作者 | 赵青窕
审校 | 孙淑娟
内核内存管理比较复杂,主要包含了Buddy算法,vmalloc管理,slab算法,kmapper及与初始化阶段物理内存管理相关的两个模块memblock和bootmem。除了上述模块外,还有内存迁移,水线检测,kmemleak,内存信息统计,PCP等辅助内容。在本文中,我将重点介绍Buddy算法(又称为伙伴算法),该算法是以页为单位进行管理的。

Buddy算法介绍
目前,内核中的Buddy算法采用下图的方式管理内存。我把Buddy算法分为如下图所示的三部分,在区域一中,核心的数据结构是struct zone;在区域二中核心的数据结构是struct free_area free_area[MAX_ORDER];在区域三中,page链表是核心内容。接下来,我将详细介绍这三个板块,并通过分配函数来说明Buddy的工作细节。
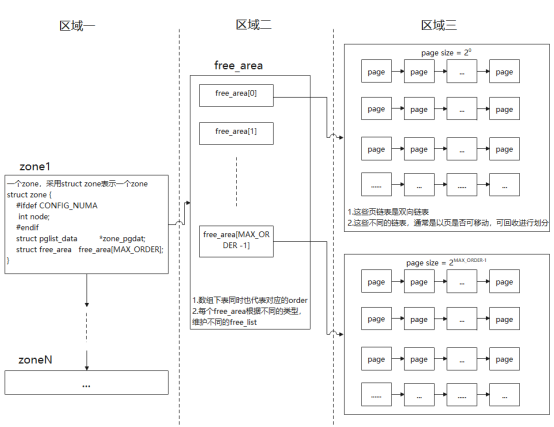
图 1 Buddy框架
1.区域
通常用zone代表不同的内存管理区,即把内存划分成不同的组,每个组就是一个zone。
在内核中,每个zone通过结构体struct zone来表示,其结构体中主要成员如下:
struct zone {
unsigned long watermark[NR_WMARK];
unsigned long zone_start_pfn;
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
struct free_area free_area[MAX_ORDER];
const char *name;
struct pglist_data *zone_pgdat;
}
- 标识内存水线的成员unsigned long watermark[NR_WMARK],其中NR_WMARK定义如下:
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};
从上面定义可知,每个zone存在三个水线,若当前zone中空闲页高于WMARK_HIGH,则当前zone区的空闲内存较多;若空闲页低于WMARK_LOW,则交换守护进程开始将内存交换到磁盘上;若空闲页低于WMARK_MIN,则内存回收系统还需要大量回收内存。在使用Buddy进行内存申请时,会进行水线判断,从而进行相应的操作;
- 伙伴系统管理相关的成员
unsigned long zone_start_pfn;
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
struct free_area free_area[MAX_ORDER]
前四个是相应zone区对应的页号信息,free_area是伙伴算法中的关键成员,也是区域一和区域二衔接的关键成员,每个zone区会划分为MAX_ORDER个组,数组free_area中的每个成员就代表一个组。
- 成员const char *name指明了对应zone区的名称,通常情况下为dma,Normal或highmem,其中highmem不会出现在64位的系统中;下面是典型的32位系统中的zone划分方式:
ZONE_DMA(0~16M):DMA内存分配区;
ZONE_NORMAL(16MB~896MB):普通映射的内存区域;
ZONE_HIGHMEM(896MB~):高端内存区域,其中的页不能永久映射到内核地址空间;内核一般不使用,如果要使用,通过kmap做动态映射;
- 指向zone区对应node的指针成员struct pglist_data *zone_pgdat,node是内存管理中的一个重要成员。对于UMA架构,仅有一个node,所有的zone均属于同一个node,但对于NUMA架构,会有多个不同的node,每个node又划分为不同的zone,所有zone区也是通过struct pglist_data组织在一起的。
2.free_area和页面链表
在内存管理和分配过程中,有一个重要参数order,当我们采用kmalloc申请大内存时,最后会调用函数__alloc_pages_nodemask来进行内存申请。该函数需要一个参数order,当order = 0时,表示要申请的内存大小是1(2的0次方)个页面;当order = 1时,表示要申请的内存大小是2(2的1次方)个页面。
次方在Buddy算法中,把内存按照2的幂次方(即2的order次方,order的范围从0到MAX_ORDER)划分成不同的组,每个组分别用对应的free_area[order]表示,例如free_area[0]对应的就是由内存块大小为2的0次方的页块组成的组,free_area[1]对应的就是内存由块大小为2的1次方的页块组成的组,而结构体结构区域正是通过成员free_area把图1中的区域一和区域二串联在一起。
结构体struct free_area定义如下(不同平台或者不同内核会有差异,但核心思想相同):
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
从该结构可以看出,每一个free_area又根据MIGRATE_TYPES划分为不同的组,每组分别通过链表free_list把同一类页块串联在一起,这样free_list就把图1中的区域二和区域三串联在一起了,从而间接的把区域一和区域三关联在一起了。
结构体结构 page比较复杂,其中有一个成员结构list_head lru,通过该成员把图1中区域三中的页块同区域二中对应的free_list链接在一起。
Buddy内存分配与释放
在此,我将通过一个示例来简要地展示Buddy内存分配的核心思想。当通过Buddy分配一个物理页(即order = 0)时,会从对应zone区中free_area[0]管理的区域分配一个页面(暂时先不考虑PCP的情况),并将该页面从 free_area[0] 链表中移除;当free_area[0] 上没有可用的物理页时,Buddy会在free_area[1]上查找,若存在可用的物理页,则将该页块从free_area[1] 的链表中移除,同时把该页块拆分成两块,其中一块插入到free_area[0]中,另一块传递给内存请求者;倘若free_area[1]上也没有可用页,则会继续向上查找。
下图2所示是没有对应oder = 0的页块情况,因此把order = 1中的一个页块进行拆分,一半返回给order = 1的链表,一半返回给请求者。假如order = 1中没有需要的页块,在内存分配过程中会继续从order = 3中进行查找,直到找到页块或者遍历完所有order。
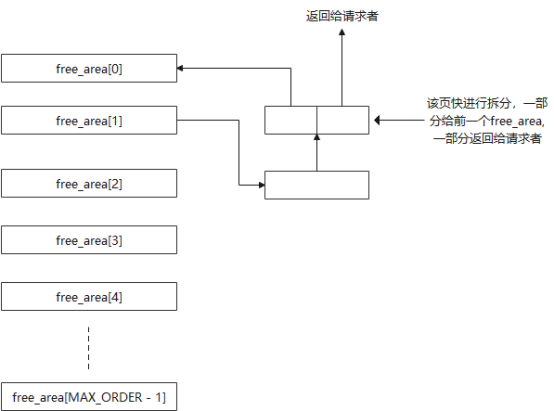
图 2 分配物理页面示意图
实际上,在整个内存分配过程中,会伴随很多特殊情况处理。Buddy算法在进行内存分配时,会根据水线设置,来进行内存回收或者唤醒内核线程kswapd,或者是采用CPU的冷热页面队列进行内存分配,或者是进行页面移动等。假如已经尝试页面移动,kswapd已经唤出了一些页面,同时也进行了内存回收,依然没有可分配的内存,此时就会触发out_of_memory。总之,这些特殊情况的处理方式均离不开图1所示的Buddy框架。
下图是我根据我本地的代码整理的采用kmalloc申请大内存时的调用过程(使用kmalloc申请小内存时不通过Buddy),其中最关键的内存分配函数是prepare_alloc_pages,get_page_from_freelist,rmqueue 和__alloc_pages_slowpath。感兴趣的朋友可以结合图1所示的框架查看这几个函数的具体实现。
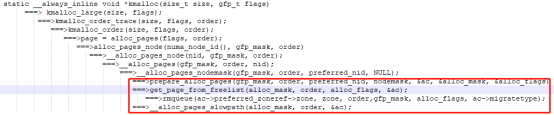
当向系统释放一个物理页的时候,会通过struct page来推导出该page对应的zone区(比如该page属于NORMAL区)和对应的page类型,紧接着将根据对应的order进行页的合并(即图1中区域三的部分进行合并),最后将合并后的块插入到新的order中去,这个合并过程一直持续下去,直到不能合并或者已经合并到最大的order处。例如当释放的物理页得到其属于NORMAL区的free_area[0],此时free_area[0]中存在页面可以和释放的页面合并,从而把合并后的添加到free_area[1]中,这个合并操作会一直持续下去,直到合并完为止。这个过程实际上就是图2的反过程。
总结
内存的管理比较复杂,本文主要介绍了Buddy的核心思想,但这仅仅是内存管理的冰山一角,却是比较基础且核心的内容,因此了解Buddy整体架构是非常有必要的。
作者介绍
赵青窕,51CTO社区编辑,从事多年驱动开发。研究兴趣包含安全OS和网络安全领域,发表过网络相关专利。