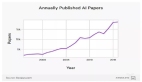
在视觉、语言和语音在内的机器学习诸多领域中,神经标度律表明,测试误差通常随着训练数据、模型大小或计算数量而下降。这种成比例提升已经推动深度学习实现了实质性的性能增长。然而,这些仅通过缩放实现的提升在计算和能源方面带来了相当高的成本。
这种成比例的缩放是不可持续的。例如,想要误差从 3% 下降到 2% 需要的数据、计算或能量会指数级增长。此前的一些研究表明,在大型 Transformer 的语言建模中,交叉熵损失从 3.4 下降到 2.8 需要 10 倍以上的训练数据。此外,对于大型视觉 Transformer,额外的 20 亿预训练数据点 (从 10 亿开始) 在 ImageNet 上仅能带来几个百分点的准确率增长。
所有这些结果都揭示了深度学习中数据的本质,同时表明收集巨大数据集的实践可能是很低效的。此处要讨论的是,我们是否可以做得更好。例如,我们是否可以用一个选择训练样本的良好策略来实现指数缩放呢?
在最近的一篇文章中,研究者们发现,只增加一些精心选择的训练样本,可以将误差从 3% 降到 2% ,而无需收集 10 倍以上的随机样本。简而言之,「Sale is not all you need」。

论文链接:https://arxiv.org/pdf/2206.14486.pdf
总体来说,这项研究的贡献在于:
1. 利用统计力学,开发了一种新的数据剪枝分析理论,在师生感知机学习环境中,样本根据其教师边际进行剪枝,大 (小) 边际各对应于简单 (困难) 样本。该理论在数量上与数值实验相符,并揭示了两个惊人的预测:
a.最佳剪枝策略会因初始数据的数量而改变;如果初始数据丰富 (稀缺) ,则应只保留困难 (容易) 的样本。
b.如果选择一个递增的帕累托最优剪枝分数作为初始数据集大小的函数,那么对于剪枝后的数据集大小,指数缩放是可能的。

2. 研究表明,这两个预测在更多通用设置的实践中依旧成立。他们验证了在 SVHN、CIFAR-10 和 ImageNet 上从头训练的 ResNets,以及在 CIFAR-10 上进行微调的视觉 Transformer 的与剪枝数据集大小有关的误差指数缩放特征。
3. 在 ImageNet 上对 10 个不同的数据剪枝度量进行了大规模基准测试研究,发现除了计算密集度最高的度量之外,大多数度量表现不佳。
4. 利用自监督学习开发了一种新的低成本无监督剪枝度量,不同于以前的度量,它不需要标签。研究者证明了这种无监督度量与最好的监督剪枝度量相媲美,而后者需要标签和更多的计算。这个结果揭示了一种可能性:利用预训练基础模型来修剪新数据集。
Is scale all you need?
研究者的感知器数据剪枝理论提出了三个惊人的预测,可以在更通用的环境下进行测试,比如在 benchmark 上训练的深度神经网络:
(1) 相对于随机数据剪枝,当初始数据集比较大时,只保留最难的样本是有收益的,但当初始数据集比较小时,这样反而有害;
(2) 随着初始数据集大小的增加,通过保留最难样本的固定分数 f 进行的数据剪枝应该产生幂律缩放,指数等于随机剪枝;
(3) 在初始数据集大小和所保留数据的分数上优化的测试误差,可以通过在更大初始数据集上进行更积极的剪枝,追踪出一个帕累托最优下包络线,打破了测试误差和剪枝数据集大小之间的幂律缩放函数关系。

研究者用不同数量的初始数据集大小和数据剪枝下保存的数据分数 (图 3A 中的理论对比图 3BCD 中的深度学习实验) ,在 SVHN、CIFAR-10 和 ImageNet 上训练的 ResNets 验证了上述三个预测。在每个实验设置中,可以看到,较大的初始数据集大小和更积极的剪枝比幂律缩放表现更好。此外,更大的初始数据集可能会看到更好的缩放(如图 3A)。
此外,研究者发现数据剪枝可以提升迁移学习的表现。他们首先分析了在 ImageNet21K 上预训练的 ViT,然后在 CIFAR-10 的不同剪枝子集上进行了微调。有趣的是,预训练的模型允许更积极的数据剪枝;只有 10% 的 CIFAR-10 的微调可以媲美或超过所有 CIFAR-10 的微调所获得的性能 (图 4A)。此外,图 4A 提供了一个在微调设置中打破幂律缩放的样本。

通过在 ImageNet1K 的不同剪枝子集 (如图 3D 所示) 上预训练 ResNet50,研究者检查了剪枝预训练数据的功效,然后在 CIFAR-10 上对它们进行微调。如图 4B 所示,在最少 50% 的 ImageNet 上进行的预训练能够达到或超过在所有 ImageNet 上进行的预训练所获得的 CIFAR-10 性能。
因此,对上游任务的训练前数据进行剪枝仍然可以在不同的下游任务上保持高性能。总体来说,这些结果显示了剪枝在预训练和微调阶段的迁移学习中的前景。
在 ImageNet 上对监督剪枝指标进行基准测试
研究者注意到,大多数的数据剪枝实验都是在小规模数据集(即 MNIST 和 CIFAR 的变体)上进行的。所以,为 ImageNet 提出的少数剪枝度量很少与在较小数据集上设计的 baseline 进行比较。
因此,目前尚不清楚大多数剪枝方法如何缩放到 ImageNet 以及哪种方法最好。为研究剪枝度量的质量在理论上对性能的影响,研究者决定通过在 ImageNet 上对 8 个不同的监督剪枝度量进行系统评估来填补这一知识空白。

他们观察到度量之间的显著性能差异:图 5BC 显示了当每个度量下的最难样本的一部分保留在训练集中时的测试性能。在较小的数据集上,许多度量取得了成功,但选择一个明显较小的训练子集(如 Imagenet 的 80%)时,只有少数度量在完整数据集训练中仍然获得了相当的性能。
尽管如此,大多数度量仍然优于随机剪枝(图 5C)。研究者发现所有剪枝度量都会放大类的不平衡,从而导致性能下降。为了解决这个问题,作者在所有 ImageNet 实验中使用了一个简单的 50% 类平衡率。
通过原型度量进行自监督数据剪枝
如图 5 ,许多数据剪枝度量不能很好地缩放到 ImageNet,其中一些确实需要大量计算。此外,所有这些度量都需要标注,这限制了它们为在大量未标注数据集训练大规模基础模型的数据剪枝能力。因此,我们显然需要简单、可缩放、自监督的剪枝度量。

为了评估度量发现的聚类是否与 ImageNet 类一致,研究者在图 6A 中比较了它们的重叠。当保留 70% 以上的数据时,自监督度量和监督度量的性能是相似的,这表明了自监督剪枝的前景。
更多研究细节,可参考原论文。