












译者 | 布加迪
审校 | 孙淑娟
引言

时间序列数据是跨多个时间点测量相同变量的一系列数据,在现代数据环境中无处不在。与表格数据一样,我们常常希望生成合成时间序列数据,以保护敏感信息,或在真实数据稀少时创建更多的训练数据。合成时间序列数据的一些应用包括:传感器读数、带时间戳的日志消息、金融市场价格和医疗记录。时间这个额外的维度(跨时间点的趋势和相关性与变量之间的相关性同样重要)给合成数据带来了另外的挑战。
我们Gretel之前发布了关于合成时间序列数据的博文,但一直在寻找可以改进合成数据生成的新模型。我们非常喜欢DoppelGANger模型和Lin等人合著的相关论文:《使用GAN共享网络时间序列数据:挑战、前景和未决问题》,正在将该模型整合到我们的API和控制台中。作为这项工作的一部分,我们用PyTorch重新实现了DoppelGANger模型,很高兴将其作为我们开源gretel-synthetics库的一部分来发布。
本文概述了DoppelGANger模型,提供了PyTorch实现的示例用法,并针对合成每日维基百科网络流量的任务演示了出色的合成数据质量:与TensorFlow1实现相比,运行时速度提升了约40倍。
DoppIGANger模型
DoppelGANger基于生成式对抗网络(GAN),经过一番改动,更好地适应时间序列生成任务。作为GAN,该模型使用对抗训练方案,通过比较合成数据和真实数据来同时优化鉴别器和生成器网络。一旦经过训练,可以将输入噪音传递给生成器网络,以此创建任意数量的合成时间序列数据。
Lin等人在论文中介绍了现有的合成时间序列方法及自己的观察结果,以确定局限性,并提出几处具体的改进——DoppelGANger由此而来,包括一般的GAN改进和专门针对时间序列的技巧。下面列出了其中几处关键修改:
- 生成器含有用于生成序列数据的LSTM,但有批量设置,其中每个LSTM单元输出多个时间点,以改善时间相关性。
- 训练和生成时都支持可变长度序列(计划中,但尚未在我们的PyTorch版本中实现)。比如说,一个模型可以使用和创建10秒或15秒的传感器测量值。
- 支持不随时间变化的固定变量(属性)。该信息常常与时间序列数据一同出现,比如金融价格历史数据中与每只股票相关的行业或部门。
- 支持按示例缩放连续变量以处理动态范围大的数据。比如说,流行的维基百科页面与罕见的维基百科页面的页面浏览量相差几个数量级。
- 使用带梯度惩罚的Wasserstein损失,减少模式崩塌并改善训练。
捎带提一下术语和数据设置。DoppelGANger需要有多个时间序列示例的训练数据。每个示例由0个或多个属性值、不随时间变化的固定变量以及在每个时间点观察的1个或多个特征组成。组合成一个训练数据集时,这些示例看起来像2d属性数组(示例x固定变量)和3d特征数组(示例x时间x时间变量)。视任务和可用数据而定,该设置可能需要将几个较长的时间序列拆分成较短的块,这些块可用作训练的示例。
总地来说,对基本GAN所作的这些修改提供了一个富有表现力的时间序列模型,可以生成高保真合成数据。DoppelGANger能够学习和生成具有不同尺度的时间相关性数据(比如每周和每年趋势),给我们留下了特别深刻的印象。想了解模型的完整详细信息,请阅读论文。
示例用法
我们的PyTorch实现支持两种输入样式(numpy数组或pandas DataFrame)以及模型的许多配置选项。想了解完整的参考文档,请参阅https://synthetics.docs.gretel.ai/。
要使用我们的模型,最简单的方法是使用pandas DataFrame中的训练数据。针对该设置,数据必须采用“宽”格式,其中每一行是示例,一些列是属性,剩余的列是时间序列值。下列代码片段演示了训练和生成来自DataFrame的数据。
# Create some random training data
df = pd.DataFrame(np.random.random(size=(1000,30)))
df.columns = pd.date_range("2022-01-01", periods=30)
# Include an attribute column
df["attribute"] = np.random.randint(0, 3, size=1000)
# Train the model
model = DGAN(DGANConfig(
max_sequence_len=30,
sample_len=3,
batch_size=1000,
epochs=10, # For real data sets, 100-1000 epochs is typical
))
model.train_dataframe(
df,
df_attribute_columns=["attribute"],
attribute_types=[OutputType.DISCRETE],
)
# Generate synthetic data
synthetic_df = model.generate_dataframe(100)
如果您的数据尚未采用这种“宽”格式,可以使用pandas pivot方法将其转换成预期的结构。DataFrame输入目前有些受到限制,但我们计划在未来支持接受时间序列数据的其他方式。为了获得最大的控制度和灵活性,您还可以直接传递numpy数组进行训练(并在生成数据时以相似的方式接收属性和特征数组),如下所示。
# Create some random training data
attributes = np.random.randint(0, 3, size=(1000,3))
features = np.random.random(size=(1000,20,2))
# Train the model
model = DGAN(DGANConfig(
max_sequence_len=20,
sample_len=4,
batch_size=1000,
epochs=10, # For real data sets, 100-1000 epochs is typical
))
model.train_numpy(
attributes, features,
attribute_types = [OutputType.DISCRETE] * 3,
feature_types = [OutputType.CONTINUOUS] * 2
)
# Generate synthetic data
synthetic_attributes, synthetic_features = model.generate_numpy(1000)
这些代码片段的可运行版本可在sample_usage.ipynb处获得。
结果
作为从TensorFlow 1改为PyTorch的新实现(优化器、参数初始化等底层组件方面存在潜在差异),我们希望确认我们的PyTorch代码按预期运行。为此,我们复制了原始论文中的部分结果。由于我们目前的实现仅支持固定长度序列,因此专注于维基百科网络流量(WWT)的数据集。
Lin等人使用的WWT数据集最初来自Kaggle,含有测量各种维基百科页面的每日流量数据。每个页面有三个不同的属性(域、访问类型和代理)。图1显示了来自WWT数据集的几个示例时间序列。
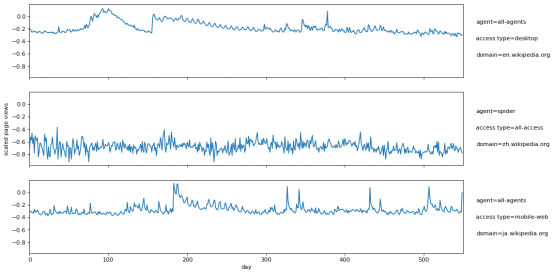
图1:三个维基百科页面的缩放的每日页面浏览量,右侧列出了页面属性
请注意,页面浏览量根据整个数据集上的最小/最大页面浏览量被对数轴缩放为[-1,1]。我们在实验中使用的5万页的训练数据(已被缩放)在S3上以csv格式提供。
我们展示的三张图显示了合成数据保真度的不同方面。在每张图中,我们将真实数据与三个合成版本进行比较:1)具有更大批量和更小学习率的快速PyTorch实现,2)具有原始参数的PyTorch实现,3)TensorFlow 1实现。在图2中,我们查看了属性分布,其中合成数据与真实分布非常匹配。
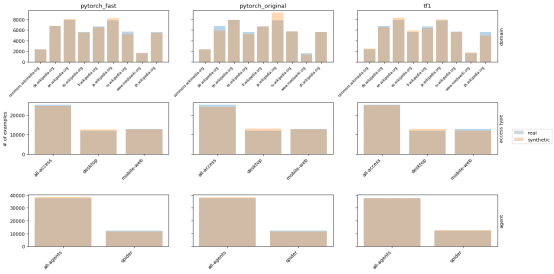
图2:真实和合成WWT数据的属性分布
WWT数据面临的挑战之一是,不同的时间序列有全然不同的页面浏览量范围。一些维基百科页面持续获得很大流量,另一些不那么受欢迎,但偶尔因某个相关的新闻事件(比如与页面相关的突发新闻故事)而出现流量高峰。Lin等人发现,DoppelGANger在生成不同尺度的时间序列方面非常有效(见原始论文的图6)。在图3中,我们提供了显示时间序列中点分布的类似图。就每个示例而言,中点处于550天内获得的最小和最大页面浏览量的中间值。我们的PyTorch实现对中点显示了类似的保真度。
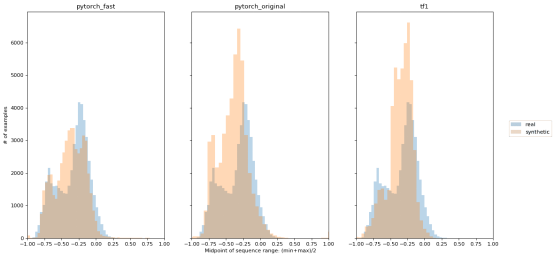
图3:真实和合成WWT数据的时间序列中点分布
最后,大多数维基百科页面的流量呈现出每周和每年的模式。为了评估这些模式,我们使用自相关,即不同时间滞后(1天、2天等)的页面浏览量的Pearson相关性。三个合成版本的自相关图如图4所示(类似原始论文中的图 1)。
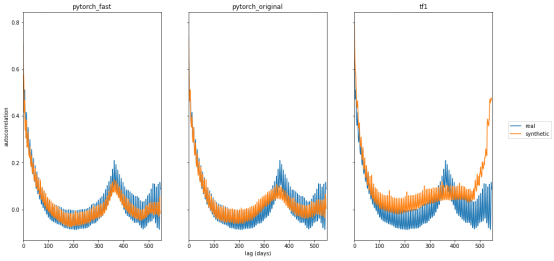
图4:真实和合成 WWT 数据的自相关
两个PyTorch版本都生成原始论文中观察到的每周和每年趋势。TensorFlow 1结果与 Lin等人的图1不匹配,正如来自我们实验的上述图所示。我们观察到使用原始参数进行的训练有些不一致,模型偶尔没有观察到每年(甚至每周)模式。我们的快速版本中使用的较低学习率(1e-4)和较大的批量大小(1000)使再训练更加一致。
生成本节中的图像和训练三个模型的分析代码在Github上作为笔记本予以共享。
运行时
最后更复杂模型的一个关键方面是运行时。需要数周时间来训练的出色模型实际上比需要一小时来训练的模型更受限制。在这里,相比之下PyTorch实现表现极好(不过作者在论文中指出,他们没有对TensorFlow 1代码进行性能优化)。所有模型均使用GPU进行训练,并在搭载英伟达Tesla T4的GCP n1-standard-8实例(8个虚拟 CPU和30 GB RAM)上运行。从13小时缩短到0.3小时,这对于这个出色的模型在实践中发挥更大的用处至关重要!
版本 | 训练时间 |
TensorFlow 1 | 12.9小时 |
PyTorch,batch_size=100(原始参数) | 1.6 小时 |
PyTorch,batch_size-1000 | 0.3小时 |
原文标题:Generate Synthetic Time-series Data with Open-source Tools,作者:Kendrick Boyd



























