抛出疑无路?
【Flink 1.10】- 有一种情况是所有的系统或应用之间的桥梁都是Kafka,而这个时候恰恰是上游需要做Unbound的聚合统计。From @PyFlink 企业用户。
示例代码:
INSERT INTO kafkaSink
SELECT
id,
SUM(cnt)
FROM csvSource
GROUP BY id
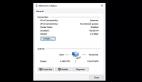
执行这个SQL,在【Flink 1.10】版本会抛出如下异常:

再现又一村!
【Flink-1.10】这个问题是因Flink内部Retract机制导致,在没有考虑对Chanage log全链路支持之前,无法在Kafka这样的Append only的消息队列增加对Retract/Upsert的支持。这个做法是出于语义完整性考虑做出的决定。但现实业务场景总是有着这样或那样的实际业务需求,业务不关心你语义是否okay,业务关心我不改变我原有的技术选型。
在这个基础之上只要你告诉我Sink到Kafka的行为就行,我会根据你的产出行为,在业务上面做适配,所以这个时候就是实用为主,不管什么语义不语义了......,所以这个时候应该怎么办呢?
我们的做法是将 Kafka的sink由原有的AppendStreamTableSink变成UpsertStreamTableSink或者RetractStreamTableSink。但出于性能考虑,我们改变成UpsertStreamTableSink,这个改动不多,但是对于初学者来讲还是不太愿意动手改代码,所以为大家提供一份:
- KafkaTableSinkBase.java
https://github.com/sunjincheng121/know_how_know_why/blob/master/QA/upsertKafka/src/main/java/org/apache/flink/streaming/connectors/kafka/KafkaTableSinkBase.java
- KafkaTableSourceSinkFactoryBase.java
https://github.com/sunjincheng121/know_how_know_why/blob/master/QA/upsertKafka/src/main/java/org/apache/flink/streaming/connectors/kafka/KafkaTableSourceSinkFactoryBase.java
在你的项目创建 org.apache.flink.streaming.connectors.kafka包 并把上面的两个类放入该包,用于覆盖官方KafkaConnector里面的实现。
特别强调:这样的变化会导致写入Kafka的结果不会是每个Group Key只有一条结果,而是每个Key可能有很多条结果。这个大家可以自行测试一下:
package cdc
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.scala._
/**
* Test for sink data to Kafka with upsert mode.
*/
object UpsertKafka {
def main(args: Array[String]): Unit = {
val sourceData = "file:///Users/jincheng.sunjc/work/know_how_know_why/QA/upsertKafka/src/main/scala/cdc/id_cnt_data.csv"
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = StreamTableEnvironment.create(env)
val sourceDDL = "CREATE TABLE csvSource (" +
" id VARCHAR," +
" cnt INT" +
") WITH (" +
"'connector.type' = 'filesystem'," +
"'connector.path' = '" + sourceData + "'," +
"'format.type' = 'csv'" +
")"
val sinkDDL = "CREATE TABLE kafkaSink (" +
" id VARCHAR," +
" cnt INT " +
") WITH (" +
"'connector.type' = 'kafka'," +
"'connector.version' = '0.10'," +
"'connector.topic' = 'test'," +
"'connector.properties.zookeeper.connect' = 'localhost:2181'," +
"'connector.properties.bootstrap.servers' = 'localhost:9092'," +
"'connector.properties.group.id' = 'data_Group'," +
"'format.type' = 'json')"
tEnv.sqlUpdate(sourceDDL)
tEnv.sqlUpdate(sinkDDL)
val sql = "INSERT INTO kafkaSink" +
" SELECT id, SUM(cnt) FROM csvSource GROUP BY id"
tEnv.sqlUpdate(sql)
env.execute("RetractKafka")
}
}
当然,也可以clone我的git代码【https://github.com/sunjincheng121/know_how_know_why/tree/master/QA/upsertKafka】直观体验一下。由于本系列文章只关注解决问题,不论述细节原理,有关原理性知识,我会在我的视频课程《Apache 知其然,知其所以然》中进行介绍。
Flink 的锅?...
看到上面的问题有些朋友可能会问,既然知道问题,知道有实际业务需求,为啥Flink不改进,不把这种情况支持掉呢?问的好,就这个问题而言,Flink是委屈的,Flink已经在努力支持这个场景了,预期Flink-1.12的版本大家会体验到完整的CDC(change data capture)支持。
众人拾柴
期待你典型问题的抛出... 我将知无不言...言无不尽... 我在又一村等你...
作者介绍
孙金城,51CTO社区编辑,Apache Flink PMC 成员,Apache Beam Committer,Apache IoTDB PMC 成员,ALC Beijing 成员,Apache ShenYu 导师,Apache 软件基金会成员。关注技术领域流计算和时序数据存储。