- 业务简介
- 数仓演进
- 场景实践
- 未来展望
01业务简介

构建实时数据分析平台是为了更好的解决业务对更高数据时效性的需求,先简单介绍一下业务流程。
从日常的场景说起,当我们打开手机 APP 时,常会看到广告。在这样一个场景中,涉及到了两个比较重要的角色。一是手机 APP,即流量方;另一个是投广告的广告主,如支付宝、京东会投放电商广告。广告主购买流量方的流量投广告就产生了交易。
讯飞构建了一个流量交易平台,流量交易平台主要的职能是聚合下游流量,上游再对接广告主,从而帮助广告主和流量方在平台上进行交易。讯飞还构建了投放平台,这个平台更侧重于服务广告主,帮助广告主投放广告,优化广告效果。
在上述的业务流程图中,APP 与平台交互时会向平台发起请求,然后平台会下发广告,用户随后才能看到广告。用户看到广告的这个动作称之为一次曝光,APP 会把这次曝光行为上报给平台。如果用户点击了广告,那么 APP 也会上报点击行为。
广告在产生之后发生了很多行为,可以将广告的整个过程称为广告的一次生命周期,不仅限于图中的请求、曝光、点击这三次行为,后面可能还有下单、购买等。

在这样一个业务流程中,业务的核心诉求是什么呢?在广告的生命周期中有请求、曝光和点击等各种行为,这些行为会产生对应的业务日志。那么就需要从日志生成数据供业务侧分析,从日志到分析的过程中就引入了数仓构建、数仓分层,数据呈现的时效性就带来了实时数据仓库的发展。
02数仓演进

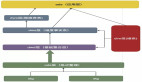
上图是一个典型的数仓分层框架,最底层是 ODS 数据,包括业务日志流、OLTP 数据库、第三方文档数据。经过 ETL 将 ODS 层的数据清洗成业务模型,也就是 DWD 层。

最初是建立了 Spark 数仓,将业务日志收集到 Kafka 中再投递到 HDFS 上,通过 Spark 对日志进行清洗建模,然后将业务模型再回写到 HDFS 上,再使用 Spark 对模型进行统计、分析、输出报表数据。后续,讯飞沿用了 Spark 技术栈引入了 spark-streaming。

随后逐渐将 spark-streaming 迁移到了 Flink 上,主要是因为 Flink 更高的时效性和对事件时间的支持。
当初 spark-streaming 的实践是微批的,一般设置 10 秒或是 30 秒一批,数据的时效性顶多是秒级的。而 Flink 可以支持事件驱动的开发模式,理论上时效性可以达到毫秒级。
当初基于 spark-streaming 的实时数据流逻辑较为简陋,没有形成一个数仓分层的结构。而 Flink 可以基于 watermark 支持事件时间,并且支持对延迟数据的处理,对于构建一个业务逻辑完备的数仓有很大的帮助。

由上图可见,ODS 的业务日志收集到 Kafka 中,Flink 从 Kafka 中消费业务日志,清洗处理后将业务模型再回写到 Kafka 中。然后再基于 Flink 去消费 Kafka 中的模型,提取维度和指标,统计后输出报表。有些报表会直接写到 sql 或 HBase 中,还有一些报表会回写到 Kafka 中,再由 Druid 从 Kafka 中主动摄取这部分报表数据。
在整个数据流图中 Flink 是核心的计算引擎,负责清洗日志、统计报表。
03场景实践
3.1 ODS - 日志消费负载均衡

ODS 业务中,请求日志量级大,其他日志量级小。这样请求日志(request_topic)在 Kafka 上分区多,曝光和点击日志(impress/click_topic)分区少。

最初是采用单 source 的方法,创建一个 FlinkKafkaConsumer011 消费所有分区,这可能导致 task 消费负载不均。同一 topic 的不同分区在 task 上可均匀分配,但不同 topic 的分区可能会被同一 task 消费。期望能达到的消费状态是:量级大的 topic,其 task 和 partition 一一对应,量级小的 topic 占用剩下的 task。

解决方法是把单 source 的消费方式改成了多 source union 的方式,也就是创建了两个 consumer,一个 consumer 用来消费大的 topic,一个 consumer 用来消费小的 topic,并单独为它们设置并行。
3.2 DWD - 日志关联及状态缓存

DWD 是业务模型层,需要实现的一个关键逻辑是日志关联。基于 sid 关联广告一次生命周期中的不同行为日志。业务模型记录了 sid 级别的维度和指标。

最初是基于 30s 的 window 来做关联,但这种方式会导致模型输出较第一次事件发生延迟有 30s,并且 30s 仅能覆盖不到 12% 的曝光日志。如果扩大窗口时间则会导致输出延迟更多,并且同一时刻存在的窗口随时间增长,资源消耗也比较大。

后续改成了基于状态缓存的方式来实现日志关联,即 ValueState。同一 sid 下的日志能够访问到相应的 ValueState。不过为保证及时输出,将请求、曝光、点击等不同指标,拆分到了多条数据中,输出的数据存在冗余。

随着业务的增长和变化,需要缓存的状态日益变大,内存已无法满足。于是我们将状态从内存迁移至 HBase 中,这样做的好处是支持了更大的缓存,并且 Flink checkpoint 负载降低。但同时也带来了两个问题:引入第三方服务,需要额外维护 HBase;HBase 的稳定性也成为计算链路稳定性的重要依赖。

在 HBase 状态缓存中,遇到一个数据倾斜的问题,某条测试 sid 的曝光重复上报,每小时千次量级。如上图,该条 sid 对应的状态达到 MB 级别,被频繁的从 HBase 中取出并写回,引起频繁的 gc,影响所在 task 的性能。解决办法是根据业务逻辑对 impress 进行去重。
3.3 DWS - 实时 OLAP

在 DWD 层基于 Flink 的事件驱动已经实现了实时模型,再由 Flink 来消费处理实时模型,从中提取出维度和指标,然后逐条的向后输出。在这个过程中已是能输出一个实时 OLAP 的结果了,但也需要有个后端的存储来承接,我们因此引入了 Druid。Druid 可以支持数据的实时摄入,并且摄入的结果实时可查,也可以在摄入的同时做自动的聚合。

上图左侧:每张表需要启动常驻任务等待 push 过来的数据。常驻任务被动接收数据,易被压崩;常驻任务异常重启麻烦,需要清理 zk 状态;常驻任务的高可用依赖备份任务,浪费资源。
上图右侧:一张报表对应一个 Kafka 消费任务。消费任务自己控制摄入速率更加稳定;任务可依赖 offset 平滑的失败自启。
3.4 ADS - 跨源查询

Presto 是分布式的 SQL 查询引擎,可从不同的数据源抽取数据并关联查询。但会带来 Druid 的下推优化支持不完善的问题。
3.5 流批混合现状

如上图所示是 Lambda 大数据框架,流式计算部分是 Kafka+Flink,批处理则是 HDFS+Spark。
流式计算的特点:
- 响应快,秒级输出;
- 可重入性差,难以重复计算历史日志;
- 流的持续性重要,异常需迅速介入。
批处理的特点:
- 响应慢,小时级输出;
- 可重入性好,可重复计算历史数据;
- 数据按小时粒度管理,个别异常可从容处理。
流批混合痛点:
- 两遍日志清洗的计算量;
- 两套技术框架;
- 数据一致性问题。
04未来展望

流批混合优化,直接将实时模型输出到 HDFS。
好处是:
- 避免了对日志的重复清洗;
- 统一了建模的技术框架;
- 支持延迟数据对模型的更新。
但也有以下两个问题:
- 实时模型重复,量级更大,计算消耗大;
- 支持数据更新的技术如 Hudi,会改变模型的使用方式,对后续使用者不友好。

最后聊一下对 Flink-SQL 的想法:检索近 10 分钟的某条异常日志、快速评估近 10 分钟新策略的效果都属于即时、微批、即席查询。批处理链路小时级响应太慢;实时检索系统如 ES,资源消耗大。可以利用 Kafka + Flink-SQL 解决上述问题,Kafka + Flink-SQL 也是今后计划尝试的方向。