多模态数据(文本、图像、声音)是人类认识、理解和表达世间万物的重要载体。近年来,多模态数据的爆炸性增长促进了内容互联网的繁荣,也带来了大量多模态内容理解和生成的需求。与常见的跨模态理解任务不同,文到图的生成任务是流行的跨模态生成任务,旨在生成与给定文本对应的图像。这一文图生成的任务,极大地释放了AI的想象力,也激发了人类的创意。典型的模型例如OpenAI开发的DALL-E和DALL-E2。近期,业界也训练出了更大、更新的文图生成模型,例如Google提出的Parti和Imagen。
然而,上述模型一般不能用于处理中文的需求,而且上述模型的参数量庞大,很难被开源社区的广大用户直接用来Fine-tune和推理。本次,EasyNLP开源框架再次迎来大升级,集成了先进的文图生成架构Transformer+VQGAN,同时,向开源社区免费开放不同参数量的中文文图生成模型的Checkpoint,以及相应Fine-tune和推理接口。用户可以在我们开放的Checkpoint基础上进行少量领域相关的微调,在不消耗大量计算资源的情况下,就能一键进行各种艺术创作。
EasyNLP是阿里云机器学习PAI 团队基于 PyTorch 开发的易用且丰富的中文NLP算法框架,并且提供了从训练到部署的一站式 NLP 开发体验。EasyNLP 提供了简洁的接口供用户开发 NLP 模型,包括NLP应用 AppZoo 、预训练模型 ModelZoo、数据仓库DataHub等特性。由于跨模态理解和生成需求的不断增加,EasyNLP也支持各种跨模态模型,特别是中文领域的跨模态模型,推向开源社区。例如,在先前的工作中,EasyNLP已经对中文图文检索CLIP模型进行了支持[11] 。我们希望能够服务更多的 NLP 和多模态算法开发者和研究者,也希望和社区一起推动 NLP /多模态技术的发展和模型落地。本文简要介绍文图生成的技术,以及如何在EasyNLP框架中如何轻松实现文图生成,带你秒变艺术家。本文开头的展示图片即为我们模型创作的作品。
文图生成模型简述
下面以几个经典的基于Transformer的工作为例,简单介绍文图生成模型的技术。DALL-E由OpenAI提出,采取两阶段的方法生成图像。在第一阶段,训练一个dVAE(discrete variational autoencoder)的模型将256×256的RGB图片转化为32×32的image token,这一步骤将图片进行信息压缩和离散化,方便进行文本到图像的生成。第二阶段,DALL-E训练一个自回归的Transformer模型,将文本输入转化为上述1024个image token。
由清华大学等单位提出的CogView模型对上述两阶段文图生成的过程进行了进一步的优化。在下图中,CogView采用了sentence piece作为text tokenizer使得输入文本的空间表达更加丰富,并且在模型的Fine-tune过程中采用了多种技术,例如图像的超分、风格迁移等。
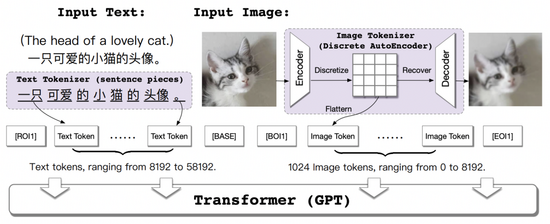
ERNIE-ViLG模型考虑进一步考虑了Transformer模型学习知识的可迁移性,同时学习了从文本生成图像和从图像生成文本这两种任务。其架构图如下所示:
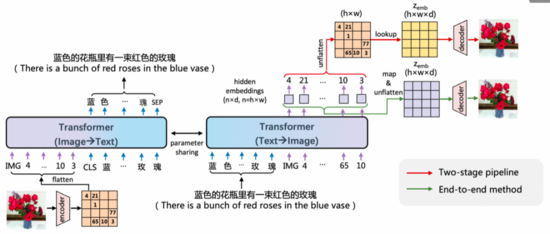
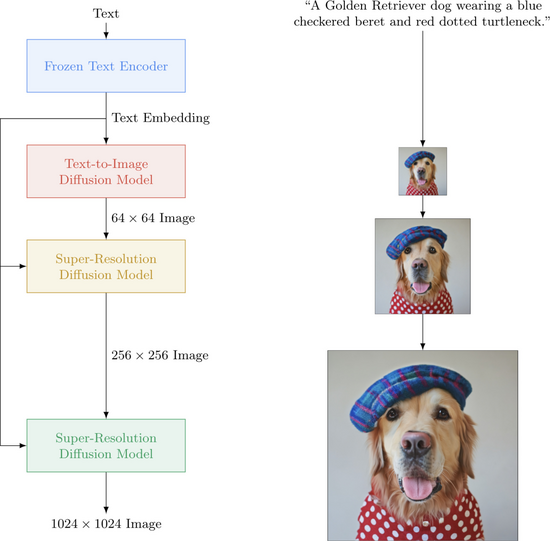
随着文图生成技术的不断发展,新的模型和技术不断涌现。举例来说,OFA将多种跨模态的生成任务统一在同一个模型架构中。DALL-E 2同样由OpenAI提出,是DALL-E模型的升级版,考虑了层次化的图像生成技术,模型利用CLIP encoder作为编码器,更好地融入了CLIP预训练的跨模态表征。Google进一步提出了Diffusion Model的架构,能有效生成高清大图,如下所示:
在本文中,我们不再对这些细节进行赘述。感兴趣的读者可以进一步查阅参考文献。
EasyNLP文图生成模型
由于前述模型的规模往往在数十亿、百亿参数级别,庞大的模型虽然能生成质量较大的图片,然后对计算资源和预训练数据的要求使得这些模型很难在开源社区广泛应用,尤其在需要面向垂直领域的情况下。在本节中,我们详细介绍EasyNLP提供的中文文图生成模型,它在较小参数量的情况下,依然具有良好的文图生成效果。
模型架构
模型框架图如下图所示:
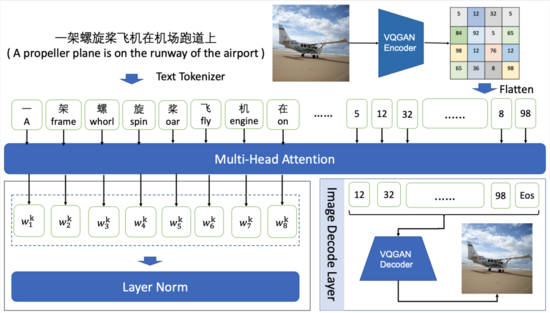
考虑到Transformer模型复杂度随序列长度呈二次方增长,文图生成模型的训练一般以图像矢量量化和自回归训练两阶段结合的方式进行。
图像矢量量化是指将图像进行离散化编码,如将256×256的RGB图像进行16倍降采样,得到16×16的离散化序列,序列中的每个image token对应于codebook中的表示。常见的图像矢量量化方法包括:VQVAE、VQVAE-2和VQGAN等。我们采用VQGAN在ImageNet上训练的f16_16384(16倍降采样,词表大小为16384)的模型权重来生成图像的离散化序列。
自回归训练是指将文本序列和图像序列作为输入,在图像部分,每个image token仅与文本序列的tokens和其之前的image tokens进行attention计算。我们采用GPT作为backbone,能够适应不同模型规模的生成任务。在模型预测阶段,输入文本序列,模型以自回归的方式逐步生成定长的图像序列,再通过VQGAN decoder重构为图像。
开源模型参数设置
在EasyNLP中,我们提供两个版本的中文文图生成模型,模型参数配置如下表:
模型配置 | pai-painter-base-zh | pai-painter-large-zh |
参数量(Parameters) | 202M | 433M |
层数(Number of Layers) | 12 | 24 |
注意力头数(Attention Heads) | 12 | 16 |
隐向量维度(Hidden Size) | 768 | 1024 |
文本长度(Text Length) | 32 | 32 |
图像序列长度(Image Length) | 16 x 16 | 16 x 16 |
图像尺寸(Image Size) | 256 x 256 | 256 x 256 |
VQGAN词表大小(Codebook Size) | 16384 | 16384 |
模型实现
在EasyNLP框架中,我们在模型层构建基于minGPT的backbone构建模型,核心部分如下所示:
self.first_stage_model = VQModel(ckpt_path=vqgan_ckpt_path).eval()
self.transformer = GPT(self.config)
VQModel的Encoding阶段过程为:
# in easynlp/appzoo/text2image_generation/model.py
@torch.no_grad()
def encode_to_z(self, x):
quant_z, _, info = self.first_stage_model.encode(x)
indices = info[2].view(quant_z.shape[0], -1)
return quant_z, indices
x = inputs['image']
x = x.permute(0, 3, 1, 2).to(memory_format=torch.contiguous_format)
# one step to produce the logits
_, z_indices = self.encode_to_z(x) # z_indice: torch.Size([batch_size, 256])
VQModel的Decoding阶段过程为:
# in easynlp/appzoo/text2image_generation/model.py
@torch.no_grad()
def decode_to_img(self, index, zshape):
bhwc = (zshape[0],zshape[2],zshape[3],zshape[1])
quant_z = self.first_stage_model.quantize.get_codebook_entry(
index.reshape(-1), shape=bhwc)
x = self.first_stage_model.decode(quant_z)
return x
# sample为训练阶段的结果生成,与预测阶段的generate类似,详解见下文generate
index_sample = self.sample(z_start_indices, c_indices,
steps=z_indices.shape[1],
)
x_sample = self.decode_to_img(index_sample, quant_z.shape)
Transformer采用minGPT进行构建,输入图像的离散编码,输出文本token。前向传播过程为:
# in easynlp/appzoo/text2image_generation/model.py
def forward(self, inputs):
x = inputs['image']
c = inputs['text']
x = x.permute(0, 3, 1, 2).to(memory_format=torch.contiguous_format)
# one step to produce the logits
_, z_indices = self.encode_to_z(x) # z_indice: torch.Size([batch_size, 256])
c_indices = c
if self.training and self.pkeep < 1.0:
mask = torch.bernoulli(self.pkeep*torch.ones(z_indices.shape,
device=z_indices.device))
mask = mask.round().to(dtype=torch.int64)
r_indices = torch.randint_like(z_indices, self.transformer.config.vocab_size)
a_indices = mask*z_indices+(1-mask)*r_indices
else:
a_indices = z_indices
cz_indices = torch.cat((c_indices, a_indices), dim=1)
# target includes all sequence elements (no need to handle first one
# differently because we are conditioning)
target = z_indices
# make the prediction
logits, _ = self.transformer(cz_indices[:, :-1])
# cut off conditioning outputs - output i corresponds to p(z_i | z_{<i}, c)
logits = logits[:, c_indices.shape[1]-1:]
return logits, target
在预测阶段,输入为文本token, 输出为256*256的图像。首先,将输入文本预处理为token序列:
# in easynlp/appzoo/text2image_generation/predictor.py
def preprocess(self, in_data):
if not in_data:
raise RuntimeError("Input data should not be None.")
if not isinstance(in_data, list):
in_data = [in_data]
rst = {"idx": [], "input_ids": []}
max_seq_length = -1
for record in in_data:
if "sequence_length" not in record:
break
max_seq_length = max(max_seq_length, record["sequence_length"])
max_seq_length = self.sequence_length if (max_seq_length == -1) else max_seq_length
for record in in_data:
text= record[self.first_sequence]
try:
self.MUTEX.acquire()
text_ids = self.tokenizer.convert_tokens_to_ids(self.tokenizer.tokenize(text))
text_ids = text_ids[: self.text_len]
n_pad = self.text_len - len(text_ids)
text_ids += [self.pad_id] * n_pad
text_ids = np.array(text_ids) + self.img_vocab_size
finally:
self.MUTEX.release()
rst["idx"].append(record["idx"])
rst["input_ids"].append(text_ids)
return rst
逐步生成长度为16*16的图像离散token序列:
# in easynlp/appzoo/text2image_generation/model.py
def generate(self, inputs, top_k=100, temperature=1.0):
cidx = inputs
sample = True
steps = 256
for k in range(steps):
x_cond = cidx
logits, _ = self.transformer(x_cond)
# pluck the logits at the final step and scale by temperature
logits = logits[:, -1, :] / temperature
# optionally crop probabilities to only the top k options
if top_k is not None:
logits = self.top_k_logits(logits, top_k)
# apply softmax to convert to probabilities
probs = torch.nn.functional.softmax(logits, dim=-1)
# sample from the distribution or take the most likely
if sample:
ix = torch.multinomial(probs, num_samples=1)
else:
_, ix = torch.topk(probs, k=1, dim=-1)
# append to the sequence and continue
cidx = torch.cat((cidx, ix), dim=1)
img_idx = cidx[:, 32:]
return img_idx
最后,我们调用VQModel的Decoding过程将这些图像离散token序列转换为图像。
模型效果
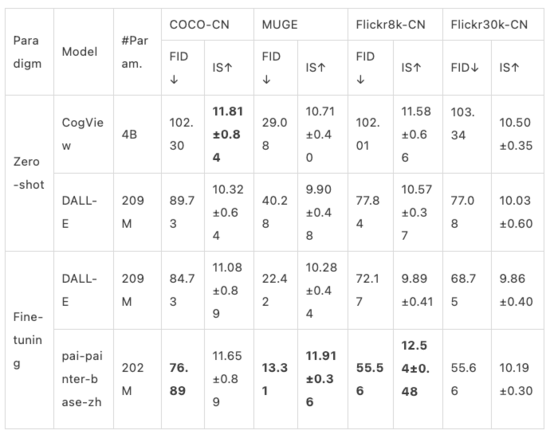
我们在四个中文的公开数据集COCO-CN、MUGE、Flickr8k-CN、Flickr30k-CN上验证了EasyNLP框架中文图生成模型的效果。同时,我们对比了这个模型和CogView、DALL-E的效果,如下所示:
其中:
1)MUGE是天池平台公布的电商场景的中文大规模多模态评测基准[12]。为了方便计算指标,MUGE我们采用valid数据集的结果,其他数据集采用test数据集的结果。
2)CogView源自[13]
3)DALL-E模型没有公开的官方代码。已经公开的部分只包含VQVAE的代码,不包括Transformer部分。我们基于广受关注的[14] 版本的代码和该版本推荐的checkpoits进行复现,checkpoints为2.09亿参数,为OpenAI的DALL-E模型参数量的1/100。(OpenAI版本DALL-E为120亿参数,其中CLIP为4亿参数)。
经典案例
我们分别在自然风景数据集COCO-CN上Fine-tune了base和large级别的模型,如下展示了模型的效果:
示例1:一只俏皮的狗正跑过草地
pai-painter-base-zh | pai-painter-large-zh |
|
|




示例2:一片水域的景色以日落为背景
pai-painter-base-zh | pai-painter-large-zh |
|
|




我们也积累了阿里集团的海量电商商品数据,微调得到了面向电商商品的文图生成模型。效果如下:
示例3:女童套头毛衣打底衫秋冬针织衫童装儿童内搭上衣
pai-painter-base-zh | pai-painter-large-zh |
|
|




示例4:春夏真皮工作鞋女深色软皮久站舒适上班面试职业皮鞋
pai-painter-base-zh | pai-painter-large-zh |
|
|




除了支持特定领域的应用,文图生成也极大地辅助了人类的艺术创作。使用训练得到的模型,我们可以秒变“中国国画艺术大师”,示例如下所示:

更多的示例请欣赏:

使用教程
欣赏了模型生成的作品之后,如果我们想DIY,训练自己的文图生成模型,应该如何进行呢?以下我们简要介绍在EasyNLP框架对预训练的文图生成模型进行Fine-tune和推理。
安装EasyNLP
用户可以直接参考 链接[15] 的说明安装EasyNLP算法框架。
数据准备
首先准备训练数据与验证数据,为tsv文件。这一文件包含以制表符\t分隔的两列,第一列为索引号,第二列为文本,第三列为图片的base64编码。用于测试的输入文件为两列,仅包含索引号和文本。
为了方便开发者,我们也提供了转换图片到base64编码的示例代码:
import base64
from io import BytesIO
from PIL import Image
img = Image.open(fn)
img_buffer = BytesIO()
img.save(img_buffer, format=img.format)
byte_data = img_buffer.getvalue()
base64_str = base64.b64encode(byte_data) # bytes
下列文件已经完成预处理,可用于测试:
# train
https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/painter_text2image/MUGE_train_text_imgbase64.tsv
# valid
https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/painter_text2image/MUGE_val_text_imgbase64.tsv
# test
https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/painter_text2image/MUGE_test.text.tsv
模型训练
我们采用以下命令对模型进行fine-tune:
easynlp \
--mode=train \
--worker_gpu=1 \
--tables=MUGE_val_text_imgbase64.tsv,MUGE_val_text_imgbase64.tsv \
--input_schema=idx:str:1,text:str:1,imgbase64:str:1 \
--first_sequence=text \
--second_sequence=imgbase64 \
--checkpoint_dir=./finetuned_model/ \
--learning_rate=4e-5 \
--epoch_num=1 \
--random_seed=42 \
--logging_steps=100 \
--save_checkpoint_steps=1000 \
--sequence_length=288 \
--micro_batch_size=16 \
--app_name=text2image_generation \
--user_defined_parameters='
pretrain_model_name_or_path=alibaba-pai/pai-painter-large-zh
size=256
text_len=32
img_len=256
img_vocab_size=16384
我们提供base和large两个版本的预训练模型,pretrain_model_name_or_path分别为alibaba-pai/pai-painter-base-zh和alibaba-pai/pai-painter-large-zh。
训练完成后模型被保存到./finetuned_model/。
模型批量推理
模型训练完毕后,我们可以将其用于图像生成,其示例如下:
easynlp \
--mode=predict \
--worker_gpu=1 \
--tables=MUGE_test.text.tsv \
--input_schema=idx:str:1,text:str:1 \
--first_sequence=text \
--outputs=./T2I_outputs.tsv \
--output_schema=idx,text,gen_imgbase64 \
--checkpoint_dir=./finetuned_model/ \
--sequence_length=288 \
--micro_batch_size=8 \
--app_name=text2image_generation \
--user_defined_parameters='
size=256
text_len=32
img_len=256
img_vocab_size=16384
结果存储在一个tsv文件中,每行对应输入中的一个文本,输出的图像以base64编码。
使用Pipeline接口快速体验文图生成效果
为了进一步方便开发者使用,我们在EasyNLP框架内也实现了Inference Pipeline功能。用户可以使用如下命令调用Fine-tune过的电商场景下的文图生成模型:
# 直接构建pipeline
default_ecommercial_pipeline = pipeline("pai-painter-commercial-base-zh")
# 模型预测
data = ["宽松T恤"]
results = default_ecommercial_pipeline(data) # results的每一条是生成图像的base64编码
# base64转换为图像
def base64_to_image(imgbase64_str):
image = Image.open(BytesIO(base64.urlsafe_b64decode(imgbase64_str)))
return image
# 保存以文本命名的图像
for text, result in zip(data, results):
imgpath = '{}.png'.format(text)
imgbase64_str = result['gen_imgbase64']
image = base64_to_image(imgbase64_str)
image.save(imgpath)
print('text: {}, save generated image: {}'.format(text, imgpath))
除了电商场景,我们还提供了以下场景的模型:
自然风光场景:“pai-painter-scenery-base-zh”
中国山水画场景:“pai-painter-painting-base-zh”
在上面的代码当中替换“pai-painter-commercial-base-zh”,就可以直接体验,欢迎试用。
对于用户Fine-tune的文图生成模型,我们也开放了自定义模型加载的Pipeline接口:
# 加载模型,构建pipeline
local_model_path = ...
text_to_image_pipeline = pipeline("text2image_generation", local_model_path)
# 模型预测
data = ["xxxx"]
results = text_to_image_pipeline(data) # results的每一条是生成图像的base64编码
在这一期的工作中,我们在EasyNLP框架中集成了中文文图生成功能,同时开放了模型的Checkpoint,方便开源社区用户在资源有限情况下进行少量领域相关的微调,进行各种艺术创作。在未来,我们计划在EasyNLP框架中推出更多相关模型,敬请期待。我们也将在EasyNLP框架中集成更多SOTA模型(特别是中文模型),来支持各种NLP和多模态任务。此外,阿里云机器学习PAI团队也在持续推进中文多模态模型的自研工作,欢迎用户持续关注我们,也欢迎加入我们的开源社区,共建中文NLP和多模态算法库!
Github地址: https://github.com/alibaba/EasyNLP