背景
Java 多线程开发中为了保证数据的一致性,引入了同步锁(synchronized)。但是,对锁的过度使用,可能导致卡顿问题,甚至 ANR:
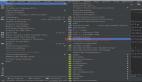
- Systrace 中的主线程因为等锁阻塞了绘制,导致卡顿


- Slardar 平台(字节跳动内部 APM 平台,以下简称 Slardar)中搜索 waiting to lock 关键字发现很多锁导致的 ANR,仅 Java 锁异常占到总 ANR 的 3.9%

本文将着重向大家介绍 Slardar 线上锁监控方案的原理与使用方法,以及我们在抖音上发现的锁的经典案例与优化实践。
监控方案
获取运行时锁信息的方法有以下几种
方案 | 应用范围 | 特点 |
systrace | 线下 |
|
定制 ROM | 线下 |
|
JVMTI | 线下 |
|
考虑到,很多锁问题需要一定规模的线上用户才能暴露出来,另外没有调用栈难以从根本上定位和解决线上用户的锁问题。最终我们自研了一套线上锁监控系统,它需要满足以下要求:
- 线上监控方案
- 丰富的锁信息,包括 Java 调用栈
- 数据分析平台,包括聚合能力,设备和版本信息等
- 可纳入开发和合码流程,防止不良代码上线
这样的锁监控系统,能够帮助我们高效定位和解决线上问题,并实现防劣化。
锁监控原理
我们先从 Systrace 入手,有一类常见的耗时叫做 monitor contention,其实是 Android ART 虚拟机输出的锁信息。

简单介绍一下里面的信息
monitor contention with owner work_thread (27176) at android.content.res.Resources android.app.ResourcesManager.getOrCreateResources(android.os.IBinder, android.content.res.ResourcesKey, java.lang.ClassLoader)(ResourcesManager.java:901) waiters=1 blocking from java.util.ArrayList android.app.ActivityThread.collectComponentCallbacks(boolean, android.content.res.Configuration)(ActivityThread.java:5836)
- 持锁线程:work_thread
- 持锁线程方法:android.app.ResourcesManager.getOrCreateResources(...)
- 等待线程 1 个
- 等锁方法:android.app.ActivityThread.collectComponentCallbacks(...)
Java 锁,无论是同步方法还是同步块,虚拟机最终都会到 MonitorEnter。我们关注的 trace 是 Android 6 引入的, 在锁的开始和结束时分别调用ATRACE_BEGIN(...) 和 ATRACE_END()


线上方案
默认情况下 atrace 是关闭的,开关在 ATRACE_ENABLED() 中。我们通过设置 atrace_enabled_tags 为 ATRACE_TAG_DALVIK 可以开启当前进程的 ART 虚拟机的 atrace。
再看 ATRACE_BEGIN(...) 和 ATRACE_END() 的实现,其实是用 write 将字符串写入一个特殊的 atrace_marker_fd (/sys/kernel/debug/tracing/trace_marker)。


因此通过 hook libcutils.so 的 write 方法,并按 atrace_marker_fd 过滤,就实现了对 ATRACE_BEGIN(...) 和 ATRACE_END() 的拦截。有了 BEGIN 和 END 后可以计算出阻塞时长,解析 monitor contention with owner... 日志可以得到我们关注的 Java 锁信息。
获取堆栈
到目前为止,我们已经可以监控到线上用户的锁问题。但是还不够,为了能够优化锁的性能,我们想需要知道等锁的具体原因,也就是 Java 调用栈。
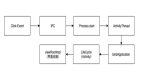
获取 Java 调用栈,可以使用Thread.getStackTrace()方法。由于我们 hook 住了虚拟机的等锁线程,此时线程处于一种特殊状态,不可以直接通过 JNI 调用 Java 方法,否则导致线上 crash 问题。

解决方案是异步获取堆栈,在 MonitorBegin 的时候通知子线程 5ms 之后抓取堆栈,MonitorEnd 计算阻塞时长,并结合堆栈数据一起放入队列,等待上报 Slardar。如果 MonitorEnd 时不满足 5ms 则取消抓栈和上报

数据平台
由于方案本身有一定性能开销,我们仅对灰度测试中的部分用户开启了锁监控。配置线上采样后,命中的用户将自动开启锁监控,数据上报 Slardar 平台后就可以消费了。

具体 case 可以看到设备信息、阻塞时长、调用堆栈

根据调用栈查找源码,可以定位到是哪一个锁,说明上报数据是准确的。

稳定性方面,10 万灰度用户开启锁监控后,无新增稳定性问题。


优化实践
经过多轮锁收集和治理,我们取得了一些不错的收益,这里简单介绍下锁治理的几个典型案例。
典型案例
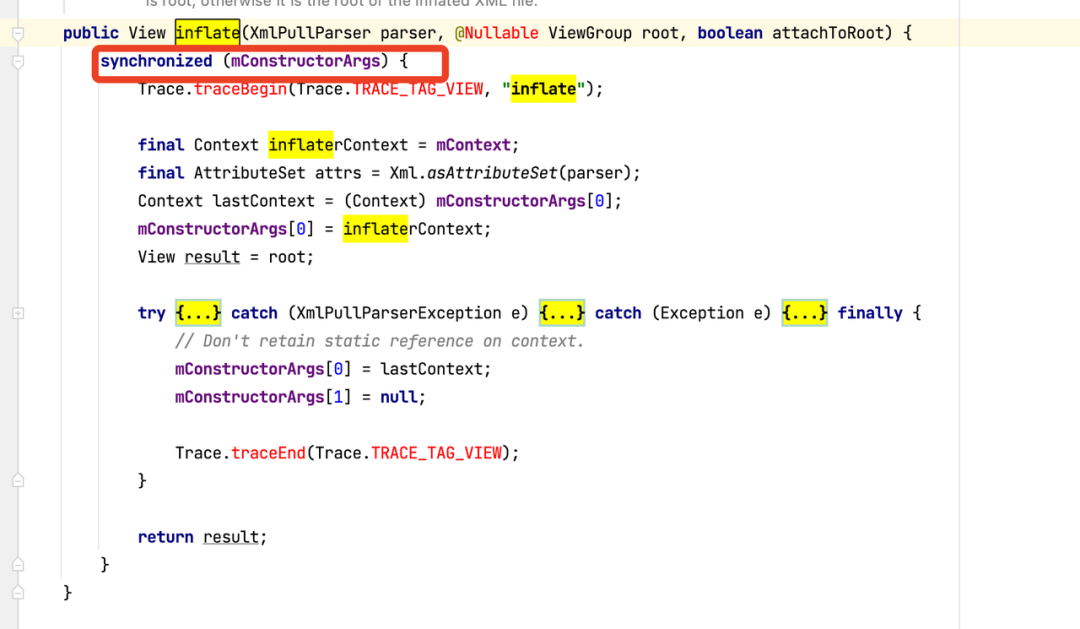
inflate 锁:
先解析一下什么是 inflate:Android 中解析 xml 生成 View 树的过程就叫做 inflate 过程。inflate 是一个耗时过程,常规的手段就是通过异步来减少其在主线程的耗时,这样大大的减少了卡顿、页面打开和启动时长;但此方式也会带来新的问题,比如 LayoutInflater 的 inflate 方法中有加锁保护的代码块,并行构建会造成锁等待,可能反而增加主线程耗时,针对这个问题有三种解决方案:
克隆 LayoutInflater
- 把线程分为三类别:Main、工作线程和其它线程(野线程),Context(Activity 和 App)为每个类别提供专有 LayoutInflater,这样能有效的规避 inflate 锁。
- 优点:实现简单、兼容性好
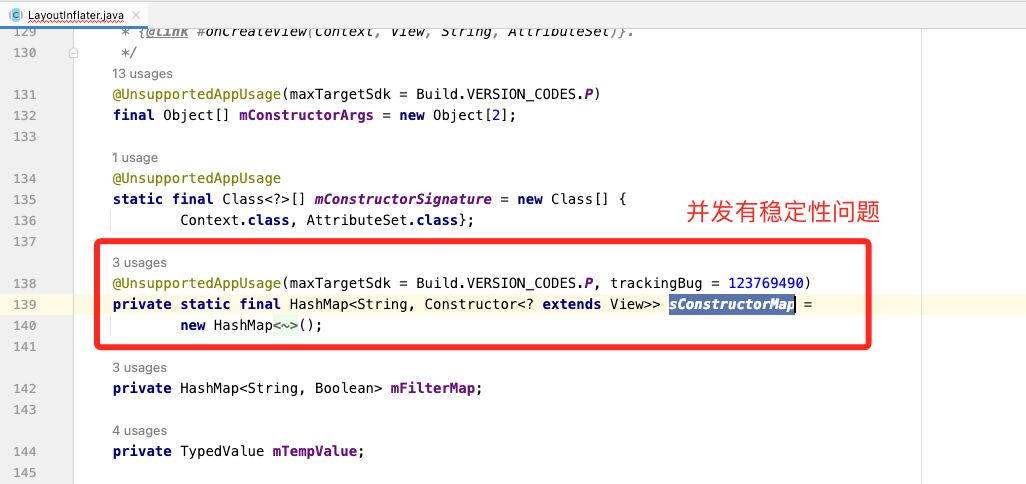
- 缺点:LayoutInflater 中非安全的静态属性在并发情况下有概率产生稳定性问题
code 构造替代 xml 构造
- 这种方式完美的绕开了 inflate 操作,极大提高了 View 构造速度。
- 优点:复杂度高、性能好
- 缺点:影响编译速度、View 自定义属性需要做转换、存在兼容性问题(比如厂商改属性)
定制 LayoutInflater
- 自定义 FastInflater(继承自 LayoutInflater)替换系统的 PhoneLayoutInflater,重写 inflate 操作,去掉锁保护;从统计数据看,在并发时快了约 4%。
- 优点:复杂度高、性能好
- 缺点:存在兼容性,比如华为的 Inflater 为 HwPhoneLayoutInflater,无法直接替换。
 文件目录锁:
文件目录锁:
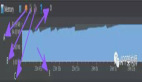
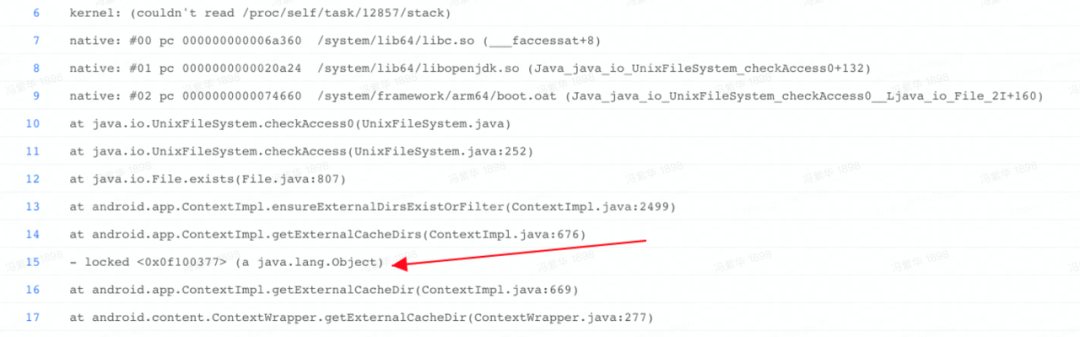
ContextImpl 中获取目录(cache、files、DB 和 preferenceDir)的实现有两个关键耗时点:1. 存在 IPC(IStorageManager.mkdir)和文件 check;2. 加锁“nSync”保护;所以 ipc 变长和并发存在,都可能导致 App 卡顿,如图为 Anr 数据:


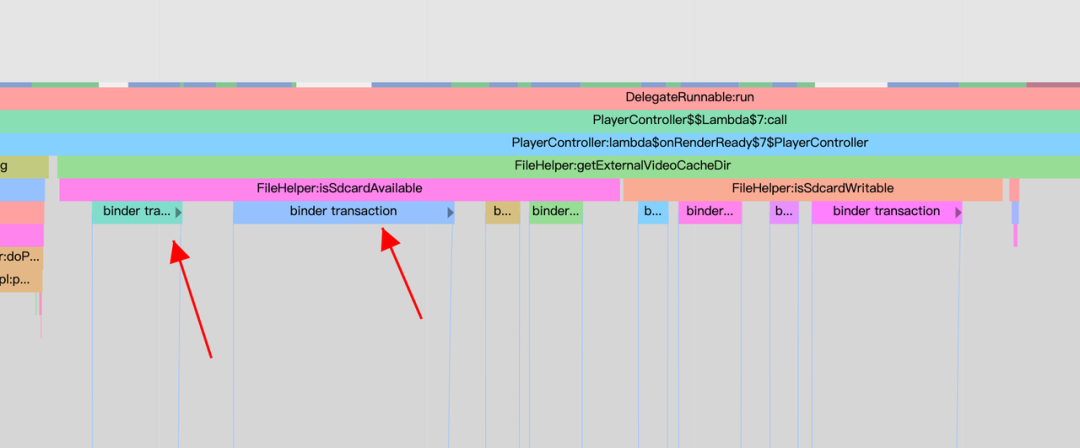
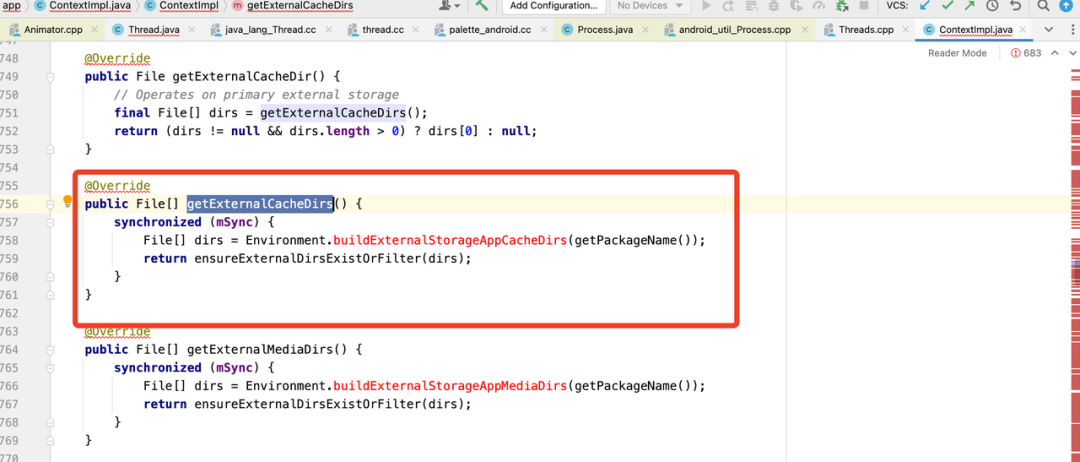
相关的常用 Api 有 getExternalCacheDir、getCacheDir、getFilesDir、getTheme 等,考虑到系统的部分目录一般不会发生变化,所以我们可以对一些不会变化的目录进行 cache 处理,减少带 锁方法块的执行,从而有效的绕过锁等待。
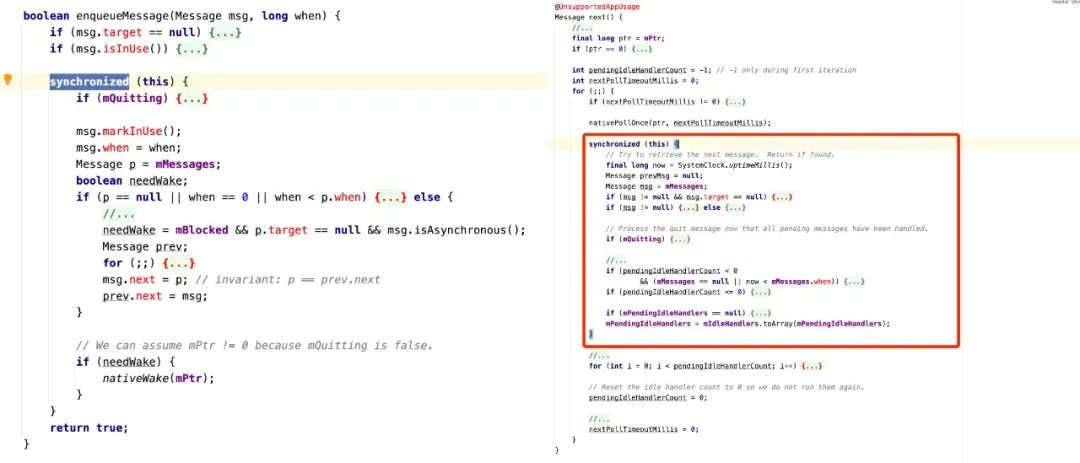
MessageQueue:
Android 子线程与主线程通讯的通用方式是向主线程 MessageQueue 中插入一个任务(message),等此任务(message)被主线程 Looper 调度执行;所以 MessageQueue 中会对消息链表的修改加锁保护,主要实现在 enqueueMessage 和 next 两个方法中。
利用 Slardar 采集线上锁信息,根据这些信息,我们可以轻松追踪锁的执有线程和 owner,最后根据情况将请求(message)移到子线程,这样就可以极大的减轻主线程压力和等锁的可能性。此问题的修改方式并不复杂,重点在于如何监控到这些执锁线程。
 序列化和反序列化:
序列化和反序列化:
抖音中有一些常用数据对象使用 Json 格式存储。为保证这些数据的完整性,在读取和存储时加了锁保护,从而导致锁等待比较常见,这种情况在启动场景特别明显;所以要想减少锁等待,就必段加快序列化和反序列化,针对这个问题,我们做了三个优化方案:
- Gson 反序列化的耗时集中在 TypeAdapter 的构建,此过程利用反射创建 Filed 和 name(key)的映射表;所以我们在编译时针对数据类创建对应的 TypeAdapter,大大减少反序列化的时耗。
- 部分类使用 parcel 序列化和反序列化,大大提高了速度,约减少 90%的时耗。
- 大对像根据情况拆分成多个小对像,这样可以减少锁粒度,也就减少了锁等待。以上方案在抖音项目中都有使用,取得了很不错的收益。
AssetManager 锁:
获取 string、size、color 或 xml 等资源的最终实现基本都封装在 AssertManager 中,为了保证数据的正确性,加了锁(对象 AssetManager)保护,大致的调用关系如图:

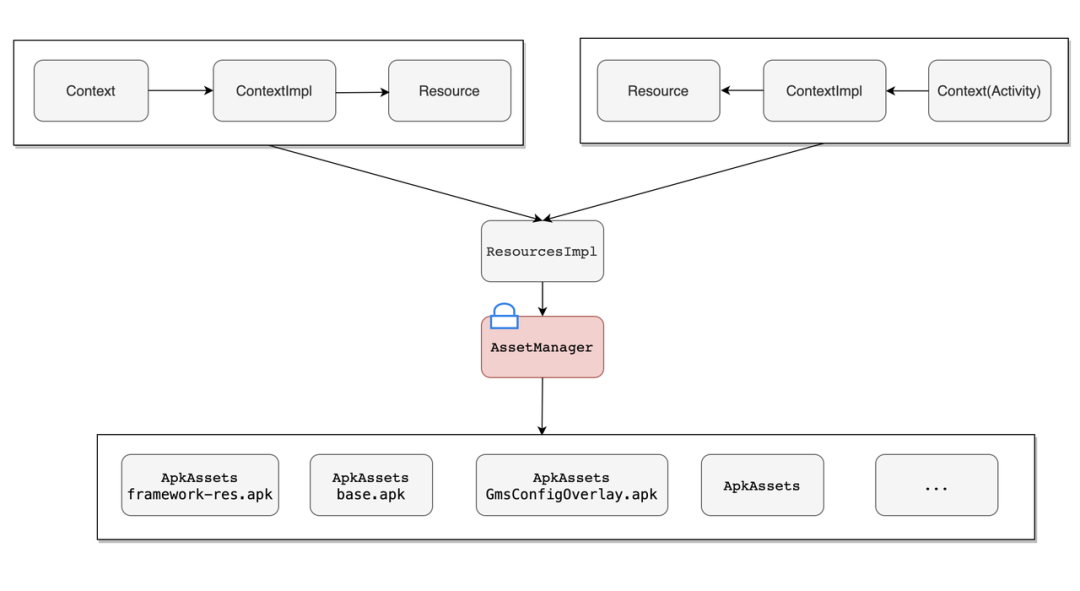
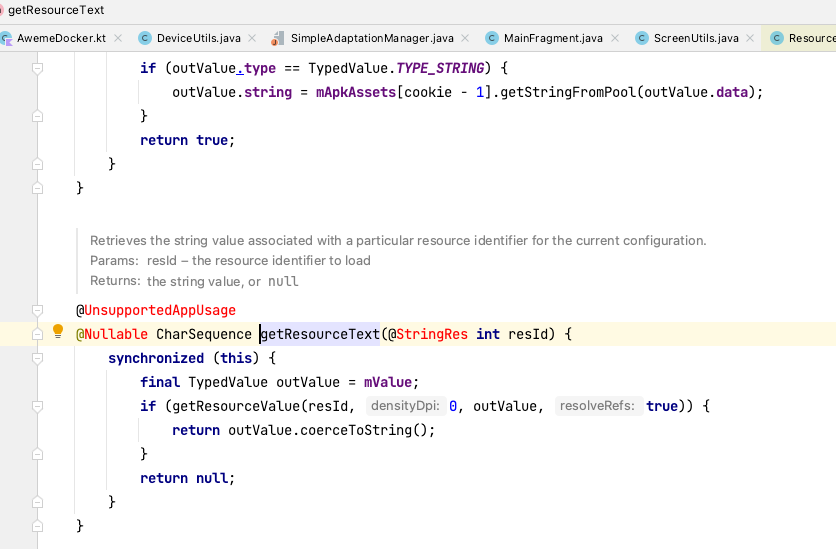
常用的调用点有:
- View 构造方法中调用 context.obtainStyledAttributes(...)获取 TypedArray,最后都会调用 AssetManager 的带锁方法。
- View 的 toString 也调用了 AssetManager 的带锁方法。
随着 xml 异步 inflate 的增加,这些方法并发调用也增加,造成主线程的锁等待也日渐突出,最终导致卡顿,针对这个问题,目前我们的优化方案主要有:
- 去掉多余的调用,比如 View 的 toString,这个常见于日志打印。
- 一个 Context 根据线程名提供不同的 AssetManager,绕过 AssetManager 对象锁;此方法可能带来一些内存消耗。
So 加载锁优化:
Android 提供的加载 so 的接口实现都在封装在 Runtime 中,比如常用的 loadLibrary0 和 load0,如图 1 和 l 图 2 所示,此方法是加了锁的,如果并发加载 so 就会造成锁等待。通过 Slardar 的监控数据,我们验证了这个问题,同时也有一些意外收获,比如平台可能有自己的 so 需要加:


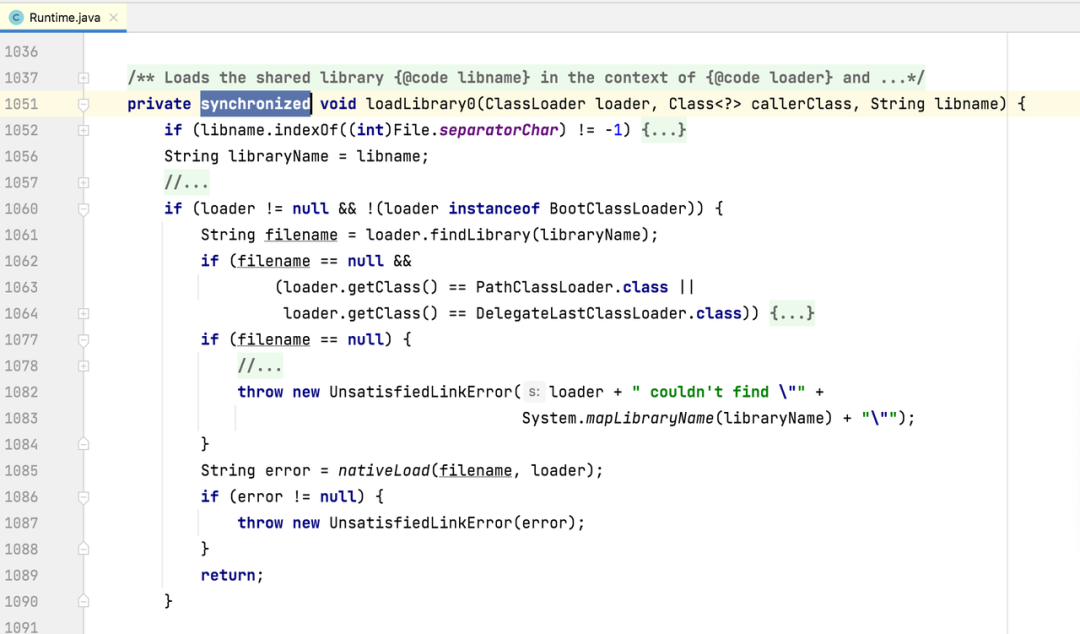
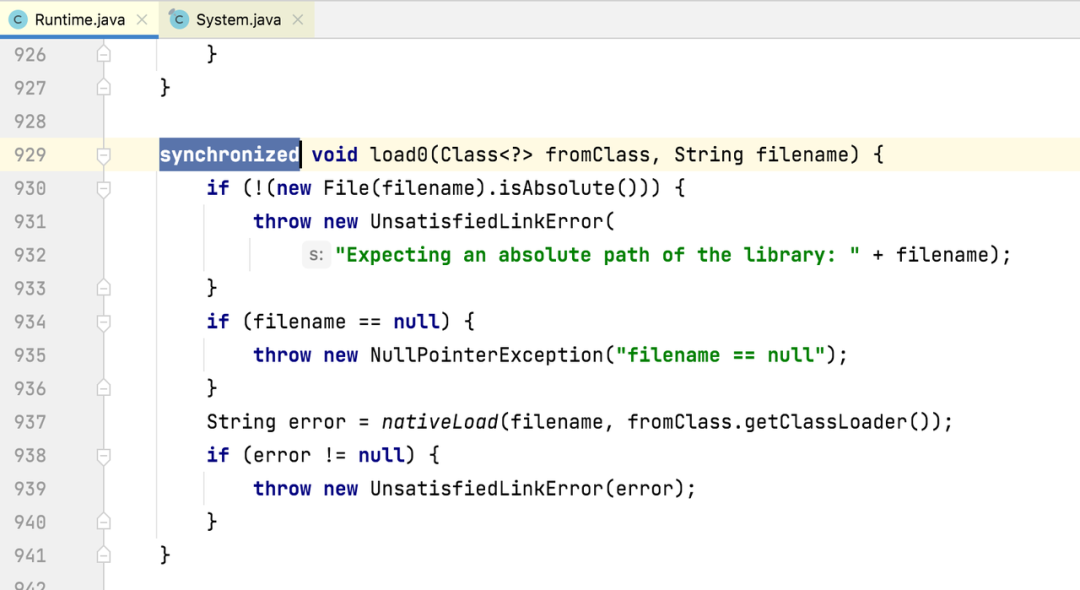
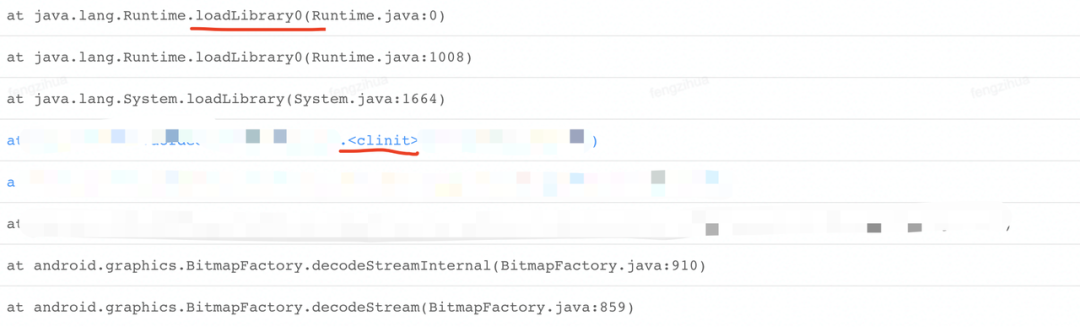
我们根据 so 的不同情况,主要有以下优化思路:
- 对于 cinit 加载的 so,我们可以提前在子线程中加载一下 cinit 的宿主类。
- 业务层面的 so, 可以统一在子线程中进行提前加载。
- 使用 load0 替代 loadLibrary0,可以减少锁中拼接 so 路径的时耗。
- so 文件加载优化,比如 JNI_OnLoad。
ActivityThread:
在收集的的数据中我们也发现了一些系统层的框架锁,比如下图这个:

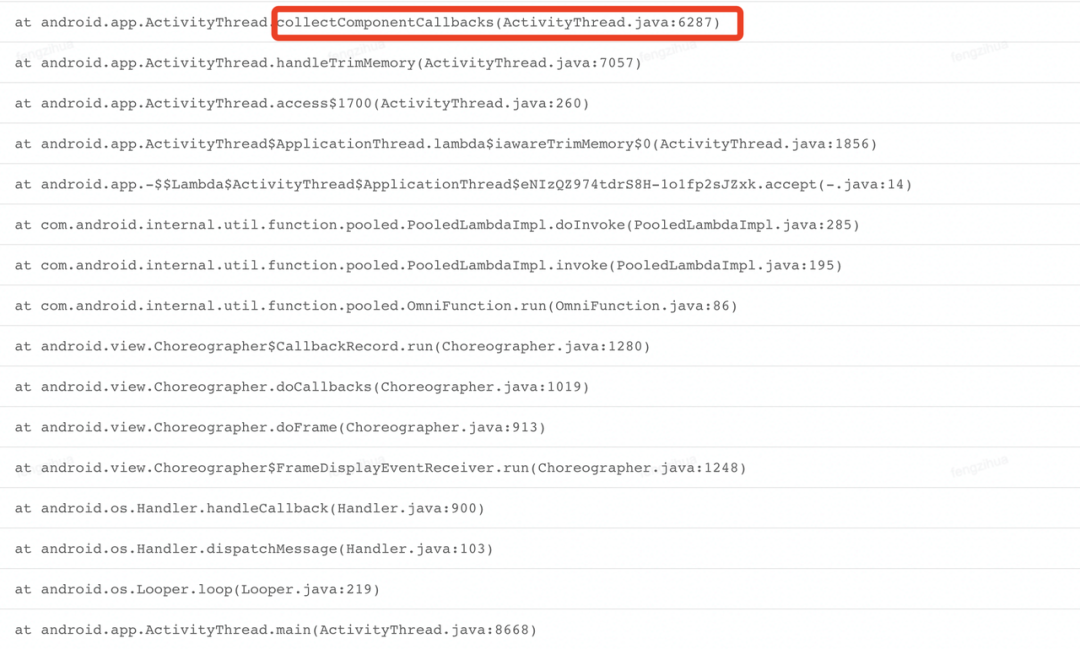
这个问题主要集中在启动阶段,ams 会发 trim 通知给 ActivityThread 中的 ApplicationThread,收到通知后会向 Choreographer 的 commit 列表(此任务列表不作展开)中添加一个 trim 任务,也就是在下个 vsync 到达时被执行;
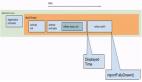
trim 过程主要包括收集 Applicatioin、Activity、Service、Provider 和向它们发送 trim 消息,也是系统提供给业务清理自身内存的一个时机;收集过程是加锁(ResourcesManager)保护的,如图:



考虑到启动阶段并不太关心内存的释放,所以可以尝试在启动阶段,比如 40 秒内,不执行 trim 操作;具体的实现是这样,首先替换 Choreographer 的 FrameHandler, 这样就能接管 vsync 的 doFrame 操作,在启动 40 秒内的每次 vsync 主动 check 或删除 commint 任务列表中的 trim 操作。

收益
在抖音中我们除了优化前面列出的这些典型锁外,还优化了一些业务本身的锁,部分已经通过线上实验验证了收益,也有一些还在尝试实验中;通过对实验中各指标的分析,也证实了锁优化能带来启动和流畅度等技术收益,间接带来了不错的业务收益,这也坚定了我们在这个方向上的继续探索和深化。
小结
前面列出的只是有代表性的一些通用 Java 锁,在实际开发中遇到的远比这多,但不管什么样的锁,都可以根据进程和代码归属分为以下四类:业务锁、依赖库锁、框架锁和系统锁;
不同类型的锁优化思路也会不一样,部分方案可以复用,部分只能 case-by-case 解决,具体的优化方案有:减少调用、绕过调用、使用读写锁和无锁等。

分类 | 描述 | 进程 | 代码 | 优化方案 |
业务锁 | 源码可见,可以直接修改;比如前面的序列化优化。 | App 进程 | 包含 | 直接优化;静态 aop |
依赖库锁 | 包含编译产物,可以修改产物 | App 进程 | 包含 | 直接优化;静态 aop |
框架锁 | 运行时加载,同时存在兼容性;比如前面提到的 inflate 锁、AssetManager 锁和 MessageQueue 锁 | App 进程 | 不包含 | 减少调用;动态 aop |
系统锁 | 系统为 App 提供的服务和资源,App 间存在竞争,所以服务层需要加锁保护,比如 IPC、文件系统和数据库等 | 服务进程 | 不包含 | 减少调用 |
总结
经过了长达半年的探索和优化,此方案已在线上使用,作为我们日常防劣化和主动优化的输入工具,我们评判的点主要有以下四个:
- 稳定性:线上开启后,ANR、Crash 和 OOM 和大盘一致。
- 准确性:从目前线上的消费数据来看,这个值达到了 99%。
- 扩展性:业务可以根据场景开启和关闭采集功能,也可以收集指定时间内的锁,比如启动阶段可以收集 32ms 的锁,其它阶段收集 16ms 的锁。
- 劣化影响:从线上实验数据看,一定量(UV)的情况下,业务和性能(丢帧和启动)无显著劣化。
此方案虽然只能监控 synchronized 锁,像 CAS、Native 锁、sleep 和 wait 都无法监控,但在我们日常开发中synchronized 锁占比非常大, 所以基本满足了我们绝大部分的需求,当然,我们也在持续探索其它锁的监控和验证其价值。