













最近组里又来了一个需求:当告警发生时,将告警信息通过企业微信发送给开发的相关负责人,方便尽快排除故障。实际使用Alertmanager来完成这项工作,下面介绍具体的实现方法。
详细配置
- 告警通道配置
监控最重要的是在故障发生时,能将告警信息发送出来,让正确的人第一时间获悉故障的详情,只有这样才能尽快排除故障。企业微信很多公司都有使用,而且Alertmanager支持将企业微信作为告警通道。
按照企业微信的官方文档来配置告警通道,如果觉得麻烦,可以在浏览器上搜索“alertmanager 企业微信”关键字,就有很多配置例子展示。我们需要得到下面五个键值对:
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'wechat_api_corp_id: '12345678'agent_id: 12345678api_secret: 12345678to_tag: 4
这五个键值对需要在Alertmanager中配置,后面四个键的值根据实际情况填写。
企业微信有三种ID来选择消息的接收对象:用户ID、部门ID和标签ID。因为第三种方式支持同时包含用户和部门,使用起来比较灵活,这里选择第三种方式。

标签ID
点击“标签详情”,可以看到标签ID,在配置Alertmanager时会用到。
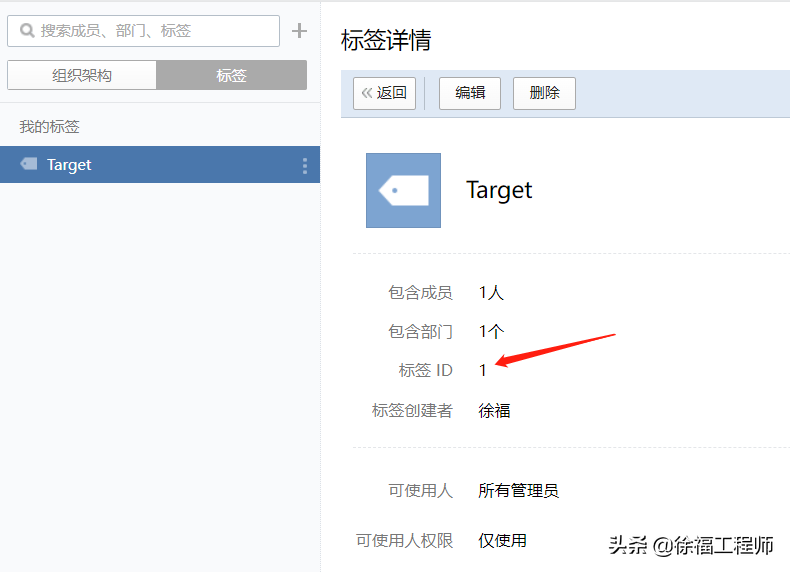
标签ID显示
- Blackbox配置
这里直接将配置文件贴出。
docker-compose.yaml:
version: '3.3'services: blackbox_exporter: image: prom/blackbox-exporter:v0.19.0 ports: - "9115:9115" restart: always volumes: - "./config:/config" command: "--config.file=/config/blackbox.yaml"
config/blackbox.yaml:
modules: http_get: prober: http timeout: 5s http: valid_http_versions: ["HTTP/1.1", "HTTP/2.0"] valid_status_codes: [200] no_follow_redirects: false tls_config: insecure_skip_verify: true
- Alertmanager配置
这里是关键,因为告警通知的发送控制都由Alertmanager来控制。配置文件如下。
docker-compose.yaml:
alertmanager: image: bitnami/alertmanager:0 restart: "always" ports: - 9093:9093 container_name: "alertmanager" volumes: - "./config:/etc/alertmanager"
config/config.yml:
global: resolve_timeout: 5m wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' wechat_api_corp_id: '1234567'templates: - '/etc/alertmanager/*.tmpl'route: receiver: wechat group_wait: 1s group_interval: 1s repeat_interval: 2s group_by: [adm] routes: - matchers: - adm="search" receiver: searchEngine group_wait: 10s - matchers: - adm="portalweb" receiver: portalWeb group_wait: 10sreceivers:- name: wechat wechat_configs: - to_tag: infra message: '{{ template "wechat.message" . }}' agent_id: 1000002 message_type: markdown api_secret: verylongstring- name: searchEngine wechat_configs: - to_tag: searchdep message: '{{ template "wechat.message" . }}' agent_id: 1000002 message_type: markdown api_secret: verylongstring- name: portalWeb wechat_configs: - to_tag: portalwebdep message: '{{ template "wechat.message" . }}' agent_id: 1000002 message_type: markdown api_secret: verylongstring
有几个参数需要介绍下:
group_wait:Alertmanager 在接收到一条新的告警(第一次出现的告警)时,将这条告警发送给 receiver 之前需要等待的时间。
group_interval:对于一条已经出现过的告警,alertmanager 每隔 group_interval 时间检查一次告警。
repeat_interval: 对于一条已经出现过的告警,每隔 repeat_interval 会重新发送给 receiver。
有篇文档整理得很好,这里直接列出来。
“Alertmanager 在收到一条新的告警之后,会等待 group_wait 时间,对这条新的告警做一些分组、更新、静默的操作。当第一条告警经过 group_wait 时间之后,Alertmanager 会每隔 group_interval 时间检查一次这条告警,判断是否需要对这条告警进行一些操作,当 Alertmanager 经过 n 次 group_interval 的检查后,n*group_interval 恰好大于 repeat_interval 的时候,Alertmanager 才会将这条告警再次发送给对应的 receiver。”
文中这三个参数配置的值很小,主要为测试目的,生产环境根据需要配置。
还有一点需要注意,Alertmanager子路由(即routes里面)中配置的参数会覆盖根路由(即route里面)中配置的参数,所以按照文件“config/config.yml”中的配置,如果一条告警发送到了“searchEngine”,就不可能再发送给默认的接收者“wechat”,除非子路由没有匹配。
告警模板文件:config/wechat.tmpl。
{{ define "wechat.message" }}{{- if gt (len .Alerts.Firing) 0 -}}{{- range $index, $alert := .Alerts -}}{{- if eq $index 0 -}}# 报警项: {{ $alert.Labels.alertname }}{{- end }}> `**===告警详情===**` > 告警级别: {{ $alert.Labels.severity }}> 告警详情: <font color="comment">{{ index $alert.Annotations "description" }}{{ $alert.Annotations.message }}</font>> 故障时间: <font color="warning">{{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}</font>> 故障实例: <font color="info">{{ $alert.Labels.instance }}</font>{{- end }}{{- end }}{{- if gt (len .Alerts.Resolved) 0 -}}{{- range $index, $alert := .Alerts -}}{{- if eq $index 0 -}}# 恢复项: {{ $alert.Labels.alertname }}{{- end }}> `===恢复详情===` > 告警级别: {{ $alert.Labels.severity }}> 告警详情: <font color="comment">{{ index $alert.Annotations "description" }}{{ $alert.Annotations.message }}</font>> 故障时间: <font color="warning">{{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}</font>> 恢复时间: <font color="warning">{{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}</font>> 故障实例: <font color="info">{{ $alert.Labels.instance }}</font>{{- end }}{{- end }}{{- end }}其中语句“{{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}”是将时间转换成北京时间,否则默认显示的是UTC时间,不利于故障发生时间的查看。
配置完Alertmanager,再看Prometheus的配置。
- Prometheus配置
Prometheus需要增加告警规则文件,所有待监控的metrics都保存在Prometheus中,但它并不知道metrics的值处于什么状态的情况下,自己要发告警给Alertmanager,所以要通过增加告警规则文件告知Prometheus,各个配置文件如下,
docker-compose.yaml:
version: '3.3'services: prometheus: image: prom/prometheus restart: always ports: - "9090:9090" volumes: - "./config:/config" command: --config.file=/config/prometheus.yaml
Prometheus的配置文件,config/prometheus.yaml:
# my global configglobal: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s).# Alertmanager configurationalerting: alertmanagers: - static_configs: - targets: - 192.168.52.128:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.rule_files: - /config/alerts.rules # A scrape configuration containing exactly one endpoint to scrape:# Here it's Prometheus itself.scrape_configs: - job_name: 'web-monitor' scrape_interval: 1m metrics_path: /probe params: module: [http_get] static_configs: - targets: - https://www.baidu.com - https://cn.bing.com labels: adm: "search" - targets: - https://www.163.com - https://www.ifeng.com labels: adm: "portalweb" relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: 192.168.52.128:9115 # The blackbox exporter's real hostname:port.
Prometheus的告警规则文件,config/alerts.rules:
groups: - name: Web监控 rules: - alert: Web API不能访问 expr: probe_success == 0 for: 10s labels: severity: 非常严重 annotations: summary: "{{$labels.instance}}:链接不能访问" description: "{{$labels.instance}}:链接超过10s无法连接"
到这里,所有的配置已经完成,看下效果:
效果展示
在Prometheus上查看probe_success metric的值,看到此时链接“https://www.163.com”访问异常(当然不是真的有问题,可以使用一些手段模拟)。

prometheus查看
查看Alertmanager Web界面,也收到了Prometheus发送过来的告警信息。
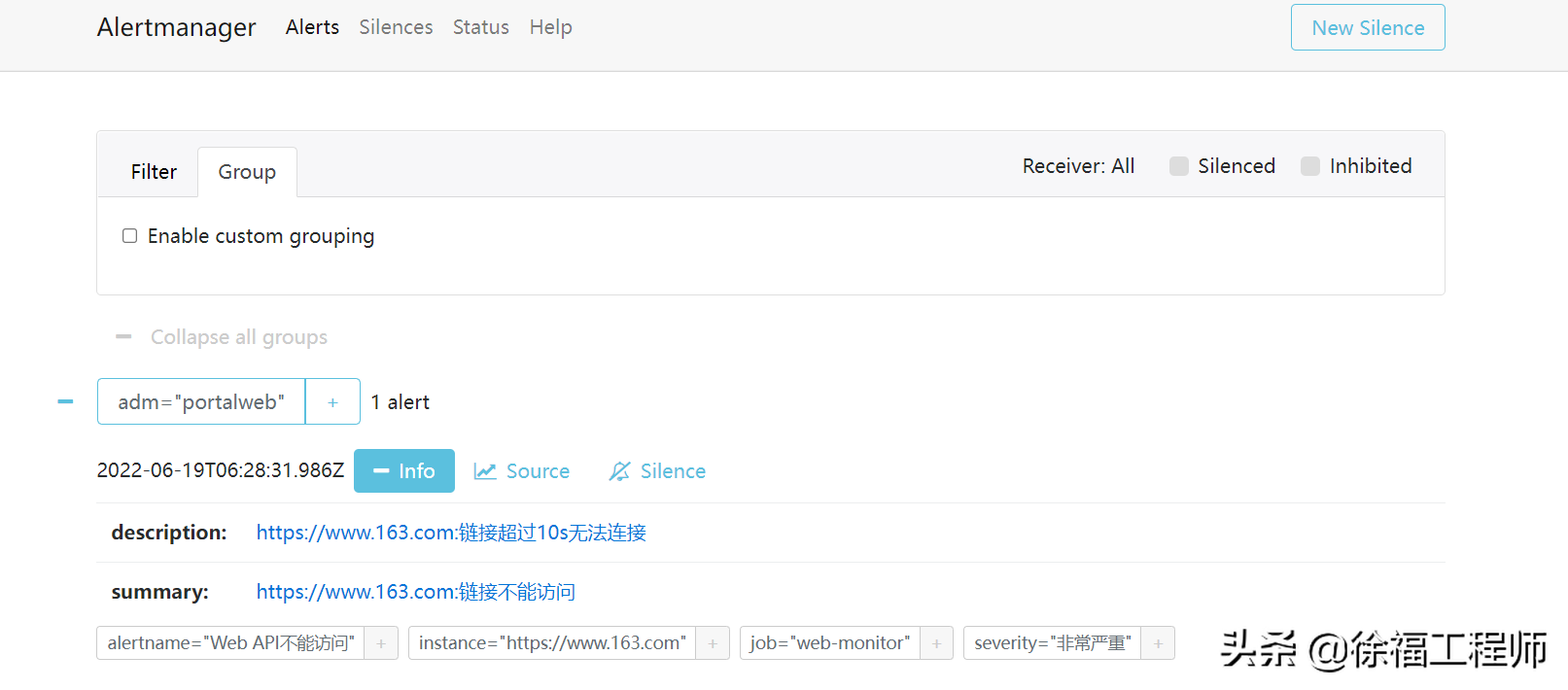
Alertmanager告警详情
企业微信告警信息如下。
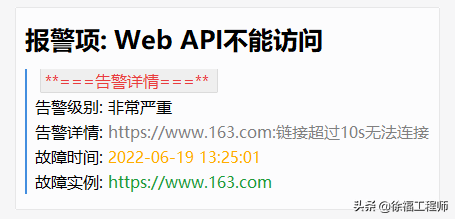
企业微信告警
总结
依赖企业微信和Alertmanager便实现根据告警详情指定告警接收人的配置。
















