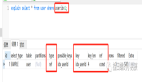
索引在我们的日常生活中其实是很常见的,就像:
- 一本书有自己的目录和具体的章节,当我们想找某个知识点,翻到对应的章节即可;
- 也像图书馆中的书籍被分类成文史类、技术类、小说类等,再加上书籍的编号,很快就能够找到我们想要的书籍。
- 外出吃饭点菜的菜单,从主食类、饮料/汤类、凉菜类等,到具体的菜名等,点个菜即可。
上面不同的场景都可以看做是一个具体的索引应用:通过索引我们能够快速定位数据。
因此,基于实际需求出发创建的索引对我们的业务工作具有很强的指导意义。在Pandas中创建合适的索引则能够方便我们的数据处理工作。

官网学习地址:https://pandas.pydata.org/docs/reference/api/pandas.Index.html
下面通过实际案例来介绍Pandas中常见的10种索引,以及如何创建它们。
pd.Index
Index是Pandas中的常见索引函数,通过它能够构建各种类型的索引,其语法为:

pandas.Index(
data=None, # 一维数组或者类似数组结构的数据
dtype=None, # NumPy数据类型(默认值:对象)
copy=False, # 是否生成副本
name=None, # 索引名字
tupleize_cols=True, # 如果为True,则尽可能尝试创建 MultiIndex
**kwargs
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
导入两个必需的库:
import pandas as pd
import numpy as np- 1.
- 2.
默认的数据类型是int64
In [2]:
# 通过列表来创建
pd.Index([1,2,3,4])- 1.
- 2.
Out[2]:
Int64Index([1, 2, 3, 4], dtype='int64')- 1.
在创建的时候,还能够直接指定数据类型:
In [3]:
# 指定索引的数据类型
pd.Index([1,2,3,4], dtype="float64")- 1.
- 2.
Out[3]:
Float64Index([1.0, 2.0, 3.0, 4.0], dtype='float64')- 1.
在创建的时候指定名称name和数据类型dtype:
In [4]:
# 指定类型和名称
pd.Index([1,2,3,4],
dtype="float64",
name="Peter")- 1.
- 2.
- 3.
- 4.
Out[4]:
Float64Index([1.0, 2.0, 3.0, 4.0], dtype='float64', name='Peter')- 1.
In [5]:
# 使用list函数生成列表来创建
pd.Index(list("ABCD"))- 1.
- 2.
Out[5]:
Index(['A', 'B', 'C', 'D'], dtype='object')- 1.
使用元组来进行创建:
In [6]:
# 使用元组来创建
pd.Index(("a","b","c","d"))- 1.
- 2.
Out[6]:
Index(['a', 'b', 'c', 'd'], dtype='object')- 1.
使用集合来进行创建。集合本身是无序的,所以最终的结果并不一定是按照给定的元素顺序:
In [7]:
# 使用集合来创建,集合本身是无序的
pd.Index({"x","y","z"})- 1.
- 2.
Out[7]:
Index(['z', 'x', 'y'], dtype='object')- 1.
pd.RangeIndex
生成一个区间内的索引,主要是基于Python的range函数,其语法为:

pandas.RangeIndex(
start=None, # 起始值,默认为0
stop=None, # 终止值
step=None, # 步长,默认为1
dtype=None, # 类型
copy=False, # 是否生成副本
name=None) # 名称- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
下面通过多个例子来讲解:
In [8]:
pd.RangeIndex(8) # 默认start是0,步长是1- 1.
默认结果中起始值是0,结束值是8(不包含),步长是1:
Out[8]:
RangeIndex(start=0, stop=8, step=1)- 1.
In [9]:
pd.RangeIndex(0,8) # 指定start和stop- 1.
Out[9]:
RangeIndex(start=0, stop=8, step=1)- 1.
改变步长为2:
In [10]:
pd.RangeIndex(0,8,2)- 1.
Out[10]:
RangeIndex(start=0, stop=8, step=2)- 1.
In [11]:
list(pd.RangeIndex(0,8,2))- 1.
将结果用list显示出来,没有包含stop的值8:
Out[11]:
[0, 2, 4, 6]- 1.
下面的案例中将步长改成-1:
In [12]:
pd.RangeIndex(8,0,-1)- 1.
Out[12]:
RangeIndex(start=8, stop=0, step=-1)- 1.
In [13]:
list(pd.RangeIndex(8,0,-1))- 1.
Out[13]:
[8, 7, 6, 5, 4, 3, 2, 1] # 结果中不包含0- 1.
pd.Int64Index
指定数据类型是int64整型
pandas.Int64Index(
data=None, # 生成索引的数据
dtype=None, # 索引类型,默认是int64
copy=False, # 是否生成副本
name=None) # 使用名称- 1.
- 2.
- 3.
- 4.
- 5.
In [14]:
pd.Int64Index([1,2,3,4])- 1.
Out[14]:
Int64Index([1, 2, 3, 4], dtype='int64')- 1.
In [15]:
pd.Int64Index([1,2.0,3,4]) # 强制转成int64类型- 1.
Out[15]:
Int64Index([1, 2, 3, 4], dtype='int64')- 1.
In [16]:
pd.Int64Index([1,2,3,4],name="Peter")- 1.
Out[16]:
Int64Index([1, 2, 3, 4], dtype='int64', name='Peter')- 1.
如果在数据中包含小数则会报错:
In [17]:
# pd.Int64Index([1,2,3,4.4]) # 出现小数则报错- 1.

pd.UInt64Index
数据类型是无符号的UInt64
pandas.UInt64Index(
data=None,
dtype=None,
copy=False,
name=None
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
In [18]:
pd.UInt64Index([1, 2, 3, 4])- 1.
Out[18]:
UInt64Index([1, 2, 3, 4], dtype='uint64')- 1.
In [19]:
pd.UInt64Index([1, 2, 3, 4],name="Tom") # 指定名字- 1.
Out[19]:
UInt64Index([1, 2, 3, 4], dtype='uint64', name='Tom')- 1.
In [20]:
pd.UInt64Index([1, 2.0, 3, 4],name="Tom")- 1.
Out[20]:
UInt64Index([1, 2, 3, 4], dtype='uint64', name='Tom')- 1.
# 存在小数则报错
pd.UInt64Index([1, 2.4, 3, 4],name="Tom")- 1.
- 2.

pd.Float64Index
数据类型是Float64位的浮点型,允许小数出现:
pandas.Float64Index(
data=None, # 数据
dtype=None, # 类型
copy=False, # 是否生成副本
name=None # 索引名字
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
In [22]:
pd.Float64Index([1, 2, 3, 4])- 1.
Out[22]:
Float64Index([1.0, 2.0, 3.0, 4.0], dtype='float64')- 1.
In [23]:
pd.Float64Index([1.5, 2.4, 3.7, 4.9])- 1.
Out[23]:
Float64Index([1.5, 2.4, 3.7, 4.9], dtype='float64')- 1.
In [24]:
pd.Float64Index([1.5, 2.4, 3.7, 4.9],name="peter")- 1.
Out[24]:
Float64Index([1.5, 2.4, 3.7, 4.9], dtype='float64', name='peter')- 1.
注意:在Pandas1.4.0的版本中,上面3个函数全部统一成了pd.NumericIndex方法。
pd.IntervalIndex
pd.IntervalIndex(
data, # 待生成索引的数据(一维)
closed=None, # 区间的哪边是关闭状态,{‘left’, ‘right’, ‘both’, ‘neither’}, default ‘right’
dtype=None, # 数据类型
copy=False, # 生成副本
name=None, # 索引的名字
verify_integrity=True # 判断是否符合
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
新的 IntervalIndex 通常使用interval_range()函数来进行构造,基本用法:
In [24]:
pd.interval_range(start=0, end=6)- 1.
Out[24]:
IntervalIndex([(0, 1], (1, 2], (2, 3], (3, 4], (4, 5], (5, 6]],
closed='right', # 默认情况下右边是关闭的
dtype='interval[int64]')- 1.
- 2.
- 3.
In [25]:
pd.interval_range(start=0, end=6, closed="neither") # 两边都不关闭- 1.
Out[25]:
IntervalIndex([(0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6)],
closed='neither',
dtype='interval[int64]')- 1.
- 2.
- 3.
In [26]:
pd.interval_range(start=0, end=6, closed="both") # 两边都关闭- 1.
Out[26]:
IntervalIndex([[0, 1], [1, 2], [2, 3], [3, 4], [4, 5], [5, 6]],
closed='both',
dtype='interval[int64]')- 1.
- 2.
- 3.
In [27]:
pd.interval_range(start=0, end=6, closed="left") # 左边关闭- 1.
Out[27]:
IntervalIndex([[0, 1), [1, 2), [2, 3), [3, 4), [4, 5), [5, 6)],
closed='left',
dtype='interval[int64]')- 1.
- 2.
- 3.
In [28]:
pd.interval_range(start=0, end=6, name="peter")- 1.
Out[28]:
IntervalIndex([(0, 1], (1, 2], (2, 3], (3, 4], (4, 5], (5, 6]],
closed='right',
name='peter',
dtype='interval[int64]')- 1.
- 2.
- 3.
- 4.
pd.CategoricalIndex
pandas.CategoricalIndex(
data=None, # 数据
categories=None, # 分类的数据
ordered=None, # 是否排序
dtype=None, # 数据类型
copy=False, # 副本
name=None) # 名字- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
在下面的例子中我们以一批衣服的尺码作为模拟数据:
In [29]:
# 指定数据
c1 = pd.CategoricalIndex(["S","M","L","XS","M","L","S","M","L","XL"])
c1- 1.
- 2.
- 3.
Out[29]:
CategoricalIndex(
# 数据
['S', 'M', 'L', 'XS', 'M', 'L', 'S', 'M', 'L', 'XL'],
# 出现的不同元素
categories=['L', 'M', 'S', 'XL', 'XS'],
# 默认不排序
ordered=False,
# 数据类型
dtype='category'
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
In [30]:
c2 = pd.CategoricalIndex(
["S","M","L","XS","M","L","S","M","L","XL"],
# 指定分类的数据
categories=["XS","S","M","L","XL"]
)
c2- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
Out[30]:
CategoricalIndex(
['S', 'M', 'L', 'XS', 'M', 'L', 'S', 'M', 'L', 'XL'],
categories=['XS', 'S', 'M', 'L', 'XL'],
ordered=False,
dtype='category'
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
In [31]:
c3 = pd.CategoricalIndex(
# 数据
["S","M","L","XS","M","L","S","M","L","XL"],
# 分类名字
categories=["XS","S","M","L","XL"],
# 确定排序
ordered=True
)
c3- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
Out[31]:
CategoricalIndex(
['S', 'M', 'L', 'XS', 'M', 'L', 'S', 'M', 'L', 'XL'],
categories=['XS', 'S', 'M', 'L', 'XL'],
ordered=True, # 已经排序
dtype='category')- 1.
- 2.
- 3.
- 4.
- 5.
In [32]:
c4 = pd.CategoricalIndex(
# 待排序的数据
["S","M","L","XS","M","L","S","M","L","XL"],
# 指定分类顺序
categories=["XS","S","M","L","XL"],
# 排序
ordered=True,
# 索引名字
name="category"
)
c4- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
Out[32]:
CategoricalIndex(
['S', 'M', 'L', 'XS', 'M', 'L', 'S', 'M', 'L', 'XL'],
categories=['XS', 'S', 'M', 'L', 'XL'],
ordered=True,
name='category',
dtype='category'
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
CategoricalIndex 索引对象也可以从 Categorical() 方法进行实例化得到:
In [33]:
c5 = pd.Categorical(["a", "b", "c", "c", "b", "c", "a"])
pd.CategoricalIndex(c5)- 1.
- 2.
- 3.
Out[33]:
CategoricalIndex(
['a', 'b', 'c', 'c', 'b', 'c', 'a'],
categories=['a', 'b', 'c'],
ordered=False, # 默认不排序
dtype='category')- 1.
- 2.
- 3.
- 4.
- 5.
In [34]:
pd.CategoricalIndex(c5, ordered=True) # 指定排序- 1.
Out[34]:
CategoricalIndex(
['a', 'b', 'c', 'c', 'b', 'c', 'a'],
categories=['a', 'b', 'c'],
ordered=True, # 排序
dtype='category')- 1.
- 2.
- 3.
- 4.
- 5.
pd.DatetimeIndex
以时间和日期作为索引,通过date_range函数来生成,具体语法为:
pd.DatetimeIndex(
data=None, # 数据
freq=NoDefault.no_default, # 频率
tz=None, # 时区
normalize=False, # 是否归一化
closed=None, # 区间是否关闭
# ‘infer’, bool-ndarray, ‘NaT’, 默认‘raise’
ambiguous='raise',
dayfirst=False, # 第一天
yearfirst=False, # 第一年
dtype=None, # 数据类型
copy=False, # 副本
name=None # 名字
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
以时间和日期作为索引,通过date_range函数来生成,具体例子为:
In [35]:
# 默认天为频率
pd.date_range("2022-01-01",periods=6)- 1.
- 2.
Out[35]:
DatetimeIndex(
['2022-01-01', '2022-01-02',
'2022-01-03', '2022-01-04',
'2022-01-05', '2022-01-06'],
dtype='datetime64[ns]',
freq='D' # 频率
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
In [36]:
# 日期作为索引,D代表天
d1 = pd.date_range(
"2022-01-01",
periods=6,
freq="D")
d1- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
Out[36]:
DatetimeIndex(
['2022-01-01', '2022-01-02',
'2022-01-03', '2022-01-04',
'2022-01-05', '2022-01-06'],
dtype='datetime64[ns]',
freq='D')- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
In [37]:
# H代表小时
pd.date_range("2022-01-01",periods=6, freq="H")- 1.
- 2.
Out[37]:
DatetimeIndex(
['2022-01-01 00:00:00', '2022-01-01 01:00:00',
'2022-01-01 02:00:00', '2022-01-01 03:00:00',
'2022-01-01 04:00:00', '2022-01-01 05:00:00'],
dtype='datetime64[ns]',
freq='H')- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
In [38]:
# M代表月
pd.date_range("2022-01-01",periods=6, freq="3M")- 1.
- 2.
Out[38]:
DatetimeIndex(
['2022-01-31', '2022-04-30',
'2022-07-31','2022-10-31',
'2023-01-31', '2023-04-30'],
dtype='datetime64[ns]',
freq='3M')- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
In [39]:
# Q代表季度
pd.date_range("2022-01-01",periods=6, freq="Q")- 1.
- 2.
- 3.
显示的结果中以一个季度-3个月为频率:
Out[39]:
DatetimeIndex(
['2022-03-31', '2022-06-30',
'2022-09-30','2022-12-31',
'2023-03-31', '2023-06-30'],
dtype='datetime64[ns]',
freq='Q-DEC')- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
In [40]:
# 指定时区tz
pd.date_range("2022-01-01",periods=6, tz="Asia/Calcutta")- 1.
- 2.
- 3.
Out[40]:
DatetimeIndex(
['2022-01-01 00:00:00+05:30', '2022-01-02 00:00:00+05:30',
'2022-01-03 00:00:00+05:30', '2022-01-04 00:00:00+05:30',
'2022-01-05 00:00:00+05:30', '2022-01-06 00:00:00+05:30'],
dtype='datetime64[ns, Asia/Calcutta]', freq='D')- 1.
- 2.
- 3.
- 4.
- 5.
pd.PeriodIndex
pd.PeriodIndex是一个专门针对周期性数据的索引,方便针对具有一定周期的数据进行处理,具体用法如下:
pd.PeriodIndex(
data=None, # 数据
ordinal=None, # 序数
freq=None, # 频率
dtype=None, # 数据类型
copy=False, # 副本
name=None, # 名字
**fields
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
生成pd.PeriodIndex对象的方式1:指定开始时间、周期频率
In [41]:
pd.period_range('2022-01-01 09:00', periods=5, freq='H')- 1.
Out[41]:
PeriodIndex(
['2022-01-01 09:00', '2022-01-01 10:00',
'2022-01-01 11:00','2022-01-01 12:00', '2022-01-01 13:00'],
dtype='period[H]', freq='H')- 1.
- 2.
- 3.
- 4.
In [42]:
pd.period_range('2022-01-01 09:00', periods=6, freq='2D')- 1.
Out[42]:
PeriodIndex(
['2022-01-01', '2022-01-03',
'2022-01-05', '2022-01-07',
'2022-01-09', '2022-01-11'],
dtype='period[2D]',
freq='2D')- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
In [43]:
pd.period_range('2022-01', periods=5, freq='M')- 1.
Out[43]:
PeriodIndex(
['2022-01', '2022-02',
'2022-03', '2022-04', '2022-05'],
dtype='period[M]', freq='M')- 1.
- 2.
- 3.
- 4.
In [44]:
p1 = pd.DataFrame(
{"name":["xiaoming","xiaohong","Peter","Mike","Jimmy"]},
# 指定索引
index=pd.period_range('2022-01-01 09:00', periods=5, freq='3H')
)
p1- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.

生成pd.PeriodIndex对象的方式2:直接使用pd.PeriodIndex方法
In [45]:
pd.PeriodIndex(
['2022-01-01', '2022-01-02',
'2022-01-03', '2022-01-04'],
freq = '2H')- 1.
- 2.
- 3.
- 4.
Out[45]:
PeriodIndex(
['2022-01-01 00:00', '2022-01-02 00:00',
'2022-01-03 00:00','2022-01-04 00:00'],
dtype='period[2H]', freq='2H')- 1.
- 2.
- 3.
- 4.
In [46]:
pd.PeriodIndex(
['2022-01', '2022-02',
'2022-03', '2022-04'],
freq = 'M')- 1.
- 2.
- 3.
- 4.
Out[46]:
PeriodIndex(
['2022-01', '2022-02',
'2022-03', '2022-04'],
dtype='period[M]',
freq='M')- 1.
- 2.
- 3.
- 4.
- 5.
In [47]:
pd.PeriodIndex(['2022-01', '2022-07'], freq = 'Q')- 1.
Out[47]:
PeriodIndex(
['2022Q1', '2022Q3'],
dtype='period[Q-DEC]',
freq='Q-DEC')- 1.
- 2.
- 3.
- 4.
生成pd.PeriodIndex对象的方式3:利用date_range函数先生成DatetimeIndex对象
In [48]:
data = pd.date_range("2022-01-01",periods=6)
data- 1.
- 2.
Out[48]:
DatetimeIndex(
['2022-01-01', '2022-01-02',
'2022-01-03', '2022-01-04',
'2022-01-05', '2022-01-06'],
dtype='datetime64[ns]',
freq='D')- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
In [49]:
pd.PeriodIndex(data=data)- 1.
Out[49]:
PeriodIndex(
['2022-01-01', '2022-01-02',
'2022-01-03', '2022-01-04',
'2022-01-05', '2022-01-06'],
dtype='period[D]', freq='D')- 1.
- 2.
- 3.
- 4.
- 5.
In [50]:
p2 = pd.DataFrame(np.random.randn(400, 1),
columns=['number'],
# 指定索引
index=pd.period_range('2021-01-01 8:00',
periods=400,
freq='D'))
p2- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.

pd.TimedeltaIndex
pd.TimedeltaIndex(
data=None, # 数据
unit=None, # 最小单元
freq=NoDefault.no_default, # 频率
closed=None, # 指定关闭的位置
dtype=dtype('<m8[ns]'), # 数据类型
copy=False, # 副本
name=None # 名字
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
创建方式1:指定数据和最小单元
In [51]:
pd.TimedeltaIndex([12, 24, 36, 48], unit='s')- 1.
Out[51]:
TimedeltaIndex(
['0 days 00:00:12', '0 days 00:00:24',
'0 days 00:00:36','0 days 00:00:48'],
dtype='timedelta64[ns]',
freq=None)- 1.
- 2.
- 3.
- 4.
- 5.
In [52]:
pd.TimedeltaIndex([1, 2, 3, 4], unit='h') # 按小时- 1.
Out[52]:
TimedeltaIndex(
['0 days 01:00:00', '0 days 02:00:00',
'0 days 03:00:00','0 days 04:00:00'],
dtype='timedelta64[ns]',
freq=None)- 1.
- 2.
- 3.
- 4.
- 5.
In [53]:
pd.TimedeltaIndex([12, 24, 36, 48], unit='h')- 1.
Out[53]:
TimedeltaIndex(
['0 days 12:00:00', '1 days 00:00:00',
'1 days 12:00:00','2 days 00:00:00'],
dtype='timedelta64[ns]', # 数据类型
freq=None)- 1.
- 2.
- 3.
- 4.
- 5.
In [54]:
pd.TimedeltaIndex([12, 24, 36, 48], unit='D')- 1.
Out[54]:
TimedeltaIndex(
['12 days', '24 days', '36 days', '48 days'],
dtype='timedelta64[ns]', freq=None)- 1.
- 2.
- 3.
创建方式2:通过timedelta_range函数来间接生成
In [55]:
data1 = pd.timedelta_range(start='1 day', periods=4)
data1- 1.
- 2.
Out[55]:
TimedeltaIndex(['1 days', '2 days', '3 days', '4 days'], dtype='timedelta64[ns]', freq='D')- 1.
In [56]:
pt1 = pd.TimedeltaIndex(data1)
pt1- 1.
- 2.
- 3.
Out[56]:
TimedeltaIndex(
['1 days', '2 days', '3 days', '4 days'],
dtype='timedelta64[ns]', freq='D')- 1.
- 2.
- 3.
In [57]:
data2 = pd.timedelta_range(start='1 day', end='3 days', freq='6H')
data2- 1.
- 2.
Out[57]:
TimedeltaIndex(
['1 days 00:00:00', '1 days 06:00:00', '1 days 12:00:00',
'1 days 18:00:00', '2 days 00:00:00', '2 days 06:00:00',
'2 days 12:00:00', '2 days 18:00:00', '3 days 00:00:00'],
dtype='timedelta64[ns]', freq='6H')- 1.
- 2.
- 3.
- 4.
- 5.
In [58]:
pt2 = pd.TimedeltaIndex(data2)
pt2- 1.
- 2.
- 3.
Out[58]: