最近,数据科学界大力推广生成性对抗网络(Generative Adversarial Networks:简称“GAN”)。但是,当你开始了解它们时,你马上就会明白其中的缘由。GAN架构简直是一个天才的设计,主要是因为它“释放”了现实数据生成和增强的巨大潜力。在本文中,我将首先向您介绍GAN的基础知识,并向您展示如何使用Keras/Tensorflow库在Python环境中编写一个GAN。归纳起来,主要包括下面几项内容:
- 机器学习算法中的GAN
- GAN架构及其工作原理的直观解释
- 通过一个详细的Python示例演示如何从头开始构建GAN
1.机器学习算法中的GAN
即使是经验丰富的数据科学家也很容易在数百种不同的机器学习算法中迷失方向。为了归纳这些算法,我对一些最常见的算法进行了分类,并创建了一个可视化的旭日图。

机器学习算法分类旭日图
注意,这其中的一些算法相当灵活,可以应用于不同的任务。因此,任何分类算法都永远不会是最完美的分类算法。尽管如此,能够看到一个如此高层次的视图仍然有重大意义。注意:原文中展示的图表是交互式的,只要点击不同类别的链接便可以了解更多对应的提示信息。因此,本译文中提供的静态图表只能让各位稍有一些遗憾了。
你会发现,GAN也不过是神经网络的一个子类,它自身也进一步包含多个不同的子类型,如基本GAN(本文的重点)、条件GAN(cGAN)、深度卷积GAN(DCGAN)和我将在未来文章中介绍的其他类型。
2.GAN架构及其工作原理的直观解释
生成性对抗网络是深度学习机器,它将两个单独的模型组合到一个架构中。这两个组件是:
- 生成器模型
- 鉴别器模型
这两个模型在零和博弈中相互竞争。生成器模型尝试生成与问题域中的数据样本相似的新数据样本。同时,鉴别器尝试识别给出的样本是假的(来自生成器)还是真的(来自实际数据域)。
生成器和鉴别器之间的竞争使它们成为对手,GAN由此而得名。
3.生成器模型
首先,让我们分析一下生成器模型,看看它是如何生成新的数据样本的。

生成器模型示意图
- 生成器模型从潜在空间中采样一个随机向量。该空间遵循高斯分布,维数由我们指定。由于我们将随机向量用作神经网络的输入,因此随机向量成为该生成过程的种子数据。
- 输入遵循一个或多个隐藏层的网络标准路径。在简单的GAN架构的情况下,这将是一组紧密连接的层,而深度卷积GAN(DCGAN)也是包含卷积层的。
- 数据流入输出层,在这里我们可以进行最终调整,以确保生成器输出结果数据中包含所需的形状,以馈送到鉴别器。
- 最后,我们可以使用这些假(生成)的样本来测试和“愚弄”(fool)鉴别器。
4.鉴别器模型
接下来,让我们看看如何构造鉴别器模型。

鉴别器模型
- 鉴别器模型的输入是真实样本(从问题域中提取)和虚假样本(由生成器模型创建)的组合。
- 数据通过具有一个或多个隐藏层的网络,与任何其他神经网络中的数据相同。3、一旦我们到达输出层,鉴别器就能够决定样本是真的还是假的(生成的)。总之,鉴别器与标准神经网络分类模型没有什么不同。
5.GAN模型
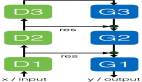
生成性对抗网络结合了相互竞争的生成器和鉴别器模型。下面的GAN架构图说明了两个模型是如何互连的。

GAN模型架构示意图
如图所示,我们将假的(生成的)和真实的样本数据输入鉴别器模型,对其进行训练以区分这两种类型。
随着鉴别器更好地区分真假样本数据,生成器模型的权重和偏差会得到更新,以使其产生更令人信服的假样本数据。
该过程将循环执行若干遍(根据指定次数的世代),直到生成器和鉴别器在其各自特定任务中变得更好。最后,在极限情况下,生成器模型的输出与实际输出无法区分,鉴别器模型收敛到大约0.5的中性预测结果。
6.从头开始构建一个基于Python的GAN示例
本示例的目的是让您从根本上了解GAN的工作原理。因此,我们将其应用于一个简单的问题。
准备工作
我们将使用到下面一些库:
- Pandas、Numpy和Math库,用于数据生成和操纵
- Matplotlib、Graphviz和Plotly(可选),用于数据可视化
- Tensorflow/Keras,用于构建神经网络
首先,让我们导入库:
# Tensorflow / Keras
from tensorflow import keras #用于构建神经网络
print('Tensorflow/Keras: %s' % keras.__version__) #打印版本
from keras.models import Sequential #用于组装神经网络模型
from keras.layers import Dense #给神经网络模型增添一些层
from tensorflow.keras.utils import plot_model #绘制模型图
#数据操纵
import numpy as np #用于数据操纵
print('numpy: %s' % np.__version__) #打印版本
import pandas as pd # 用于数据操纵
print('pandas: %s' % pd.__version__) #打印版本
import math #用于生成真实数据(本例中指向一个圆)
#可视化
import matplotlib
import matplotlib.pyplot as plt #用于数据可视化
print('matplotlib: %s' % matplotlib.__version__) #打印版本
import graphviz # for showing model diagram
print('graphviz: %s' % graphviz.__version__) # 打印版本
import plotly
import plotly.express as px # 用于数据可视化
print('plotly: %s' % plotly.__version__) # 打印版本
#其他工具
import sys
import os
#把主目录赋值给一个变量
main_dir=os.path.dirname(sys.path[0])
以上代码将打印出本例中使用的包的版本信息,如下所示:
- Tensorflow/Keras: 2.7.0
- numpy: 1.21.4
- pandas: 1.3.4
- matplotlib: 3.5.1
- graphviz: 0.19.1
- plotly: 5.4.0
接下来,我们将创建一个圆,并获取其边缘(圆周)上点的坐标。然后,我们将通过训练生成器和鉴别器,让GAN“识别”和“生成”这样的圆。
#获取其边缘(圆周)上点的坐标的函数
def PointsInCircum(r,n=100):
return [(math.cos(2*math.pi/n*x)*r,math.sin(2*math.pi/n*x)*r) for x in range(0,n+1)]
# 保存组成半径为2的圆的一组实数点的坐标
circle=np.array(PointsInCircum(r=2,n=1000))
#绘制图表
plt.figure(figsize=(15,15), dpi=400)
plt.title(label='Real circle to be learned by the GAN generator', loc='center')
plt.scatter(circle[:,0], circle[:,1], s=5, color='black')
plt.show()
上面的代码将生成1000个点,并绘制一个圆形。

由1000个点组成的圆
创建GAN模型
现在,我们已经准备好了数据。接下来,让我们开始定义和组装我们的模型。我们将从生成器开始:
# 定义生成器模型
def generator(latent_dim, n_outputs=2):
model = Sequential(name="Generator") # 模型
#添加层
model.add(Dense(32, activation='relu', kernel_initializer='he_uniform', input_dim=latent_dim, name='Generator-Hidden-Layer-1')) #隐藏层
model.add(Dense(16, activation='relu', kernel_initializer='he_uniform', name='Generator-Hidden-Layer-2')) #隐藏层
model.add(Dense(n_outputs, activation='linear', name='Generator-Output-Layer')) #输出层
return model
# 实例化
latent_dim=3
gen_model = generator(latent_dim)
#显示模型总结信息并绘制模型图
gen_model.summary()
plot_model(gen_model, show_shapes=True, show_layer_names=True, dpi=400)

生成器模型图
如您所见,我们的生成器有三个输入节点,因为我们决定从三维潜在空间中绘制一个随机向量。注意,我们可以自由选择潜在空间维度。
同时,输出结果中显示了两个值,对应于二维空间中的一个点的x和y坐标。接下来,我们建立鉴别器模型:
# 建立鉴别器模型
def discriminator(n_inputs=2):
model = Sequential(name="Discriminator") #模型
#添加层
model.add(Dense(32, activation='relu', kernel_initializer='he_uniform', input_dim=n_inputs, name='Discriminator-Hidden-Layer-1')) #隐藏层
model.add(Dense(16, activation='relu', kernel_initializer='he_uniform', name='Discriminator-Hidden-Layer-2')) #隐藏层
model.add(Dense(1, activation='sigmoid', name='Discriminator-Output-Layer')) # 输出层
#编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# 实例化
dis_model = discriminator()
#显示模型总结信息并绘制模型图
dis_model.summary()
plot_model(dis_model, show_shapes=True, show_layer_names=True, dpi=400)

鉴别器模型图
鉴别器输入采用两个值,与生成器输出对齐。同时,鉴别器输出只是一个值,告诉我们模型对数据真实/虚假的信心有多大。接下来,我们结合这两个模型来创建GAN。下面代码中的一个关键细节是,我们使鉴别器模型不可训练。我们这样做是因为,我们想使用真实和虚假(生成)数据的组合分别训练鉴别器。稍后,您将看到我们是如何做到这一点的。
def def_gan(generator, discriminator):
#我们不想在这个阶段训练鉴别器的权重。因此,使其不可训练
discriminator.trainable = False
#结合这两个模型
model = Sequential(name="GAN") # GAN 模型
model.add(generator) # 添加生成器
model.add(discriminator) # 添加鉴别器
#编译模型
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
# 实例化
gan_model = def_gan(gen_model, dis_model)
#显示模型总结信息并绘制模型图
gan_model.summary()
plot_model(gan_model, show_shapes=True, show_layer_names=True, dpi=400)

GAN模型示意图
准备生成器和鉴别器的输入
我们将创建三个简单的函数,用于辅助我们完成为两个模型的采样与生成数据。第一个函数的功能是从圆上采样真实点数据;第二个函数负责从潜在空间中提取随机向量;第三个函数负责将潜在变量传递到生成器模型中以生成伪样本数据。#构造函数,使负责从我们的圆上采集随机点数据
def real_samples(n):
#真实样本数据
X = circle[np.random.choice(circle.shape[0], n, replace=True), :]
#类标签
y = np.ones((n, 1))
return X, y
#生成潜在空间上的点数据;我们将用于后面的生成器的输入数据
def latent_points(latent_dim, n):
#生成潜在空间上的点数据
latent_input = np.random.randn(latent_dim * n)
#重新构造形状:使成为网络的批输出
latent_input = latent_input.reshape(n, latent_dim)
return latent_input
#使用生成器生成n个伪样本数据,结合类标签信息
def fake_samples(generator, latent_dim, n):
#生成潜在空间中的点
latent_output = latent_points(latent_dim, n)
#预测输出(例如生成伪样本数据)
X = generator.predict(latent_output)
#创建类标签
y = np.zeros((n, 1))
return X, y
模型训练和评估
最后两个函数将帮助我们训练模型,并在指定的时间间隔评估结果数据。首先,让我们创建模型性能评估函数:
def performance_summary(epoch, generator, discriminator, latent_dim, n=100):
#获取真实数据的样本
x_real, y_real = real_samples(n)
#在真实数据上评估鉴别器
_, real_accuracy = discriminator.evaluate(x_real, y_real, verbose=1)
#获取假的(生成的)样本
x_fake, y_fake = fake_samples(generator, latent_dim, n)
#在虚假(生成的)数据上评估鉴别器
_, fake_accuracy = discriminator.evaluate(x_fake, y_fake, verbose=1)
#总结鉴别器性能
print("Epoch number: ", epoch)
print("Discriminator Accuracy on REAL points: ", real_accuracy)
print("Discriminator Accuracy on FAKE (generated) points: ", fake_accuracy)
#创建二维散点图以显示真实和虚假(生成的)数据点
plt.figure(figsize=(4,4), dpi=150)
plt.scatter(x_real[:, 0], x_real[:, 1], s=5, color='black')
plt.scatter(x_fake[:, 0], x_fake[:, 1], s=5, color='red')
plt.show()
如您所见,上述函数分别对真实和虚假(生成)点对鉴别器进行了评估。然后绘制二维散点图,以显示这些点在二维平面上的位置。
最后,训练函数如下:
def train(g_model, d_model, gan_model, latent_dim, n_epochs=10001, n_batch=256, n_eval=1000):
#我们训练鉴别器的批次将包括一半真实点和一半假(生成的)点
half_batch = int(n_batch / 2)
#我们使用手动方式枚举世代( epochs )
for i in range(n_epochs):
#训练鉴别器
#准备真实样品数据
x_real, y_real = real_samples(half_batch)
#准备假(生成)样本数据
x_fake, y_fake = fake_samples(g_model, latent_dim, half_batch)
# 使用真实和虚假样本训练鉴别器
d_model.train_on_batch(x_real, y_real)
d_model.train_on_batch(x_fake, y_fake)
#生成器训练
# 从潜在空间中获取用作生成器输入的点
x_gan = latent_points(latent_dim, n_batch)
# 当我们生成假样本时,我们希望GAN生成器模型创建与真实样本相似的样本
# 因此,我们希望传递与真实样本对应的标签,即y=1,而不是0。
y_gan = np.ones((n_batch, 1))
# Train the generator via a composite GAN model
gan_model.train_on_batch(x_gan, y_gan)
# Evaluate the model at every n_eval epochs
if (i) % n_eval == 0:
performance_summary(i, g_model, d_model, latent_dim)
如前所述,我们通过传递一批50%真实和50%虚假(生成)的样本数据来分别训练鉴别器。同时,生成器训练通过组合的GAN模型进行。
实验结果
让我们调用训练函数来显示一些上述实验的结果:
# 训练GAN模型
train(gen_model, dis_model, gan_model, latent_dim)
下图展示的是在世代(epoch)0时期输出的结果:

世代0完成后的GAN性能
在世代3,000时期输出的结果:

在世代3,000完成后输出的结果
在世代10,000时期输出的结果:

在世代10,000完成后输出的结果
我们可以看到生成器在每一步都得到了改进。然而,在经历了10000个世代之后,鉴别器仍然表现良好,能够识别大多数真实样本和大部分虚假(生成)样本。因此,我们可以继续将该模型训练到下一个10000个世代,以取得更好的结果。比较上述模型性能的另一种方法是查看真实和虚假点分布的汇总统计结果:
# 生成1000个伪样本数据
x_fake, y_fake = fake_samples(gen_model, latent_dim, 1000)
df_fake = pd.DataFrame(x_fake, columns=['x dimension', 'y dimension'])
# 1000个真实的样本数据点
x_real, y_real = real_samples(1000)
df_real = pd.DataFrame(x_real, columns=['x dimension', 'y dimension'])
#显示汇总统计结果
print("Distribution statistics of fake (generated) points")
print(df_fake.describe())
print("----------------------------------------")
print("Distribution statisticss of real points")
print(df_real.describe())

真实和虚假(生成)点分布统计的比较
上述实验数据清楚地表明了:分布差异相对较小。
7.结语
我希望阅读完本文后,你能够很好地理解了GAN网络的工作原理。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。早期专注各种微软技术(编著成ASP.NET AJX、Cocos 2d-X相关三本技术图书),近十多年投身于开源世界(熟悉流行全栈Web开发技术),了解基于OneNet/AliOS+Arduino/ESP32/树莓派等物联网开发技术与Scala+Hadoop+Spark+Flink等大数据开发技术。
原文链接:https://towardsdatascience.com/gans-generative-adversarial-networks-an-advanced-solution-for-data-generation-2ac9756a8a99