HTAP是目前数据库领域谈得最多的一个词,也是我们存在最多误解的词。曾经有一个企业的IT主管和我说,如果我选一款HTAP数据库产品,是不是我都可以把数据仓库拆了,今后只有在线交易系统和大数据平台就行了。这里面实际上包含了对HTAP的巨大的误解。HTAP=OLTP+OLAP,上面的这个公式真的成立吗?今天我们来简单地了解一下传统的OLTP和OLAP是什么样的。

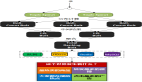
上面是一个传统的交易域和数仓域分离的传统数据仓库架构。大量的在线交易系统首先把数据复制到贴贴源层的ODS,然后经过ETL工具加载到数据仓库中,同时数据仓库中还会存储一些来自外部的数据,甚至一些外购的数据。存储在数据仓库中的是高价值数据,经过处理后形成一系列的数据集市,供业务系统使用。这种架构中将在线交易与数据分析两种截然不同的负载区分开来,避免相互干扰。
不过这种架构最大的问题是,ETL的延时比较大,很多需要及时分析的业务无法得到保证。因此缩短在线交易系统到数据仓库之间的延时就十分重要了。

Oracle公司推出了一套基于准实时ETL产品ODI的解决方案。生产系统使用ORACLE的交易型数据库模式,通过ODI捕获生产系统的变化,并通过定义好的转换规则,准实时进行ETL操作,复制数据到ORACLE OLAP模式的数据仓库中。上面的优化模式虽然能解决一部分数据仓库的延时问题,但是对于实时性要求更高的一些业务就无法满足了。
因此在在线交易系统中支撑比较强大的数据分析功能的需求就应运而生了,这个需求就是HTAP计算模式。不过聪明的朋友可能也看出来了,这种HTAP计算并不等同于在线交易+数据仓库业务。因为如果我们要把一个企业的所有高价值数据都存储在一个数据库里,才能实现这个替代数据仓库的目标。而这种设计会让单一的数据库太重了,一旦这个数据库出现一点点问题,可能就会影响整个企业的业务,这是我们无法承受的。
企业需要的HTAP能力不需要完全覆盖数据仓库业务,仅仅需要对核心业务需要的在线分析能力做一定的提升就可以了。因此在HTAP数据库中需要存储的就是OLTP系统本身的数据以及部分分析必须的从外部提取过来的高价值数据。

上面的图看上去是不是简单多了,不过这个简化了的业务需求也并不容易实现。这是因为TP系统跑的是稳定,高并发,低延时,大多数通过索引访问,大量写操作的小业务,对于并发写入量较大的表,尽可能减少不必要的索引;而AP系统跑的是随机性大,资源开销极大,大部分需要对大表进行并行扫描,持续时间很长的的以读为主的分析类业务。读写操作之间会有相互影响,大量的写操作希望索引越少越好,而大量的读操作希望索引越丰富越好。AP操作的临时性资源开销可能会导致TP业务的延时出现经常性的抖动,这些都是会让TP业务无法忍受的。
TP业务经常需要访问一张表中的多个字段,从而实现复杂的业务逻辑,因此用行存储的方式性能最佳。AP业务经常对某一列的数据做扫描分析,因此如果数据按列存储具有较好的性能。这些业务之间的矛盾都使一个数据库中承载混合的HTAP负载十分困难。
而实际上,我们的OLTP系统中,真的都需要HTAP工作负载吗?答案是否定的。大多数OLTP系统中仅仅需要一定量的批处理负载,用于对数据进行一些复杂的加工。在一个设计的比较好的OLTP系统中,通过定期自动汇总数据,物化视图等方式,可以大幅度减少开销极大的AP工作负载。只有极少数的系统是真的必须有复杂的准实时OLAP需求的。而对于AP的实时性要求,如果通过更实时的数据复制和ETL,大部分问题是可以解决的。
此外,分布式SQL引擎的效率、OLTP/OLAP的资源隔离与防干扰措施、数据存储格式、大型集群管理、读写副本的使用方式、主副本切换带来的性能抖动等都会影响数据库的HTAP能力。
既然HTAP负载并不是业务系统一定要追求的,那么为什么现在我们随便看到一个分布式数据库,就一定说自己是HTAP数据库呢?
这实际上是和分布式数据库的发展历史分不开的。分布式数据库刚刚出现的时候,主要还是为了高并发的OLTP写入业务。因此这些数据库产品的多表关联,复杂分析功能是很弱的。分布数据库厂家也在不断地优化产品,努力提升这方面的能力。因此为了标榜自己的技术优势,大家都在HTAP能力上开展起军备竞赛了。
虽然如此,如果真的有一个HTAP能力极强的数据库产品放在我们面前,对于用户和软件开发商来说,肯定是一件好事情。这会让我们的管理系统,交易系统的功能变得更加丰富。对于某些行业的业务系统来说,可能会促进业务的革命性变革。比如说能源行业鼓吹了多年的源网核储互动,因为我们的数据处理能力不足,不及时,导致我们在电力生产、消费、储能、调度等方面的数据无法及时进行处理分析,大大降低了能源的综合利用率。
目前来说,电是不可大规模存储的资源,而且电源侧发出的电必须平衡的被消耗掉,否则多发出来的电必须被尽快消耗掉,而某个局部网络上的电能不足时,就只能拉闸限电,确保电能在网络上整个是平衡的。当电源侧发电量过大,或者用电需求过大,供给不足或者电力调度不及时,导致用电缺口达到一定程度的时候,电网会因为不平衡而解裂,2013年洛杉矶大停电或者前几年美国德州大停电的惨剧就会重演了。
我们国家这些年没有出现过类似的情况,这说明我国的大电网调度运营水平是很高的。不过这种水平很高并不意味着很高效。我们的电网调度十分依赖于相对稳定的电源,比如火力发电。而水电、光伏、风能这些清洁能源因为其不稳定,会大大加大电网调度的难度。因此目前我国弃风弃光的比例一直是高于西方发达国家的。
为了完成碳中和目标,加大清洁能源供给是必然的,因此源网核储互动能力的提升十分关键。而要提升源网核储互动的效率,精准及时的数据采集与数据分析是关键。我们必须提高电能表采集的频率(欧洲最先进的电网计量已经实现了5分钟全量采集,而我们目前的主流水平还只是重点电表15分钟间隔采集),提升与发电企业之间的数据交换的水平,对气候、社会热点、制造业增长态势、外贸等数据进行更广泛的采集与处理分析,这样才能逐步提升电网调度计划的水平。以目前电能采集系统到大数据平台数据复制的一天时延来看,要实现这个任务是几乎不可能的。
具有强大HTAP处理能力的数据库是解决这个计算难题的十分关键的IT基础设施,这是一个十分现实的HTAP计算场景。十分可惜的是,在我们为这个场景选择数据库产品的时候,还没有找到一款国产数据库产品具备处理这个业务场景的能力。
其他行业中,也可以找出很多类似这样的计算场景,在提升企业效率,降低企业成本的业务创新中,这种需求也会越来越多。因此数据库产品发展HTAP能力是十分重要的。只是说,目前我们的国产数据库的HTAP能力建设还处于初级阶段,目前大多数国产数据库能够提供的HTAP能力大部分可以通过业务系统优化来避开,而真正对HTAP强需求的场景,我们的产品的支撑能力还略显不足。