2021年7月13日,劳累了一天的年轻人们,正准备躺平拿出手机,打开那熟悉的小破站App,一键三连自己最喜爱的up主的最新视频。
结果突然发现,自己的眼前一黑:

时隔一年,B站终于揭晓了这其中的奥秘:一个「诡计多端的0」。

不过,你有没有想过,即便是经历着用户的疯狂涌入,为啥这个微博,它没崩呢?

AI和微博有啥关系?
在揭开这个谜底之前,还需要从人工智能的发展说起。
7月27日,由中国互联网协会指导、微博和新浪新闻主办的「融合生态 价值共创」2022新智者大会顺利召开。
在「智驱万物:AI推动万物互联的加速到来」议题中,微博COO、新浪移动CEO、新浪AI媒体研究院院长王巍发表了题为《云为数智 技术融合应用 赋能微博复杂业务场景》的主题演讲。
王巍表示,如果我们回顾机器学习的发展历程,可以看出AI的总体发展趋势是:训练数据的海量化及多样化,AI模型的复杂化及通用化,算力的高效化及规模化。

第一,是多模态数据融合。
随着5G的快速发展,图片、视频类型模态内容在网络内容中占比越来越高,所以进行模态融合非常必要。
对于微博来说,如果能同时对文本、图片、视频进行多模态融合,也就可以更好理解这条微博所讲的内容了。
第二,是超大规模图计算。
相对其他机器学习模型,超大规模图计算有个特殊的优势:通过信息在网络中的传递,促进信息的流动、汇聚与集成。
比如对于行为少的冷启动用户,我们可以通过他关注列表中的人,以及这些人发布的内容,通过信息传播来推导这个用户的兴趣。

第三,是AI研发的哑铃模式。
目前的AI研发重点,一个是越来越大的超级大模型,一个是模型小型化技术。
我们都知道,目前随着模型参数规模越来越大,模型效果越来越好,高精度模型仍然在持续增大,比如2018年Google的Bert刚出来的时候,模型参数规模是3亿,不算太大,但是之后这个数字一直在飞速增长。
OpenAI研发的GPT-2模型,参数规模15亿,GPT-3模型,参数规模1750亿,而到了2021年Google发布的Switch Transformer,参数规模已经达到了1.6万亿。

另一方面,虽然说模型越大效果越好,但是因为模型过大,有时会导致无法让实际应用落地。所以研发的另外一个重点,是将这些大模型小型化、轻量化,比如模型蒸馏、模型剪枝等技术。
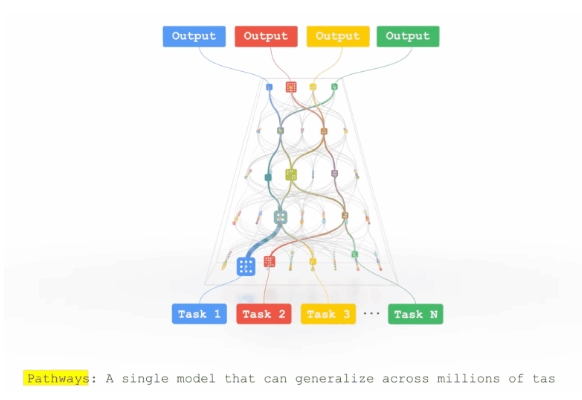
第四,是AI模型从专用模型走向通用模型。
谷歌在2021年下半年公开了Pathways模型框架,首先提出了这一构想,希望通过构造一个通用的大模型,达到「一个模型做千万件事」的目标。
具体的思路是,不同任务数据输入后,通过路由算法,选择神经网络的部分路径,到达模型输出层。不同任务既有参数共享,也有任务独有的模型参数。
10亿节点+100亿边的超大规模图
为何讲了这么半天机器学习?因为接下来要登场的,就是「微博特色推荐系统」了。
众所周知,作为国内最大的社交媒体网络,微博目前的月活用户已经达到5.82亿了!这样大的用户规模,必然会让微博上的网络环境十分复杂。
再加上内容时效性强、多样性高,现在的网络大事都会第一时间在微博上引爆。
另外,微博面临的场景还很多元化,需要在关系流、热点流、视频流等众多场景中给用户分发他们感兴趣的「千人千面」的内容。

我可以没有手指,但不能没有手机
面对复杂的业务场景,微博是怎样通过AI和大数据,做出能随机应变的推荐系统的呢?
王巍向我们介绍说,微博推荐系统整体由三部分构成:内容理解、用户理解,以及推荐系统。
首先,是内容理解。
如果要想搞明白一个微博到底在说什么,仅仅理解文本内容是不够的,必须采用多模态理解技术,融合博文、图片、视频等多种媒体信息。
为此,微博训练了自己的微博多模态预训练模型,通过「对比学习」,用这种自监督学习方法,来进行多模态预训练。
下图的这例子就展示了微博是怎样利用自带的「话题」来自动构造训练数据的。

比如,我们把两个都写着「训练中的拉什福德」的微博当作正例,随机选择一些不同话题的微博作为负例,这样就能自动构造训练数据。
对于某条微博,其中的文本内容通过Bert编码,图像和视频内容通过ViT编码,然后通过fusion子网络进行信息融合,形成微博的embedding编码。这就是一种预训练过程。
经过预训练,学好的微博编码器可以拿来对新的微博内容进行多模态编码,形成embedding,应用在推荐等下游任务中。
其次,在用户理解方面,微博采取了超大规模图计算,来更好地理解用户的阅读兴趣。毕竟微博自带社交媒体属性,天然地就和大规模图计算非常匹配。
利用用户和博文作为图中的节点,以用户间的关注关系、用户和博文的阅读及转评赞等互动行为构造图中的边,微博建立起了包含10亿规模节点、100亿规模边的超大规模图。
通过大规模图计算中的信息传播、汇聚和集成,形成表征用户兴趣的embedding向量,可以更好地理解用户兴趣。
如此一来,也就可以同时搞定用户之间的关注关系、用户和博文的转评赞等等的互动行为了。
在理解了用户在讲什么、理解了微博用户的兴趣之后,微博推荐系统就会将高质量的微博,个性化地分发给感兴趣的用户。
那么,如何在这种复杂场景下构造高效率的推荐系统呢?
微博采取的是采取了多场景建模的方式。最理想的情况是,只构建一个推荐模型,用它来服务多个场景。
那么如何表示场景间的共性和个性呢?可以通过网络参数在场景间共享,或者场景自己独享私有网络参数,来体现场景的共性与个性。

比如这张模型图,在模型的底层特征输入层,以及网络中间的一部分「专家子网络」,这些网络参数是各个场景共享的;而其他子网络参数则是某个场景所独有的
通过这种方式,就能够通过一个模型服务多个场景,节省模型资源。
唐山事件:流量暴涨一倍怎么办?
现在,说回到最初的那个「悬念」上来。
对于微博来说,这个保不齐什么时候就会「炸」的热点,一直以来都是非常大的挑战。
比如,最近全民关注的「唐山事件」,事件当天的热点流量,比日常流量峰值翻了整整一倍。

对此王巍表示,微博在很早就应用了微服务+Docker容器化技术,不仅提升服务运维的效率,而且还实现了服务动态扩缩容能力。当前,微博已经具备了10分钟调度超过一万台的扩容能力,可以有足够的服务器来应对热点流量。
此外,微博还建立了热点监测机制和热点联动体系,并通过微博自研的Weibo Mesh技术,实现不同服务间跨语言的高效调用,提升整体服务的性能,和联动扩容效率。
最后,微博采用了在离线实时混合部署技术。利用CPU实时抢占式调度技术与容器化技术相结合,实现微博服务在离线实时混合部署能力。

综合了上面这些操作之后,在有热点流量来袭时,就可以秒级承接核心服务的热点流量了。最后,让我们再来回顾下互联网的发展历程。
如果说PC互联网是网络世界的开端,那么移动互联网的兴起则让我们将这无形的信息空间装进了口袋。随着大数据、云计算、人工智能等技术与移动互联网的叠加融合,我们进入了智能信息时代。
而现在,最火的话题就要数元宇宙了。从去年开始,元宇宙就引发了广泛的讨论,比如数字孪生、数字人、XR、区块链技术等。
王巍认为,目前基于AI、区块链、XR等前沿技术的应用场景,已经体现了一些元宇宙的雏形。诸如游戏、社交等领域,都是元宇宙非常好的应用场景,会引爆大家参与元宇宙的热情。