














一、前言
前几天在Python白银交流群【Ming】问了一道Pandas处理html的问题,如下图所示。
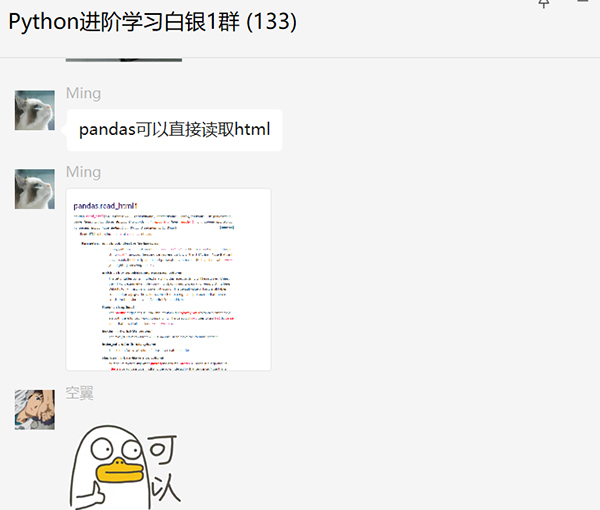
其实也不是问,算交流。

确实,Pandas可以直接读取html,而且在网页读取的时候更加方便。
二、实现过程
这里大家一起讨论,学习了Pandas直接读取html的方法。
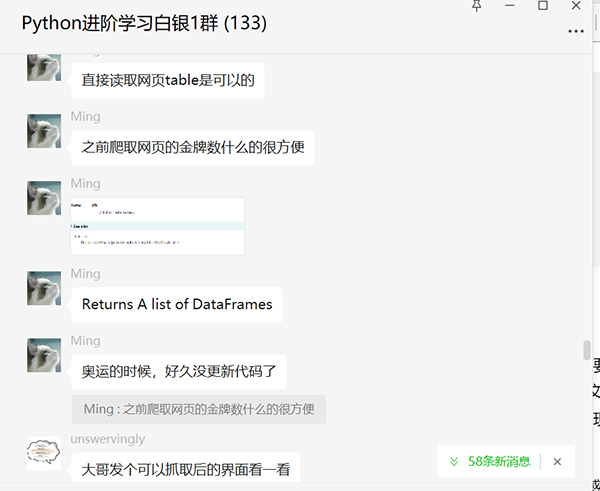
后来【null】给了一个示例代码,及时雨。
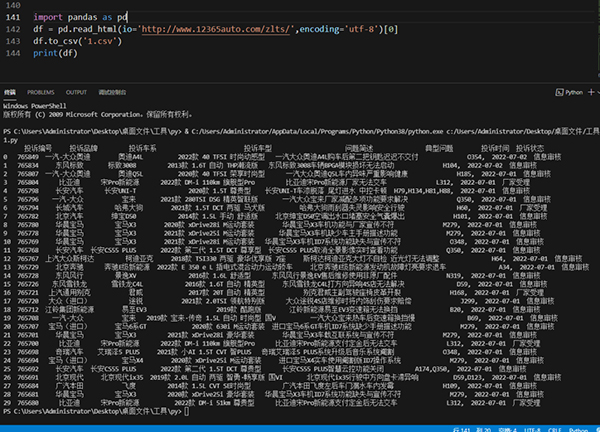
简单的三句代码就扒下来网页数据了,并且存表格,针对表格形式的网页,再也不用挨个tr、td标签去取了,直接Pandas梭哈。

后来发现哥几个竟然是湖北公安老乡,彼此聊得火热。老乡见老乡,一起学习更香!后来【null】多做了拓展,爬ajax加载的json格式,也可以用Pandas来实现,这里也给出了示例。
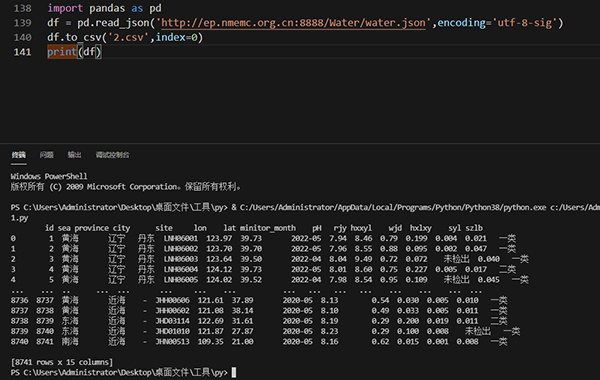
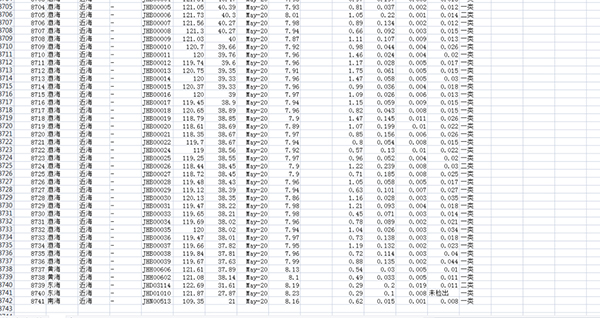
得到的结果如下图所示:
后来【月神】也给出了拓展,抓取csv格式也是可以的。
不得不承认,Pandas实在是太强大了!
三、总结
这篇文章主要盘点了一道Pandas处理网络爬虫的问题,文中针对该问题给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。

























