项目概述
Sparkify是一个数字音乐服务,用户在其中使用免费层或使用高级订阅模式,即每月支付固定费用,播放他们喜欢的歌曲。用户与应用程序的所有互动(事件)都被记录下来,这为收集洞察力、学习行为模式和探索客户漏斗提供数据。每个用户我们都收集历史事件,如歌曲播放、喜欢、不喜欢、登录、退出、升级、降级等。分析这些数据,我们可以帮助企业了解 "让客户满意"的关键驱动因素,并回答诸如如何提高客户满意度,如何让用户更加投入,激励他们升级订阅等问题。
问题陈述
用户可以升级、降级或取消服务。如果我们能够预测用户取消服务的意图,我们就可以尝试针对这些用户提供特别优惠,这将有可能防止用户流失并为企业节省数百万美元。在这个项目中,我们已经建立了一个模型,根据用户在应用程序中的历史事件,识别出具有高流失倾向的用户。
评价指标
"流失预测" 问题的主要挑战是目标不平衡。在目前的数据集中,流失的用户占所有用户的22.5%,这对用于模型学习和调整的指标提出了限制。我们使用网格搜索,并以F1-score作为评价指标以选出最佳超参数,因为F1-score对不平衡的类较为稳健的。对于业务层面的解释,计算最佳模型的召回率也是很有帮助的,因为它显示了我们真正松动的流失案例的比例。
准备工作
导入所需要的python类库
# import libraries
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.types import IntegerType, DateType
from pyspark.sql.window import Window
from pyspark.ml.feature import CountVectorizer, IDF, CountVectorizerModel
from pyspark.ml.feature import OneHotEncoder, VectorAssembler
from pyspark.ml.classification import RandomForestClassifier, GBTClassifier
from pyspark.ml import Pipeline
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
from pyspark.ml.pipeline import PipelineModel
from datetime import datetime
import pandas as pd
import numpy as np
from itertools import chain
from typing import Dict
import sweetviz as sv
创建 Spark session
spark = SparkSession \
.builder \
.appName("Sparkify") \
.getOrCreate()
读取数据
event_data = "mini_sparkify_event_data.json"
# 该数据集的获取,可以在@公众号:数据STUDIO 后台回复:data
df = spark.read.json(event_data)
df.head()
步骤一 数据探索和可视化
由于我们研究的是一个小子集,所以使用pandas来执行EDA非常方便。
我们的分析包括3个步骤:
- 探索数据
- 定义流失
- 探索流失用户vs留存用户
探索数据
将Spark数据框架转换为pandas数据框架,使EDA运行更加灵活。使用“sweetviz”,我查看每一列的主要属性。
pandas_data = df.toPandas()
pandas_data[:2]

我们对一个数据样本进行了数据探索,其中包括225个注册用户的278154条记录和8346条未知用户的记录。完整的数据集包括22278个注册用户的数据,我们稍后使用这些数据来训练模型。为了在进入细节之前在3行中获得数据集的良好概述,我们使用了 sweetviz (https://pypi.org/project/sweetviz/) 包。
import sweetviz as sv
# 生成sweetviz报告
analysis = sv.analyze([pandas_data, 'sample_data'] )
analysis.show_html('./EDA_reports/sample_data_overview.html')
以下是关于样本数据的简短总结。

数据概况
- 数据集中有225个注册用户,63天内有2354个会话。97%的记录涵盖了这些用户的事件,只有3%的记录包括了关于客人的数据。
- 对于访客用户(auth='Guest'),我们没有neiver歌曲数据或用户人口统计学数据,也没有userId。他们的页面访问仅限于。首页、帮助、注册、关于、提交注册、错误。我们从模型数据集中排除了访客用户。
- 有3%的记录是auth='Logged Out',其中包括主页、登录、关于、帮助和错误事件。这些事件没有userId数据,所以我们把它们从建模数据集中排除。
- 只有20%的用户属于免费层,80%的用户使用付费订阅(图1)。

图1.Sparkify中付费与免费层级的用户分布情况
- 80%的记录描述了NextSong事件,包括艺术家和歌曲数据。20%的事件涵盖了所有可能的行动(图2)。
- 我们有52个取消事件,由auth='Cancelled'和page='Cancellation Confirmation'描述。有52个唯一的userId,他们取消了订阅。所以这个事件对每个用户都是唯一的。

- 图2.Sparkify数据集样本中不同页面事件的分布情况
界定目标
我们将流失定义为现有用户取消订阅的事实。取消的事实是通过两列数据推出的的:Auth='Cancelled'和page='Cancellation Confirmation',这两列是唯一定义的,所以我们可以使用两列中的任何一列来定义目标。使用page='Cancellation Confirmation'作为我们的目标变量。此外还有一个事件page='Cancel',它在'Cancellation Confirmation'之前,所以应该把这个事件从训练数据集中删除,以避免数据泄露。
比较流失用户和活跃用户
- 在那些流失的用户中,男性更多(57%为男性/43%为女性),反之亦然,在那些保持订阅的用户中,女性更多(42%为男性/58%为女性)。

图3.搅局者(蓝色)和活跃者(橙色)的性别分布
- 流失的用户通常在会话中的项目数量较少(流失中位数VS 其他中位数:66 VS 71)。
- 在流失的用户中,有更多的免费用户(在流失用户中占28%,在其他用户中占19%)。

图4.流失用户(蓝色)和活跃用户(橙色)的层级分布
- 从页面事件统计中我们看到,在流失的人中,喜欢的人较少,不喜欢的人较多,滚动广告的频率几乎高出2倍。
- 流失的用户寿命较短。
步骤二 特征工程
原始数据集由每个用户的多条记录(事件)组成。利用这些数据,在用户层面推导出特征,因此在训练/测试数据中,我们对每个唯一的userId只有一条记录。
第1步:在用户层面汇总特征
1.排除具有空userId的记录。
2.添加标签:1=流失,0=留存。条件:page='Cancellation Confirmation'(取消确认)。
3.删除page='Cancellation Confirmation'和page='Cancel'的记录。
4.按照userId和ts对数据框架进行排序
5.在用户层面上汇总特征。
- 创建歌曲列表
- 创建艺术家名单
- 页面事件列表(取消确认和取消事件被初步过滤,以消除数据泄漏)
- session frequency:会议次数/(最后一次会议时间-第一次会议时间)。
- 每session的平均歌曲数:总歌曲数/总节数
- 二分类特征。男性性别=1/0
- 二分类特征:付费账户=1/0
- lifetime(天):最后一次活动与注册日期之间的时间差
- 从代理值中得出操作系统/设备的特征
def preprocess_data(df: pyspark.sql.DataFrame) -> pyspark.sql.DataFrame:
"""
收集用户层面的应用数据
用于进一步特性工程步骤的数据框架
=================
Args:
df(pyspark Dataframe): 从Sparkify中提取数据
Return:
预处理 pyspark dataframe
"""
w = Window.partitionBy(df.userId).orderBy(df.ts)
w_uid = Window.partitionBy(df.userId)
preprocessed_df = (df
.filter(F.col('userId')!='') #过滤掉的过客
.withColumn('cancelled', (F.col('page')=='Cancellation Confirmation').cast(IntegerType()))
.withColumn('churn', F.max('cancelled').over(w_uid)) # 定义流失标签
.withColumn('current_level', F.last('level').over(w)) # 按日期对订阅级别进行排序
.withColumn('last_userAgent', F.last('userAgent').over(w)) # 按日期对代理进行排序
.filter(~F.col('page').isin(['Cancellation Confirmation',
'Cancel'])) #从数据集中移除取消页事件
.groupby('userId') # 在用户级聚合特征
.agg(F.collect_list('artist').alias('artist_list'), # 合并到列表中的所有艺术家
F.collect_list('song').alias('song_list'), # 合并到列表中的所有歌曲
F.collect_list('page').alias('page_list'), # 合并到列表所有页面事件
F.countDistinct('sessionId').alias('session_count'), # 计算总会话数
F.count('song').alias('song_count'), # 计算歌曲总数
F.first('gender').alias('gender'), # 性别数据
F.last('current_level').alias('current_level'), # 取最后一级值
F.max('churn').alias('churn'),
F.min('ts').alias('min_ts'), # 开始时间戳
F.max('ts').alias('max_ts'), # 结束时间戳
F.last('last_userAgent').alias('last_userAgent'), # 最近的代理
F.min('registration').alias('registration') # 注册日期
)
# sessions的频率
.withColumn('session_freq', F.col('session_count')/((F.col('max_ts')-F.col('min_ts'))/TS_COEF))
# 每一阶段的平均歌曲数量
.withColumn('song_per_session', F.col('song_count')/F.col('session_count'))
# 二分类变量: Male = 1/0
.withColumn('gender_Male', (F.col('gender')=='M').cast(IntegerType()))
# 二分类变量: paid = 1/0
.withColumn('is_paid', (F.col('current_level')=='paid').cast(IntegerType()))
# lifetime
.withColumn('lifetime', (F.col('max_ts')-F.col('registration'))/TS_COEF)
# 从代理中提取设备/操作系统
.withColumn('agent_Windows', F.col('last_userAgent').contains('Windows').cast(IntegerType()))
.withColumn('agent_Mac', F.col('last_userAgent').contains('Mac').cast(IntegerType()))
.withColumn('agent_iPhone', F.col('last_userAgent').contains('iPhone').cast(IntegerType()))
.withColumn('agent_iPad', F.col('last_userAgent').contains('iPad').cast(IntegerType()))
.withColumn('agent_Linux', F.col('last_userAgent').contains('Linix').cast(IntegerType()))
).cache()
return preprocessed_df
preprocessed_df = preprocess_data(df)
preprocessed_df.count()
第2步:应用TF-IDF
对列表应用TF-IDF转换:歌曲、艺术家、页面事件。对于歌曲和艺术家,我们只保留前100名的数值,页面事件全部包括在内(因为总共只有22个数值)。
def tf_idf_transformer(list_name: str,
vocabSize: int=100):
"""
结合TF和IDF pyspark transformer
------------
Args:
List_name (string) :工作列表格式为prefix_list的特性的前缀
vocabSize (int) :要保留的最高输出单词数
Return:
Tf transformer,idf transformer
"""
tf = CountVectorizer(inputCol=f"{list_name}_list", outputCol=f"TF_{list_name}", vocabSize=vocabSize)
tf_idf = IDF(inputCol=f"TF_{list_name}", outputCol=f"TFIDF_{list_name}")
return tf, tf_idf
artist_tf, artist_tf_idf = tf_idf_transformer('artist')
song_tf, song_tf_idf = tf_idf_transformer('song')
page_tf, page_tf_idf = tf_idf_transformer('page')
assembler = VectorAssembler(inputCols=["TFIDF_artist", "TFIDF_song", "TFIDF_page",
"session_freq", "song_per_session",
"lifetime", "gender_Male",
"is_paid", "agent_Windows",
"agent_Mac", "agent_iPhone", "agent_iPad",
"agent_Linux"],
outputCol="features",
handleInvalid="skip")
feature_pipeline = Pipeline(stages=[artist_tf, artist_tf_idf,
song_tf, song_tf_idf,
page_tf, page_tf_idf,
assembler
])
test = feature_pipeline.fit(preprocessed_df)
test_df = test.transform(preprocessed_df)
test_df.count()
特征工程是通过 pyspark.ml.feature实现,并作为一个阶段纳入建模管道。
第3步:提取特征词汇
从特征转换器中提取特征名称和词汇,以便稍后用于特征重要性分析
# 提取词汇表以便将来进行解释
stages = test.stages
vectorizers = [s for s in stages if isinstance(s, CountVectorizerModel)]
vocab_dict = {}
vocab_dict['artist'] = vectorizers[0].vocabulary
vocab_dict['song'] = vectorizers[1].vocabulary
vocab_dict['page'] = vectorizers[2].vocabulary
# 在向量汇编器之后提取特征名称
attrs = sorted(
(attr["idx"], attr["name"]) for attr in (chain(*test_df
.schema["features"]
.metadata["ml_attr"]["attrs"].values())))
步骤三 建模方法
客户流失预测是一个二分类问题,所以我们考虑了pyspark.ml.classification中可用的分类器。由于大部分特征来自于分类数据(歌曲、艺术家、网页),我们决定使用基于树的模型。重点比较了两种算法。
- 随机森林分类器
- 梯度增强的树分类器
两个模型都使用了相同的数据(70%的训练记录和30%的测试记录通过随机分割得到)。
(train_data, test_data) = preprocessed_df.randomSplit([0.7, 0.3], seed=10)
# cache dataframes
train_data = train_data.cache()
test_data = test_data.cache()
我们使用网格搜索来寻找更好的超参数,网格搜索的设置。
- 随机森林分类器。最大树深:[5, 7],树的数量:[50, 100]
- 梯度增强树分类器。最大树深:[3, 5],迭代次数:[5, 10]
3倍交叉验证被用来测量平均F1-score。以下是为RF分类器管道设置网格搜索的示例代码。
Random Forest Classifier
%%time
# 优化模型
rf = RandomForestClassifier(labelCol="churn", featuresCol="features",
seed = 10)
rf_pipeline = Pipeline(stages=[feature_pipeline, rf])
# 设置参数网格
paramGrid = (ParamGridBuilder()
.addGrid(rf.maxDepth, [5, 7])
.addGrid(rf.numTrees, [20, 30])
.build()
)
# 选择评估者
evaluator = MulticlassClassificationEvaluator(labelCol="churn",
predictionCol="prediction",
metricName="f1")
# 定义交叉验证器
crossval = CrossValidator(estimator=rf_pipeline,
estimatorParamMaps=paramGrid,
evaluator=evaluator,
numFolds=3,
seed=10)
# 运行交叉验证器
cvModel = crossval.fit(train_data)
# 检查参数的最佳组合
cvModel.getEstimatorParamMaps()[ np.argmax(cvModel.avgMetrics) ]
Gradient Boosted Tree classifier
%%time
# 优化模型
gbt = GBTClassifier(labelCol="churn", featuresCol="features")
gbt_pipeline = Pipeline(stages=[feature_pipeline, gbt])
# 设置参数网格
paramGrid = (ParamGridBuilder()
.addGrid(gbt.maxDepth, [3, 5])
.addGrid(gbt.maxIter, [5, 10])
.build()
)
# 选择评估者
evaluator = MulticlassClassificationEvaluator(labelCol="churn",
predictionCol="prediction",
metricName="f1")
# 定义交叉验证器
crossval = CrossValidator(estimator=gbt_pipeline,
estimatorParamMaps=paramGrid,
evaluator=evaluator,
numFolds=3,
seed=10)
# 运行交叉验证器
cvModel = crossval.fit(train_data)
# 检查参数的最佳组合
cvModel.getEstimatorParamMaps()[ np.argmax(cvModel.avgMetrics) ]
步骤四 分析结果
评估结果
我们通过F1-score和召回率来比较2个优化的网格搜索模型。
def score_the_model(test_data: pyspark.sql.DataFrame,
model: Pipeline,
metric_name: str='accuracy'):
"""
根据 metric_name 中给出的指标计算模型得分
--------------------
Args:
test_data(pyspark DataFrame):带有测试样例的数据框架
model(Pipeline) :预训练模型
metric_name(string) : MulticlassClassificationEvaluator指标之一
Return:
None
"""
# 作出预测
predictions = model.transform(test_data)
# 设置评估器并计算分数
evaluator = MulticlassClassificationEvaluator(
labelCol="churn",
predictionCol="prediction",
metricName=metric_name)
score = evaluator.evaluate(predictions)
print("Score = ", score)
score_the_model(test_data, cvModel, metric_name='f1')
score_the_model(test_data, cvModel, metric_name='accuracy')

两个模型都显示出相当好的分数(召回率>80%,F1-score>75%)。由于完整数据集的交叉验证是一个耗时的过程(运行时间大于1小时),我们检查了有限数量的参数组合。我们看到,最好的GBT模型是在树的深度和迭代次数的最高选项下得到的,因此我们认为增加这两个参数可以得到更高的模型质量。
特征重要性
def rename(x: str, vocab_dict: Dict) -> str:
"""
根据词汇表重命名原始属性名称
----------------
Args:
X(string) :原始名称
vocab_dict(字典) :包含所有词汇的字典
Return:
string: 新名称
"""
if 'TFIDF' in x:
components = x.split('_')
new_components = components[:-1]
new_components.append(vocab_dict[components[1]][int(components[-1])])
new_x = '_'.join(new_components)
else:
new_x = x
return new_x
feature_importance_tab = pd.DataFrame([(name, persistedModel.stages[-1].featureImportances[idx])
for idx, name in attrs
if persistedModel.stages[-1].featureImportances[idx]],
columns=['feature_name_raw', 'importance'])
feature_importance_tab['feature_name'] = feature_importance_tab['feature_name_raw'].apply(lambda x: rename(x, vocab_dict))
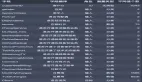
feature_importance_tab.sort_values(by='importance', ascending=False)[:20]

图5.随机森林和梯度增强树分类器的前10个最重要特征
从图5中我们可以清楚地看到,会话的频率在两个模型中都是主导因素。另一个重要的特征是寿命。与这两个模型相比,RF模型的所有特征的优先级都降低了,对于GBT来说,我们看到页面事件的重要性相当高,这很好,因为会话频率和寿命对于新用户来说是误导性的因素(由于观察的数量少)。我们还可以注意到,最重要的是与用户忠诚度/满意度有关的页面事件:例如,喜欢/不喜欢,添加好友,升级/降级。
步骤五 总结
即使在树的深度和迭代次数较少的情况下,梯度增强的树也表现出较好的质量。
可以考虑采取以下步骤来改进模型。
- 以更高的迭代次数和树形深度运行GBT的网格搜索。
- 将来自特征管道的词汇大小纳入网格搜索。
- 添加地理定位特征(本数据集省略)。
- 平衡数据集:如果数据量足够,我们可以对活跃(target=0)和流失(target=1)的用户进行类似数量的采样。
- 使交叉验证和训练-测试分割与时间相关。因为我们要用过去的数据来学习模型,用未来几天-几周的数据来预测流失率,所以我们可以改变数据集的收集方法,从用户级别改为用户+日期级别。例如,我们可以按用户身份和星期来汇总数据。在按训练/测试分割数据时,我们应该避免打乱,并将其分割为过去/未来,类似于交叉验证,我们应该应用时间序列交叉验证。
为了帮助企业有效地使用模型,我们提出了3个需要考虑的问题。
- 我们可以使用2种类型的模型结果:预测1/0和结果=1的预测概率。使用预测的概率,我们可以将潜在的流失者划分为低中高(从分布中选择阈值),并向他们提出不同的优惠/折扣。
- 我们应该注意新用户的情况。通常情况下,由于新用户的事件观察量较低,模型预测的准确性较低。我们建议开始对与我们在一起至少N天的用户使用模型(这个N应该是业务驱动的,取决于漏斗和保留)。对于新用户的保留策略应该是不同的。
- 使用流失率预测模型和LTV预测模型来选择相关的报价将是非常有用的。