关于Alluxio的文章让潭主把注意力转移到了大数据上。
文中提及Cloudera作为Hadoop生态最后的种子选手,为什么没有鼓捣出Alluxio这样的东西?
没想到在学习Cloudera的过程中无意间发现了Ozone,解答了潭主之前的疑问。
技术体系繁杂,存在着很多“平行宇宙”。今天,潭主跟大家分享最近学习的一个数据湖存储技术,Ozone。
Ozone是哪路神
Ozone是Apache软件基金会下的一个项目,其定位是:一个用户大数据分析和云原生应用、具有高扩展性、强一致性的分布式Key-Value对象存储。
看过潭主文章的读者自然对Alluxio有所了解,在使用功能上,Ozone跟Alluxio类似,也兼容支持S3和HDFS的API。
因为上述特性,Ozone可以“透明”地支持现有Hadoop生态中如Spark和Hive等上层计算框架,无需修改应用代码。
套路是一样的,把自己“模仿”成高手的样子。当然,简单模仿肯定不行,还要有属于自己的“创新”。
潭主的“穷人”思维
传统保险行业受限于业务模式,存在很多的数据“孤岛”,每个岛的容量也有限。
不过,这几年非结构化业务数据增长迅猛,之前引入的HCP对象存储已经是上十亿的量级。
虽然之前也上线了一些大数据项目,但据潭主所知,Hadoop集群的规模其实并不大,以至于写此文之前,潭主受限于自身经验对Hadoop其实并无痛感。
即便是互联网行业,十多年前可能也无法预料数据膨胀得如此之快,以至于Hadoop很快就变得力不从心。
互联网的“富人”思维
这两年,数据湖这个词很火。
大家对于数据湖的理解也不尽相同,有人认为Hadoop是数据湖,而有人认为S3也是数据湖。
换个角度,从线上公有云的视角看,S3是主流存储,而到了线下的私有云,Hadoop似乎更有优势一些,这种情况无形中对于混合云的一统江湖形成了存储上的障碍。
因此,面向未来的数据湖技术应该是向上兼容多种主流计算框架,平滑支撑多种应用场景,向下对接不同的存储引擎,实现数据访问接口的标准化。
从最近了解的技术发展趋势看,这种承上启下、统一标准的存储技术将成为下一代数据湖的显著特征。
况且对于互联网,HDFS系统的确在集群扩展性、支持应用标准上的确存在一些局限性。
为了解决HDFS存在的问题,开源社区这些年也没闲着,尝试了不少解决方案。
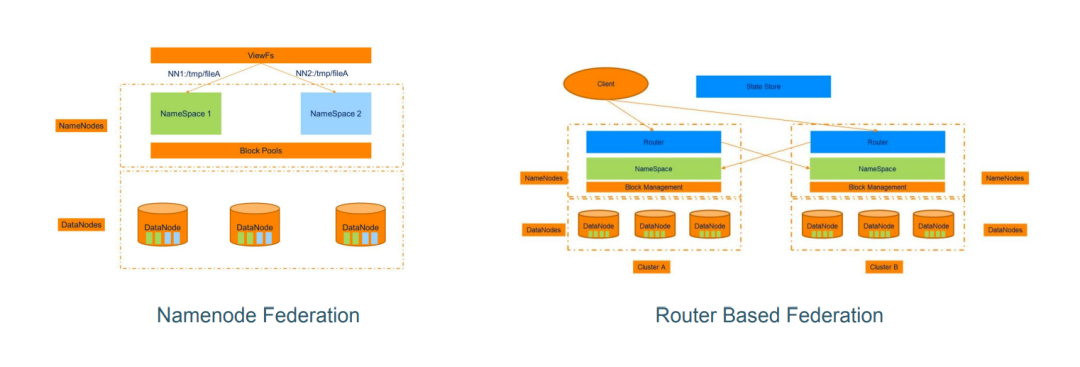
HDFS的“联邦”时代
最初Hadoop集群只允许有一个命名空间(Namespace),且只能被一个NameNode管理。
虽然可以通过添加底层DataNode节点实现集群横向扩展,增加存储空间,但由于所有的Block元数据都驻留在NameNode内存中,在集群规模增大时,NameNode很容易成为瓶颈,直接限制了HDFS的文件、目录和数据块的数量。
Hadoop 社区为了解决HDFS 横向扩展的问题,做了两个联邦方案(如上图):
·
NNF(NameNode Federation)
·
RBF(Router Based Federation)
早期的NNF方案中,集群引入了多个NameNode,分别管理不同的Namespace和对应的BlockPool,多个NameNode可以共享Hadoop集群中的DataNode。
虽然解决了Namespace的扩展问题,但需要对HDFS的Client进行“静态”配置挂载,还要结合ViewFS才能实现统一入口。
而在RBF的联邦方案中,尝试把“挂载表”从Client中抽离出来形成了Router,虽然Hadoop集群是独立的,但同时又增加了一个“State Store”组件,架构变得更复杂。
局部改进的“联邦”方案对于面向未来的大数据存储而言,治标不治本。
青出于蓝而胜于蓝
有时候,最好的优化就是另起炉灶。
毕竟Hadoop技术已经很多年了,当下的软硬件环境已与当初大不相同,系统重构也在情理之中。
与其等别人来革HDFS的命,不如自我革命。目前看,Ozone的确给用户提供了一个新选择。
就好像CDH和HDP最终融合成了CDP一样,HDFS和S3也可以融合成Ozone。
总之,Ozone站在Hadoop这个巨人的肩膀上,设计之初就是为了替换掉HDFS,青出于蓝而胜于蓝。
潭主家的“存储一哥”
早年间接触过Ceph,也搞过HCP(Hitachi Content Platform)对象存储,这些经验对潭主理解Ozone大有裨益。
特意查了一下自家的HCP,发现影像文件已经20多亿个了,存储容量也小2PB。不过查询过程中明显感觉到元数据响应缓慢,估计快该扩容了。
言归正传,再来说说Ozone的核心概念:
· Volume:通常表示用户、业务,与HCP中的租户(Tenant)对应
· Bucket:通常表示业务、应用,与HCP中的命名空间(Namespace)对应
· Key:对应的就是实际的Object
Ozone的存储路径为/Volume/Bucket/Key,一个业务可以对应一个或多个Volume,每个Volume可以包含多个Bucket,在访问方式上Ozone实现了ofs和o3fs的适配和协议封装。
值得注意的是,HCP里面有文件夹的概念,就是说对象文件有层次结构,但Ozone在设计上是扁平的,目录是一个“伪目录”概念,是文件名的一部分,统一作为Key而存在。
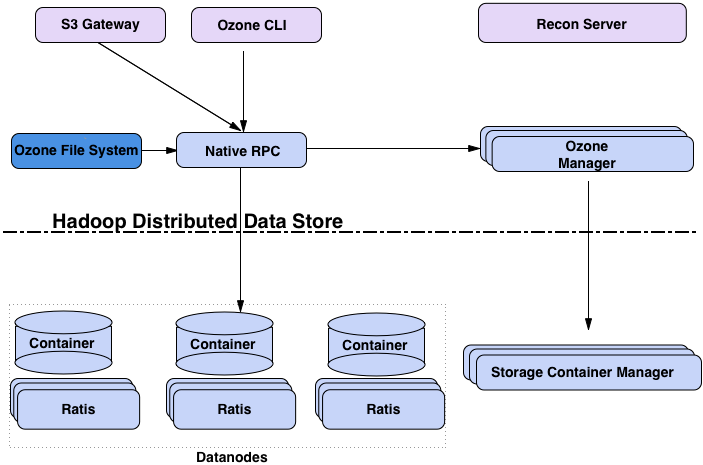
Ozone的体系架构
介绍完了概念,再看看Ozone的体系架构(如上图):
· OM(Ozone Manager):通过RocksDB的K-V方式管理Namespace,Raft协议保持高可用,Shardig实现水平扩展
· SCM(Storage Container Manager):用于Ozone集群管理,负责分配Block,跟踪SC复制状态
· DataNode:负责向SCM汇报SC状态
· SC(Storage Container):Ozone的实际存储单元
· Recon Server:用于监控Ozone集群
Ozone做了架构优化,上层实现职能分离,OM负责管理Namespace,SCM负责管理Storage Containers。
下层实现了一个叫Hadoop Distributed Data Store(HDDS)的高可用、块存储层。
Ozone中的一个DataNode包括多个Storage Container,每个SC的容量(默认5GB,可配置)远大于Hadoop中Block容量(默认128MB),这种设计使得每个DN发送给SCM的Container-Report系统压力要远远小于传统Hadoop集群的Block-Report。
Storage Container作为Ozone的基础存储和复制单元,类似于一个“超级块”,通过其内置RocksDB(key记录BlockID,Value记录object的文件名、偏移量和长度),实现对小文件的块管理。
Ozone,新一代的“融合”数据湖存储
在网上看到之前某互联网大厂专家的分享,现网同时在使用HDFS和Ceph。
HDFS主要用于大数据分析场景,但机器学习场景中受限于大量小文件而使用Ceph。
不过,在介绍Ozone的Roadmap时说未来会在存储层引入Ozone。
开源世界,风起云涌,前脚刚看过Alluxio,觉得眼前一亮,这会儿再看Ozone,更是金光闪闪。
Ozone既是Hadoop的优化升级版,又能“分层”解决海量小文件的对象存储,再加上对云原生CSI的支持,让其成为了新一代“融合”存储。
Ozone这股新势力着实让潭主不敢小觑,希望未来能有机会做些实践。
存储圈,数据不息,折腾不止!