接组装icmp、udp、tcp报文,并记录对方服务器的ack响应时间。

图3 问题排查方案
分析方案是找同子网的另外一台服务器部署hping3工具,向异常服务器不停的发送tcp报文,并记录ack返回出现延迟的时间点。在异常的服务器上部署perf工具,跟踪操作系统的内核调用,以便发现异常点。通过hping3每1毫秒发送一个网络包,记录其收到ack包的时间,可以发现在1650140557这个时间点出现大量rtt时间较长的情况,分析perf工具采集的内核调用数据,可以发现在相同的时间点存在大量ss进程发起的请求,当时正在执行的系统调用函数为read,根据调用栈proc_reg_read可以定位为程序正在读取/proc目录下的文件内容。


图4 内核系统异常调用栈
由于生产服务器上部署了各种代理和大量的监控脚本,因此怀疑是由这些代理、监控脚本发起的ss命令调用,在系统中查找使用ss命令的脚本,可以发现调用ss的命令行为图5所示。

图5 触发异常的shell调用
通过strace跟踪ss 调用过程,如图6所示。

图6 trace跟踪ss调用过程
关注read处理较慢的系统调用,可以发现read处理时间超过10ms的地方共有5处,最长的处理时间在189ms;根据文件句柄号3,可以确认正在读取的文件为”/proc/slabinfo”。

图7 ss命令系统调用的异常
至此可以确认网络包接收卡顿,是由于监控周期性调用ss命令导致。ss命令会读取/proc/slabinfo,而在读取的时候有部分read函数的系统调用处理较慢,从而影响了网络接收包的处理。
为进一步验证上述结论,我们将异常服务器上使用ss命令的监控脚本停止,并启动前端服务将其加入生产队列,经过长时间观察,未再发现超时现象。然后手工在服务器上连续执行几次cat /proc/slabinfo,可以发现超时现象再次出现。
三、深入分析原因
1.第一个疑问:为什么读取/proc/slabinfo会导致网络包接收卡顿?
网络协议栈接收tcp报文并自动返回ack,是操作系统在中断中处理的,优先级别较高,而用户读取/proc/slabinfo是一般的系统调用,为什么会影响内核的中断处理呢?首先需要了解一下Linux操作系统代码执行的几个上下文场景。
硬件中断上下文:优先级别最高,只要有硬件中断发生就会被立即执行,这里包括时钟中断、网卡中断;
软件中断上下文:在硬件中断执行完成或系统调用完成时执行,这个是操作系统内核核心代码执行的主要环境,包括进程调度,网络协议栈处理等等;
内核进程上下文:运行在内核态,但是受进程调度管理,按进程调度分配的时间片执行,超过执行的时间片就有可能被别的进程抢占而暂停执行;
用户进程上下文:这个是大部分应用程序执行的环境,受进程调度管理,按进程调度分配的时间片执行,超过执行的时间片会强制进行进程切换。
那他们的执行优先级是不是就是:硬件中断> 软件中断> 内核进程> 用户进程。实际并不完全是这样,由于硬件中断、软件中断、内核进程都运行在内核态,运行在相同的地址空间,所有的数据都是共享的,如果硬件中断强制中断软件中断的执行,软件中断强制中断内核进程的执行,那么有可能会导致内核数据的混乱或者导致各种死锁,为了保护临界数据的安全和完整性,软件中断可以关硬件中断,内核进程可以关闭硬件中断和软件中断。
在执行cat/proc/slabinfo时,首先程序运行在用户进程上下文,然后执行系统调用read被切换到内核进程上下文,由于slabinfo中存储的是内核的内存分配信息,在读取内存分配信息时为了保证数据的一致性,在内核进程上下文中关闭了硬件中断和软件中断。由于进程调度也是通过硬件中断中的时钟中断触发的,所以如果长时间的关闭硬件中断、软件中断,进程调度也不会被执行。如果read执行时间较长,关闭中断的时间就会比较长,该进程就会长时间占用CPU不释放,阻止了内核协议栈对网络收包的处理。
查看Linux内核代码/linux-3.0.101/mm/slab.c中的s_show函数,可看到如下关闭中断的代码

图8 读取slabinfo时关闭中断的内核代码
2.第二个疑问:服务器具有40CPU,为什么一个ss命令就会阻止网络包的处理呢,理论上应还有另外39个CPU来处理?
这个涉及RPS(ReceivePacket Steering)和RFS(ReceiveFlowSteering)技术,其主要功能就将高速网卡产生的大量网络包分配到多核CPU分别进行处理,但是这个分配是预分配,根据socket四元组(源IP、源端口、目的IP、目的端口)分配到不同的CPU进行处理。ss命令在哪个CPU上执行,那么分配到这个CPU上的网络包处理就会出现卡顿。因此在生产环境的表现上也是只有部分网络包出现了卡顿,而不是所有的网络包都会产生卡顿。
3.第三个疑问:读取/proc/slabinfo为什么会慢?
Slab算法是以字节为单位管理内存,是内核的小内存管理算法。特点是基于对象进行管理。slab分配算法采用cache存储内核对象,把相同类型的对象归为一类,每当要申请这样一个对象,slab分配器就从一个slab列表中分配一个这样大小的单元出去,而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免这些内碎片。slab分配器并不丢弃已分配的对象,而是释放并把它们保存在内存中。当以后又要请求新的对象时,就可以从内存直接获取而不用重复初始化。
通过cat /proc/slabinfo可以查看slab分配的内存情况,其中包含的信息主要为统计信息,包括每种对象内存的总个数、已分配的个数、每页内存的对象个数、占用的内存页数等等。这些统计信息是怎么来的呢?是内核中现成的统计数据吗?通过查看代码可以发现,是一个个累加汇总来的,如果内存对象的个数较多,那将是一个非常耗时的大循环。其内核代码如下:

通过cat /proc/slabinfo | sort -n-k3的输出,查看一下哪些内存对象的个数较多。

图9 slab内存对象数量
如图9所示占用比较高的几项是dentry、buffer_head、proc_inode_cache。dentry 是文件目录对inode映射的缓存;Buffer_head 是硬盘的块缓存;proc_inode_cache 是/proc目录下inode节点信息的缓存。dentry、proc_inode_cache分别达到了797万和388万,这个数据量非常大,导致在输出/proc/slabinfo时耗时较长。
4.第四个疑问:为什么重启服务器后网络包卡顿现象就消失,其后为什么会变慢呢?
重启后卡顿现象消失这个问题现在很容易回答,那就是由于重启后slab中的缓存信息全部释放了,对象个数较少,再统计slabinfo时处理较快,不会影响网络包的接收了。重启运行一段时间后会再出现卡顿现象,是由于slab中缓存的信息又变多了,那是谁导致slab缓存了大量信息呢?
slab中个数较多的内存对象是dentry和proc_inode_cache,在查看/proc目录下的文件时,操作系统会自动将目录信息和inode信息缓存到这两个对象。因此是有程序周期性的读取/proc目录下的文件导致这两个内存对象缓存个数增多的。再次跟踪一下ss命令可以发现ss命会扫描/proc下所有进程打开的文件句柄,包括socket链接。我们这台服务器经常保持数万的链接数,这些链接的存活时间最短只有几秒钟,最长也就几个小时。因此执行一次ss-lntp命令会缓存数万的proc_inode_cache和dentry,如果周期性的执行这个命令,打开的socket句柄又不停的发生变化,就会导致slab缓存的数量不断增长。
四、问题解决
通过上面的分析可以确认导致网络包卡顿的原因是:周期性的调用ss-lntp命令,同时这台服务器上的网络链接不断发生变化,使得slab中缓存了大量的内存对象,并且ss会读取/proc/slabinfo中的汇总信息,而slabinfo中的汇总信息是每次通过效率不高的一个个累加的方式获得,且累加时关闭了操作系统的中断处理,导致接收到的网络包无法及时处理。
因此可采取的解决方案:
(1)执行echo "2" > /proc/sys/vm/drop_caches ,强制操作系统回收inode和dentry中的缓存信息。这个命令执行期间会造成系统卡顿,卡顿时间为几秒到几分钟,关键业务运行期间需慎用;
(2)周期性重启服务器,释放slab中的缓存信息;
(3)停止周期性调用ss -lntp;
(4)对于ss命令,可以去掉 -p 参数,去掉这个参数后,ss将不再扫描/proc目录下的进程信息,不会导致slab中内存对象个数的增长。另外也可以升级到高版本的ss命令,在高版本的ss命令中已不再读取 /proc/slabinfo,因为这里面已没有可以获取的有效信息。下面是github中的commit信息。

图10 GitHub中commit信息
总结
针对这个问题的分析持续了大约一、两个月的时间,期间也曾一度陷入迷惑而毫无进展,有初步分析思路后补充了操作系统内核的各种知识,主要包括进程调度、调度优先级、中断处理、网络协议栈处理、虚拟文件系统等等,最终可以将整个问题的来龙去脉解释清楚。
参考资料:
《如何调试Kubernetes集群中的网络延迟问题?》Theo Julienne 分布式实验室
《网卡多队列:RPS、RFS、RSS、FlowDirector(DPDK支持)》rtoax CSDN
https://rtoax.blog.csdn.net/article/details/108987658
https://github.com/shemminger/iproute2/commit/10f687736b8dd538fb5e2bdacf6bef2c690ee99d