译者 | 陈峻
审校 | 孙淑娟
为了协助您为数据管道项目选择合适的数据集成方法,我们将简要地探讨ETL和ELT各自的优缺点,以及如何使用这两种技术。同时,我们也会讨论反向ETL为何成为那些需要快速数据加载、最小化维护、以及高度自动化工作流的更好选择。

ETL和ELT的一般概念
目前,企业面临的一种常见挑战是:需要以多种格式,从多个来源捕获数据,然后将其转移到一到多个数据目标。由于大多数数据转移项目都需要收集多个数据源,因此它们需要拥有一个定义良好的数据管道(即,信息从源头到终点的路径或工作流程)。如果目标与数据源的存储格式不同,那么我们就必须在加载到最终目标之前,对数据进行细化或清理。目前,业界有许多工具、服务和流程,可以在数据管道中,起到一定的应用数据转换与协调的工作。
ETL的流程
ETL是一个数据集成的过程。它使得数据管道项目能够从各种源头顺利地提取数据、转换数据、并将数据结果加载到目标数据库中。无论是ETL还是ELT,数据的转换与集成过程,都会涉及如下三个阶段(如图1所示):
- 提取——使用数据库查询或变更数据捕获(change data capture,CDC)流程,从源系统(如:SAS、在线、本地)提取数据。提取后,数据会被转移到暂存区域,以待进一步处理。
- 转换——数据被清理、处理、转换、充实后,会被转换为目标数据管道、数据仓库、数据库或数据湖使用的格式。
- 加载——将原始数据和转换后的数据加载到目标系统中。此过程会涉及到写入分隔文件、在数据库中创建模式、以及用累积或聚合的数据去覆盖现有的数据。
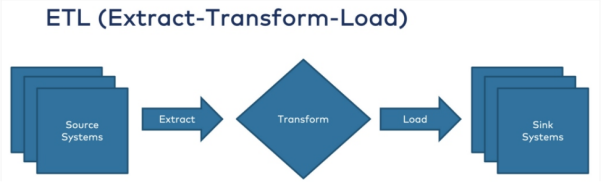
图1:ETL的流程(源自Kai Waehner的《何时使用反向ETL以及何时使用反模式》)
ETL和ELT流程会以不同的顺序执行上述步骤。数据管道团队必须决定是在将数据加载到目标数据存储库之前、还是之后进行数据转换。
ELT的流程
ELT是一种用于整合来自整个组织的数据,以防止出现数据孤岛的方法。数据会经历数据源中被提取,加载到数据仓库中,然后按需进行转换的过程。虽然是要按照应用之需进行转换,但是在ELT流程中,数据应当在存储之前进行转换(如图2所示)。
- 提取——与ETL相同。
- 加载——与ETL不同,数据直接(即,无需进行清理、扩充、转换)被加载和交付到目标系统(通常需要考虑目标模式和数据类型的各种迁移)。
- 转换——在加载数据后,目标平台会根据业务报告的目的进行转换。一些公司会利用dbt等工具,来转换其目标数据。因此,在ELT管道中,我们应按需对目标数据执行转换。
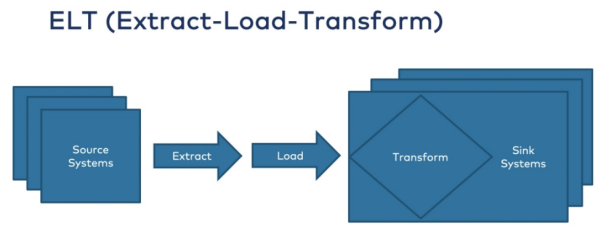
图2:ELT的流程(源自Kai Waehner的《何时使用反向ETL以及何时使用反模式》)
ELT会对集成过程中涉及的步骤进行重新排序,使得转换发生在最后,而不是中间。ELT的流程可以通过切换阶段顺序,在不考虑结构或格式的情况下,将数据加载到可接受原始数据的数据湖中,并且允许进行即时的数据提取和加载。
促成采用ELT的另一个因素是:基于云的数据仓库被广泛地采用与实施。云数据仓库解决方案提供了计算和存储之间的完全分离,以及存储无限数据的能力。如今,大多数数据仓库都是被托管的。这就意味着企业既不需要购买或管理任何硬件或存储设备,也不需要安装软件或考虑扩展。这些都将由云服务提供商来管理与负责。据此,企业可以在较短的时间内,配置出云托管的数据仓库。
ETL与ELT:属性、功能和用例
就ETL与ELT的用例而言,并不存在“一边倒”的现象。我们通过下表总结了两者在不同属性上的区别:
属性 | ETL | ELT |
最适合于…… | 结构化数据、历史遗留系统、以及关系型数据库;在加载到数据仓库之前转换数据 | 更快、更及时的数据加载,结构化和非结构化的数据,以及庞大且不断增长的数据,按需转换数据 |
支持非结构化数据? | 主要用于本地的关系型数据 | 随时可以支持非结构化的数据 |
支持数据湖? | 不支持数据湖 | 支持数据湖 |
查找 | 事实数据和维度都可用于暂存区 | 由于提取和加载发生在同一个操作中,因此所有数据皆可用 |
加载时间 | 数据最初被加载到暂存中,然后进入目标系统 | 数据一次性被加载到目标系统中 |
数据输出 | 通常被用于需要在上传到关系型数据仓库之前,实现结构化的本地数据 | 使用结构化、半结构化和非结构化数据,最适合在提供了大容量存储和计算能力的云环境中,处理海量数据,使数据湖能够按需快速存储和转换数据 |
数据加载的性能 | 由于它是一个多阶段的过程,因此数据加载的时间比其他替代品更长 | 由于节省了转换的等待时间,而且数据会被一次性加载到目标数据库中,因此数据加载的速度更快 |
转换的性能 | 数据转换可能会很慢 | 由于是在加载后按需完成的,因此数据转换完成得更快 |
聚合 | 复杂性会随着数据量和种类的增加而增多 | 目标平台的强大功能可以快速地处理大量数据 |
数据部署 | 基于本地或云端 | 通常基于云端 |
分析的灵活性 | 用例和报告模型都已被明确定义 | 随着模式的发展,随时添加数据,分析师可以构建目标仓库的新视图 |
合规 | 更符合GDPR、HIPAA和CCPA标准;用户可以避免将敏感数据加载到目标系统 | 会暴露个人数据,无法不遵守GDPR、HIPAA和CCPA标准 |
实施 | 提供各种工具和支持技术,更易于实施 | 需要有适当的技能来实施和维护的团队 |
反向ETL的一般概念
反向ETL是一种提取已清理的和处理过的数据架构。它会将数据从数据仓库(或数据湖/集市)复制到一个或多个操作系统。数据可以被重新引入诸如Salesforce等其他应用程序,可用于业务运营和预测。通过操作已提取的数据源,各类用户可以使用常用的工具来访问数据,并获取相关的洞见。作为现代化数据技术栈的组件,反向ETL允许企业开展那些比单独使用商业智能(BI)工具,更为复杂的分析。
作为一种战略性全新的集成流程,反向ETL可以减少那些快速发展型企业在数据分析上花费的时间。该流程更专注于将数据与业务用户的操作工具相同步,以激活数据仓库中的数据。用户必须事先定义好数据,并将其映射到最终目的地的适当列/字段上。
同时,由于企业的数据存储(如,数据参考或关系数据库)已成为一种并非所有人都可以完全访问到的存储库,因此,我们需要通过反向ETL,来为不同的业务角色提供基本的数据(如图3所示)。
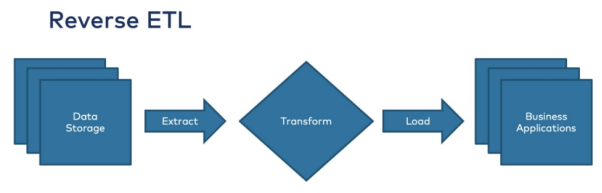
图3:逆向ETL流程(源自Kai Waehner的《何时使用反向ETL以及何时使用反模式》)
反向ETL用例
为了利用数据仓库中已经清理和准备好的信息,而不是将数据仓库仅仅视为数据管道中的最终组件,反向ETL用户可以通过使用连接器,来读取数据仓库(如:SAP或SASS)。例如,现代化数据团队可以借助现成的反向ETL方案,从数据仓库中提取数据,为电子邮件营销、客户支持、销售或财务模型提供支持。同时,他们也能够为业务团队提供更深入、更高效、以及更有价值的自助服务。
总地说来,反向ETL可以协助企业实现:
- 业务响应——快速跟踪业务应用和数据的变化,并做出反应。
- 业务分析——为业务团队的分析工作流程提供洞见,以便他们做出更多以数据为依据的决策。
- 数据基础设施——随着源系统数量的增加,反向ETL现在已成为能够快速、有效地操作数据仓库、以及数据湖中数据的重要工具。
- 为云应用程序复制数据——增强各种报告功能,并能及时查找信息。
购买与构建反向ETL
当数据团队采用第三方反向ETL工具时,他们可以快速实施运营分析,但到底是该购买,还是自行构建反向ETL?下面我们以设计和构建反向ETL的流程和平台为例,给出企业需要在做出决定之前,慎重考量的三个因素:
- 构建数据连接器——将数据从仓库传输到下游操作系统,往往需要集成API连接器。这是一个的复杂工作。如果您选择设计和构建反向ETL、及其相关流程,就需要将ETL管道的构建流程,分配给开发团队。
- 为长期维护做准备——一旦您的开发团队推出了数据连接器,那么就需要针对API规范的经常性变化,保持连接器的更新。
- 可扩展性和可靠性设计——数据工程师需要确保反向ETL管道能够被快速开发,以便跟随企业的发展,有效地管理数据的激增。而且,反向ETL管道必须是可靠的,不会出现性能或数据传输上的问题。
小结
在创建数据管道的过程中,最繁重、且最耗时的步骤便是:从各种来源提取数据,然后测试整个过程。其中,同步每个数据源的收集过程,往往需要各个层面的大量专业知识。如果您和您的团队对此感兴趣的话,请参考如下链接:
- Gartner Research(2021),《Gartner数据集成工具的魔力象限》
- Gartner Research(2020),《数据集成工具的关键能力》
- Kai Waehner,《何时使用反向ETL以及何时使用反模式》
- Stephen Roddewig,《ETL与ELT:有什么区别?哪个更好?》
译者介绍
陈峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。
原文标题:ETL, ELT, and Reverse ETL,作者:Wayne Yaddow