












“Making large models smaller”这是很多语言模型研究人员的学术追求,针对大模型昂贵的环境和训练成本,陈丹琦在智源大会青源学术年会上做了题为“Making large models smaller”的特邀报告。报告中重点提及了基于记忆增强的TRIME算法和基于粗细粒度联合剪枝和逐层蒸馏的CofiPruning算法。前者能够在不改变模型结构的基础上兼顾语言模型困惑度和检索速度方面的优势;而后者可以在保证下游任务准确度的同时实现更快的处理速度,具有更小的模型结构。

陈丹琦 普林斯顿大学计算机科学系助理教授
陈丹琦于2012年毕业于清华大学姚班,2018年获得斯坦福大学计算机科学博士学位,师从斯坦福大学语言学和计算机科学教授 Christopher Manning。
1 背景介绍
近年来,自然语言处理领域正在迅速被大语言模型所主导。自从GPT 3问世以来,语言模型的规模呈现指数级增长。大型科技公司不断发布越来越大的语言模型。近期,Meta AI发布了OPT语言模型(一个蕴含了1750亿参数的大型语言模型),并向公众开放了源代码和模型参数。

研究学者们之所以如此推崇大语言模型,是因为它们出色的学习能力和性能表现,但是人们对于大语言模型的黑盒性质仍了解甚少。向语言模型输入一个问题,通过语言模型一步一步地推理,能够解决非常复杂的推理问题,比如推导出计算题的答案。但与此同时,大型语言模型也存在着风险,特别是它们的环境和经济成本,例如:GPT-3 等大规模语言模型的能源消耗和碳排放规模惊人。 面对大语言模型训练成本昂贵、参数量庞大等问题,陈丹团队希望通过学术研究缩减预训练模型的计算量并且让语言模型更有效率地适用于下层应用。为此重点介绍了团队的两个工作,一个是一种语言模型的新型训练方法称之为TRIME,另一个是一种适用于下游任务的有效模型剪枝方法称之为CofiPruning。
面对大语言模型训练成本昂贵、参数量庞大等问题,陈丹团队希望通过学术研究缩减预训练模型的计算量并且让语言模型更有效率地适用于下层应用。为此重点介绍了团队的两个工作,一个是一种语言模型的新型训练方法称之为TRIME,另一个是一种适用于下游任务的有效模型剪枝方法称之为CofiPruning。
2 团队工作介绍:TRIME、CofiPruning

论文地址:https://arxiv.org/abs/2205.12674
传统语言模型的训练流程如下:给定一段文档,将其输入到Transformer编码器中得到隐向量,进而将这些隐向量输送到softmax层,该层输出为由V个词嵌入向量组成的矩阵,其中V代表词汇量的规模,最后可以用这些输出向量对原先的文本进行预测,并与给定文档的标准答案进行比较计算梯度,实现梯度的反向传播。然而这样的训练范式会带来以下问题:(1)庞大的Transformer编码器会带来高昂的训练代价;(2)语言模型输入长度固定,Transformer的计算量规模会随着序列长度的变化呈平方级增长,因此Transformer很难处理长文本;(3)如今的训练范式是将文本投影到一个固定长度的向量空间内来预测接下来的单词,这种训练范式实际上是语言模型的一个瓶颈。

为此,陈丹琦团队提出了一种新的训练范式——TRIME,主要利用批记忆进行训练,并在此基础之上提出了三个共享相同训练目标函数的语言模型,分别是TrimeLM,TrimeLMlong以及TrimeLMext。TrimeLM可以看作是标准语言模型的一种替代方案;TrimeLMlong 针对长范围文本设计,类似于Transformer-XL;TrimeLMext结合了一个大型的数据存储区,类似于kNN-LM。在前文所述的训练范式下,TRIME首先将输入文本定义为 ,然后将输入传送到Transformer编码器
,然后将输入传送到Transformer编码器 中,得到隐向量
中,得到隐向量 ,经过softmax层
,经过softmax层 之后得到需要预测的下一个单词
之后得到需要预测的下一个单词 ,在整个训练范式中可训练的参数为
,在整个训练范式中可训练的参数为 和E。陈丹琦团队的工作受到了以下两个工作的启发:(1)2017年Grave等人提出的连续缓存(Continuous cache)算法。该算法在训练过程中训练一个普通的语言模型
和E。陈丹琦团队的工作受到了以下两个工作的启发:(1)2017年Grave等人提出的连续缓存(Continuous cache)算法。该算法在训练过程中训练一个普通的语言模型 ;在推断过程中,给定输入的文本
;在推断过程中,给定输入的文本 ,首先列举给定文本先前出现的所有单词和其中所有等于下一个需要预测单词的标记位置,然后利用隐变量之间的相似度和温度参数计算缓存分布。在测试阶段,对语言模型分布和缓存分布进行线性插值可以得到更好的实验效果。
,首先列举给定文本先前出现的所有单词和其中所有等于下一个需要预测单词的标记位置,然后利用隐变量之间的相似度和温度参数计算缓存分布。在测试阶段,对语言模型分布和缓存分布进行线性插值可以得到更好的实验效果。

(2)2020年Khandelwal等人提出的k近邻语言模型(kNN-LM),该方法与连续缓存算法类似,二者之间最大的不同在于kNN-LM为所有的训练样例构建了一个数据存储区,在测试阶段将对数据存储区的数据进行k近邻搜索,从而选择最佳的top-k数据。
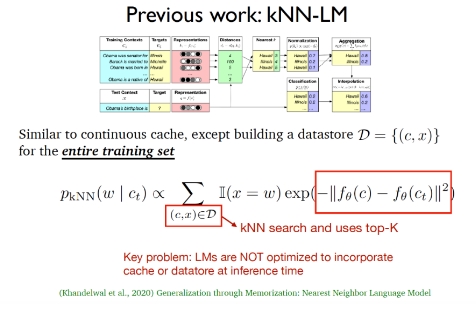
上述两个工作实际上只是在测试阶段采用了缓存分布和k近邻分布,在训练过程中只是延续了传统的语言模型,在推断阶段语言模型并没有优化缓存和数据存储区的结合。
除此之外,还有一些针对超长文本的语言模型工作值得关注,例如在2019年提出的结合注意力循环(Attention recurrence)机制的Transformer-XL和在2020年提出的基于记忆压缩(Memory compression)的Compressive Transformers等。
在之前介绍的几项工作基础之上,陈丹琦团队构建了一个基于批记忆的语言模型训练方法,主要思想是针对相同的训练批(training batch)构建一个工作记忆(working memory)。针对给定文本预测下一个单词的任务,TRIME的思想与对比学习十分类似,不仅仅考虑利用softmax词嵌入矩阵预测下一个单词出现概率的任务,还新增了一个模块,在这个模块中考虑所有出现在训练记忆(training memory)中且与给定文本需要预测的单词相同的所有其他文本。

因此整个TRIME的训练目标函数包括两个部分:
(1)基于输出词嵌入矩阵的预测任务。
(2)在训练记忆(training memory)中共享同一个待预测单词文本的相似度,其中需要衡量相似度的向量表示是在通过最终前馈层的输入,采用缩放点积衡量向量相似度。
算法希望最终训练的网络能够实现最终预测的单词尽可能准确,同时同一训练批内共享同一个待预测单词的文本尽可能相似,以使得正在训练过程中让所有的文本记忆表示通过反向传播实现端到端的神经网络学习。算法的实现思想在很大程度上受到2020年提出的稠密检索(dense retrieval)所启发,稠密检索在训练阶段对齐询问和正相关文档并且利用同一批内的文档作为负样本,在推断阶段从大型数据存储区中检索相关文档。

TRIME的推理阶段几乎与训练过程相同,唯一的区别在于可能会采用不同的测试记忆,包括局部记忆(Local memory),长期记忆(Long-term memory)和外部记忆(External memory)。局部记忆指的是出现在当前片段中的所有单词,并且已经被注意力机制向量化;长期记忆指的是由于输入长度限制导致无法直接获取但与待处理文本来源于相同文档的文本表示,外部记忆指的是存储所有训练样本或者额外语料库的大型数据存储区。
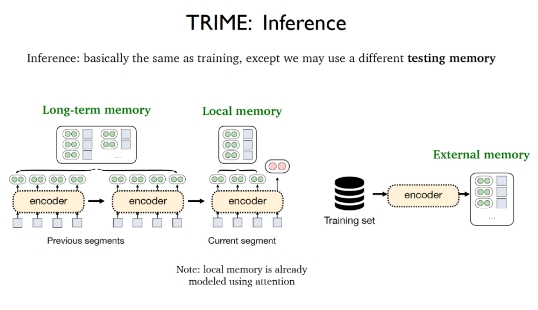
为了能够尽可能减小训练和测试阶段的不一致性,需要采取一定的数据处理策略来更好地构建训练记忆。局部记忆指的是在同一个数据片段中的先前标记(tokens),使用代价极其低廉。可以采用随机取样的批处理方式就能直接在训练阶段和测试阶段同时利用局部记忆,这就得到了基于局部记忆的基础版TrimeLM模型。

长期记忆指的是在同一个文档先前片段中的标记,需要依赖于同一个文档的先前片段。为此将同一个文档中的连续片段(consecutive segments)放入同一个训练批中,这就得到了集合长期记忆的TrimeLMlong模型。

外部记忆需要结合大型数据存储区进行检索。为此可以利用BM25将训练数据中的相似片段放入同一个训练批中,这就得到了结合外部记忆的TrimeLMext模型。

综上所述,传统的语言模型在训练阶段和测试阶段都没有利用记忆;连续缓存方法只在测试阶段采用了局部记忆或者长期记忆;k近邻语言模型在测试阶段采用了外部记忆;而针对TRIME算法的三种语言模型,在训练阶段和测试阶段都采用了记忆增强的方式,其中TrimeLM在训练阶段和测试阶段都采用了局部记忆,TrimeLMlong在训练阶段针对相同文档的连续片段放入同一批训练,在测试阶段结合了局部记忆和长期记忆,TrimeLMext在训练阶段针对相似文档放入同一批训练,在测试阶段结合了局部记忆、长期记忆和外部记忆。

在实验阶段,在WikiText-103数据集上进行模型参数247M,切片长度3072的测试时,基于TRIME算法的三种版本的语言模型都能取得比传统Transformer更好的困惑度(perplexity)效果,其中基于实际距离的TrimeLMext模型可以取得最好实验效果。同时TrimeLM和TrimeLMlong也能保持和传统Transformer 接近的检索速度,同时兼具了困惑度和检索速度的优势。

在WikiText-103数据集上进行模型参数150M,切片长度150的测试时,可以看到由于TrimeLMlong在训练阶段针对相同文档的连续片段放入同一批训练,在测试阶段结合了局部记忆和长期记忆,因此尽管切片长度只有150,但是在测试阶段实际可利用的数据可以达到15000,实验效果远远好于其他基线模型。

针对字符级别的语言模型构建,基于TRIME算法的语言模型在enwik8数据集上同样取得了最好的实验效果,同时在机器翻译的应用任务中,TrimeMT_ext也取得了超过基线模型的实验效果。

综上所述,基于TRIME算法的语言模型采用了三种记忆构建的方式,充分利用同一批内的相关数据实现记忆增强,在引入记忆的同时却没有引入大量的计算代价,并且没有改变模型的整体结构,相比于其他基线模型取得了较好的实验效果。
陈丹琦还着重提到了基于检索的语言模型,实际上TrimeLMext可以看作是k近邻语言模型的一个更好的版本,但是在推断过程中这两种算法相较于其他的基线模型速度要慢接近10到60倍,这显然是难以接受的。陈丹琦指出了基于检索的语言模型未来可能的发展方向之一:是否可以利用一个更小的检索编码器和一个更大的数据存储区,从而实现计算代价缩减到最近邻搜索。
相比于传统的语言模型,基于检索的语言模型有显著的优势,例如:基于检索的语言模型可以更好的实现更新和维护,而传统的语言模型由于利用先前知识进行训练无法实现知识的动态更新;同时基于检索的语言模型还可以更好的利用到隐私敏感的领域中去。至于如何更好的利用基于检索的语言模型,陈丹琦老师认为或许可以采用fine-tuning、prompting或者in-context learning的方式来辅助解决。

论文地址:https://arxiv.org/abs/2204.00408
模型压缩技术被广泛应用于大语言模型,让更小的模型能够更快地适用于下游应用,其中传统的主流模型压缩方法为蒸馏(Distillation)和剪枝(pruning)。对于蒸馏而言,往往需要预先定义一个固定的学生模型,这个学生模型通常是随机初始化的,然后将知识从教师模型传送到学生模型中去,实现知识蒸馏。
例如,从原始版本的BERT出发,经过通用蒸馏,即在大量无标注的语料库上进行训练之后,可以得到基础版本的TinyBERT4,针对基础版本的TinyBERT4,还可以通过任务驱动的蒸馏方法得到微调过的TinyBERT4,最终得到的模型在牺牲轻微的准确度基础之上可以比原先的BERT模型更小且处理速度更快。然而这种基于蒸馏的方法也存在着一定的缺陷,例如针对不同的下游任务,模型的架构往往是固定不变的;与此同时需要利用无标注数据从零开始训练,计算代价太大。

对于剪枝而言,往往需要从一个教师模型出发,然后不断地从原始模型中移除不相关的部分。在2019年提出的非结构化剪枝可以得到更小的模型但是在运行速度方面提升很小,而结构化剪枝通过移除例如前馈层等参数组实现实际应用的速度提升,例如2021年提出的块剪枝可以实现2-3倍的速度提升。


针对传统蒸馏和剪枝方法存在的局限性,陈丹琦团队提出了一种名为CofiPruning的算法,同时针对粗粒度单元和细粒度单元进行剪枝,并设计了一个逐层蒸馏的目标函数将知识从未剪枝模型传送到剪枝后的模型中去,最终能够在保持超过90%准确率的基础之上实现超过10倍的速度提升,比传统的蒸馏方法计算代价更小。
CofiPruning的提出建立在两个重要的基础工作之上:
(1)针对整层剪枝可以获得速度上的提升,相关工作指出大概50%左右的神经网络层是可以被剪枝的,但是粗粒度的剪枝对准确率的影响比较大。
(2)是对更小单元例如头部进行剪枝可以获得更好的灵活性,但是这种方法在实现上会是一个更有难度的优化问题,且不会有太大的速度提升。
为此陈丹琦团队希望能够在粗粒度单元和细粒度单元同时剪枝,从而兼具两种粒度的优势。除此之外,为了解决从原始模型到剪枝模型的数据传送,CofiPruning在剪枝过程中采用逐层对齐的方式实现知识的传送,最终的目标函数包括了蒸馏损失和基于稀疏度的拉格朗日损失。

在实验阶段,在针对句子分类任务的GLUE数据集和针对问答任务的SQuAD1.1数据集上,可以发现CofiPruning在相同的速度和模型规模基础之上比所有的蒸馏和剪枝基线方法表现更好。

针对TinyBERT,如果没有经过通用蒸馏,实验效果会大打折扣;但是如果利用通用蒸馏,尽管实验效果可以有所提升但是训练时间代价会非常昂贵。而CofiPruning算法不但能够获得与基线模型近乎持平的效果,在运行时间和计算代价方面还都有很大提升,可以用更少的计算代价获得更快的处理速度。实验表明,针对粗粒度单元,第一层和最后一层前馈层在最大程度上会被保留而中间层更有可能会被剪枝;针对细粒度单元,上层神经网络的头部和中间维度更有可能会被剪枝。

综上所述,CofiPruning是一种非常简单有效的模型压缩算法,通过对粗粒度单元和细粒度单元联合剪枝,结合逐层蒸馏的目标函数可以联通结构剪枝和知识蒸馏这两种算法的优势,从而实现更快的处理速度和更小的模型结构。针对模型压缩的未来趋势,陈丹琦还重点提及了是否能够对例如GPT-3这样的大型语言模型进行剪枝,同时是否能够对上游任务进行剪枝,这些都是未来可以重点关注的研究思路。
3 总结与展望
大型语言模型如今取得了非常喜人的实际应用价值,但是由于昂贵的环境和经济成本,隐私和公平性方面的困扰以及难以实时更新的问题,导致大型语言模型仍有很多待改进之处。陈丹琦认为,未来的语言模型或许可以用作大型的知识库,同时在未来语言模型的规模需要大幅度削减,或许可以利用基于检索的语言模型或者稀疏语言模型来代替稠密检索,模型压缩的工作也需要研究者们重点关注。



























