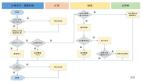
1.什么是Leader选举
首先,Zookeeper 集群节点由三种角色组成,分别是:

Leader,负责所有事务请求的处理,以及过半提交的投票发起和决策。
Follower,负责接收客户端的非事务请求,而事务请求会转发给 Leader 节点来处理, 另外,Follower 节点还会参与 Leader 选举的投票。
Observer,负责接收客户端的非事务请求,事务请求会转发给 Leader 节点来处理,Observer 节点不参与任何投票,只是为了扩展 Zookeeper 集群来分担读操作的压力。

其次,Zookeeper 集群是一种典型的中心化架构,也就是会有一个 Leader 作为决策节点,专门负责事务请求的处理和数据的同步。这种架构的好处是可以减少集群架构里面数据同步的复杂度,集群管理会更加简单和稳定。
但是,会带来 Leader 选举的一个问题,也就是说,如果 Leader 节点宕机了,为了保证集群继续提供可靠的服务,Zookeeper 需要从剩下的 Follower 节点里面去选举一个新的节点作为Leader,也就是所谓的 Leader 选举。

2.选举原理
接下来,给大家介绍一下Zookeeper的选举原理。
首先呢,Zookeeper中的每一个节点都会向集群里面的其他节点发送一个票据 Vote,这个票据有三个属性。
epoch, 逻辑时钟,用来表示当前票据是否过期。
zxid,事务 id,表示当前节点最新存储的数据的事务编号
myid,服务器 id,在 myid 文件里面填写的数字。
每个节点都会选自己当 Leader,所以第一次投票的时候携带的是当前节点的信息。
接下来每个节点用收到的票据和自己节点的票据做比较,根据 epoch、zxid、myid的顺序逐一比较,以值最大的一方获胜。比较结束以后这个节点下次再投票的时候,发送的投票请求就是获胜的 Vote 信息。

然后,通过多轮投票以后,每个节点都会去统计当前达成一致的票据,以少数服从多数的方式,最终获得票据最多的节点成为 Leader。
最后我再补充一下,为什么要选择 epoch/zxid/myid 作为投票评判依据?我是这么理解的。
首先,epoch ,因为网络通信延迟的可能性,有可能在新一轮的投票里面收到上一轮投票的票据,这种数据应该丢弃,否则会影响投票的结果和效率。
然后,zxid 越大,说明这个节点的数据越接近 leader,所以用 zxid 做判断条件是为了避免数据丢失的问题
最后,myid是服务器 id,这个是避免投票时间过长,直接用 myid 最大值作为快速终结投票的属性。
Leader 选举是一个比较复杂的问题,它涉及到集群节点的数据一致性算法。在很多中间件里面都有涉及到类似的问题,这个思想其实还是很有研究价值的。除此之外,还有 Paxos、raft、等一致性算法。
以上就是我对Zookeeper选举原理的理解。