日志异常检测技术背景及意义
在信息化技术飞快发展的今天,计算机网络规模越来越大,无论是金融、电信、能源行业,还是工业制造、互联网、物联网等,都非常依赖网络。政府、各大企业、金融机构和科研院校所等企事业单位的业务大都建立在计算机网络之上。随着信创产业的蓬勃发展,国产操作系统依托开源生态和政策东风正快速崛起,涌现出了一大批以 Linux为主要架构为国产操作系统,如中科方德、银河麒麟、深度 Deepin、华为鸿蒙等,未来的广阔发展前景值得期待。但是由于国产操作系统刚刚起步,生态还不成熟,系统会面临各种各样的恶意攻击、内部威胁以及数据泄露等等,这些恶意行为造成的损失是非常巨大的,给个人和国家信息安全也造成了很大的威胁。
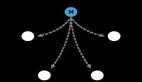
操作系统运行过程如图1所示,故障根因出现导致系统运行状态异常,在异常出现一段时间后导致系统发生故障,通过系统修复恢复系统正常运行状态,这些事件发生是有先后顺序的。因此,为了阻止或规避故障发生,减少故障造成的损失,当务之急是设计一套行之有效的操作系统运行状态检测方法,维持操作系统正常运转。

图 1 系统运行状态图
操作系统运行时产生的数据可以表征系统的运行状态,通过对这些数据进行挖掘分析,可以对系统异常运行状态进行诊断。系统运行状态监控的数据源主要是KPI(Key Performance Indicator)数据。例如,CPU 使用状态、磁盘IO状态、文件分区状态、网络接口状态、进程状态及内存使用状态等,这类数据反映了操作系统内各类资源的使用情况。但是现实中,随着监控的对象增多,比如服务器、虚拟机、容器、硬盘、TOR 交换机、聚合交换机、路由器、数据库、中间件等,出现的故障类型也越来越多,很多异常情况与 KPI 数据异常并无一一对应的关联关系。因此需要对系统进行更加详细精准的监控,操作系统的运行状态日志数据就是一种极好的监控数据源。日志数据通常是系统开发人员在应用程序开发时根据程序执行逻辑就已经嵌入了相关打印输出语句,是应用程序在运行过程中调用打印语句对变量信息和程序执行状态进行记录的一类数据,记录了异常或故障发生时的上下文信息[1]。
目前基于国产操作系统日志进行异常检测的研究还很少。一方面,随着操作系统和应用程序的复杂程度越来越高,传统的基于关键字匹配或者静态规则匹配的方式只能检测到现有的异常事件,缺乏灵活性,容易产生漏报警。另一方面,使用机器学习和深度学习等自动化的检测方法对日志进行异常分析时,首要工作是将非结构化的日志文本解析成结构化信息后进行日志向量化工作。为了增加程序开发人员以及用户对日志的可读性,国产操作系统中添加了中文日志,这种跨语言的日志文本的表征工作是目前日志异常检测研究工作的一大挑战。另 外,如何充分结合日志数据特性对日志异常检测任务进行优化和改进,提升模型的检测性能是目前研究的另一大挑战。现有异常检测算法大多关注的异常种类不同,因此适用范围也各不相同。基于此,本文在现有对日志研究的基础上,通过分析国产操作系统日志文本数据的特征,利用数据挖掘分析手段,建立异常检测模型,以提高跨语言日志异常检测方法的效率和性能。
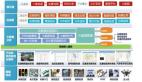
常用的日志异常检测方法一般有四个关键步骤,如图2所示。首先是日志采集,这里使用日志收集系统采集到的日志数据大都是非结构化的文本形式进行存储,接下来进行日志解析工作,通过日志模板抽取的方式,提取日志文本中的常量部分,把原始日志记录处理成结构化信息;下一步是特征选择,通过对日志数据特点进行分析,选取合适的特征对日志进行向量化的表征;最后是异常检测模型构建[2]。本章将对日志解析、特征提取、异常检测三种关键技术的研究现状进行论述。

图 2 日志异常检测流程
日志解析方法
现有的研究提出了许多自动的日志解析方法,解析技术可以从技术、操作方式、预处理等方面进行区分为以下五类:聚类、频繁项挖掘、组合优化算法、启发式方法以及最长子序列[3]。
(1)聚类。聚主要是基于一个假设,即相同或者说相似的日志消息类型会出现在同一组日志中,通过对字符串匹配的距离进行度量实现聚类的效果。例如,LogSig[4]是一种基于消息签名的算法,为每条日志消息搜索最合适的消息签名,充分利用领域知识来确定日志集合的数量。
(2)频繁项挖掘。频繁项挖掘的方法基于一个假设,把模板看作是一组频繁出现在日志中的token的集合。解析过程包括创建频繁项集、对日志消息分组和提取日志模板三个步骤。这种方法的具有代表性的解析器有SLCT[5]、LFA[6]和LogCluster[7]。
(3)组合优化算法。MoLFI[8]使用遗传算法来找到最优日志消息模板集。
(4)启发式方法。该方法通过挖掘日志结构中不同的特性以获得最好的结果。设计了Drain[9]假设在日志的开头,单词不会有太多变化。
(5)最长公共子序列。Spell[10]使用最长公共子序列算法(Longest Common Subsequence,LCS)从传入的日志中动态提取日志模板。
日志特征提取方法
日志特征提取方法包括三种,分别是基于规则、基于统计和基于自然语言处理的特征提取方法[11]。
(1)基于规则的方法主要针对具有固定格式的日志,通过关键词提取或者规则过滤等方式,编写正则表达式对日志文本进行切割,按照日志格式区分成不同的域,转化成结构化日志之后进而对特征进行提取。Chuah等人提出基于规则的方法,对具有特定格式的关系型日志进行特征提取[12]。
(2)基于统计的方法通常是基于日志模板实现的,统计每个日志模板在日志序列中的出现的次数,作为日志序列统计特征,将日志序列表征为用模板计数向量。陈传文等人基于模板计数向量的变化情况对日志是否异常进行判定,使用绝对中位差(Median Absolute Deviation,MAD)对模板计数是否突变进行度量[13]。
(3)基于自然语言处理的方法认为日志文本是由程序打印输出语句的产生的,可以看作是自然语言中的一段话,因此可以使用自然语言处理的方法对日志特征进行提取。基于自然语言处理的日志特征提取通常使用以下三种模型:N-gram、Word Count和TF-IDF(Term Frequency-Inverse Document Frequency)[14]。Sopola等人使用N-gram模型首先将日志模板划分为一个个token,统计该模板中包含的所有连续n个token组成的序列,这些序列也被称为N-gram,统计每个N-gram在所有日志模板集合中出现的次数,即为日志序列的统计特征。
日志异常检测方法
目前,许多学者将数据挖掘、机器学习和深度学习技术应用于异常检测,并实现了更高效的智能运维和诊断。由于日志数据来源多种多样,不同系统的日志格式也不尽相同,具有不同的结构特点。从检测方法的实现方式来说,对日志进行异常检测时可以区分为有监督的日志异常检测方法和无监督的日志异常检测方法。
(1)有监督的日志异常检测方法:使用有监督的方法对日志异常检测时,训练样本中同时包含正常和异常日志,通过对该样本进行训练学习后得到一个分类模型,输入未知的日志,通过分类模型对日志进行二分类,输出为日志的类别,即正常或异常。
(2)无监督的日志异常检测方法:该方法在建模时不需要对有异常标签的日志序列进行训练,而是学习日志数据的内在性质及规律。例如,日志的统计特征和语义特征。基于统计特征的方法通常将日志序列表征为模板统计向量,再采用有效的模型对统计向量进行训练,挖掘异常模式,将异常从包含大量正常样本的数据中挖掘出来。基于语义特征的异常检测方法通过对序列向量进行词嵌入或者句子嵌入得到日志的语义向量化表示来实现异常检测。该方法首先将日志序列表征为日志模板序列,即在保持日志的执行时间先后顺序不变的前提下,将日志序列中的每一条日志都转换为对应的日志模板,然后对日志模板的向量化表征进行建模。模型通过预测该序列的下一个日志模板的类别,生成关于日志模板类别概率分布,选择预测概率最大的 ?? 个日志模板组成正常日志模板集合,剩下的组成异常日志模板集合,最后通过根据实际日志模板所从属的集合类别来判断日志序列是否异常。
参考文献
[1] 张颖君,刘尚奇,杨牧,等.基于日志的异常检测技术综述[J].网络与信息安全学报,2020, 6(6): 1-12.
[2] Fu Q, Lou J G, Wang Y, et al. Execution Anomaly Detection in Distributed Systems through Unstructured Log Analysis [C]//2009 Ninth IEEE International Conference on Data Mining. Miami Beach, FL, USA: IEEE, 2009: 149-158.
[3]ZhuJ,HeS,LiuJ,etal.Toolsandbenchmarksforautomatedlogparsing[C]//2019IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 2019: 121-130.
[4] Tang L, Li T, Perng C S. LogSig: generating system events from raw textual logs [C]// Proceedings of the 20th ACM international conference on Information and knowledge management - CIKM ’11. Glasgow, Scotland, UK: ACM Press, 2011: 785.
[5] Nagappan M, Vouk M A. Abstracting log lines to log event types for mining software system logs [C]//2010 7th IEEE Working Conference on Mining Software Repositories (MSR 2010). IEEE, 2010: 114-117.
[6]NandiA,MandalA,AtrejaS,etal.Anomalydetectionusingprogramcontrolflowgraphmin- ing from execution logs [C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2016: 215-224.
[7]VaarandiR,PihelgasM.LogCluster-Adataclusteringandpatternminingalgorithmforevent logs [C]//2015 11th International Conference on Network and Service Management (CNSM). Barcelona, Spain: IEEE, 2015: 1-7.
[8]MessaoudiS,PanichellaA,BianculliD,etal.Asearch-basedapproachforaccurateidentifica- tion of log message formats [C]//2018 IEEE/ACM 26th International Conference on Program Comprehension (ICPC). IEEE, 2018: 167-16710.
[9] He P, Zhu J, Zheng Z, et al. Drain: An Online Log Parsing Approach with Fixed Depth Tree [C]//2017 IEEE International Conference on Web Services (ICWS). Honolulu, HI, USA: IEEE, 2017: 33-40.
[10]DuM,LiF.Spell:StreamingParsingofSystemEventLogs[C]//2016IEEE16thInternational Conference on Data Mining (ICDM). Barcelona, Spain: IEEE, 2016: 859-864.
[11]贾统, 李影, 吴中海. 基于日志数据的分布式软件系统故障诊断综述 [J]. Journal of Software, 2020, 31(7): 1997-2018.
[12] He P, Zhu J, Zheng Z, et al. Drain: An Online Log Parsing Approach with Fixed Depth Tree [C]//2017 IEEE International Conference on Web Services (ICWS). Honolulu, HI, USA: IEEE, 2017: 33-40.
[13]ChenC,SinghN,YajnikS.Loganalyticsfordependableenterprisetelephony[C]//2012Ninth European Dependable Computing Conference. IEEE, 2012: 94-101.
[14]Sipola T, Juvonen A, Lehtonen J. Anomaly detection from network logs using diffusion maps [M]//Engineering Applications of Neural Networks. Springer, 2011: 172-181.