现代计算机诞生,如何编译更快、更小的代码问题随之出现。
编译优化是成本收益比最高的优化手段,更好的代码优化可以显著降低大型数据中心应用程序的操作成本。编译代码的大小对于部署在安全引导分区上的移动和嵌入式系统或软件来说是至关重要的,因为编译后的二进制文件必须符合严格的代码大小预算。随着这一领域的进步,越来越复杂的启发式方法严重挤压有限的系统空间,阻碍了维护和进一步的改进。
最近的研究表明,机器学习可以通过用机器学习策略取代复杂的启发式方法,在编译器优化中释放更多的机会。然而,在通用的、行业级编译器中采用机器学习策略仍然是一个挑战。
为了解决这个问题,谷歌两位高级工程师钱云迪、Mircea Trofin 提出了“MLGO,一个机器学习指导的编译器优化框架”,这是第一个工业级的通用框架,用于将机器学习技术系统地集成到 LLVM(一个开源的工业编译器基础设施,在构建关键任务、高性能软件时无处不在)中。

论文地址:https://arxiv.org/pdf/2101.04808.pdf
MLGO 使用强化学习训练神经网络来做出决策,以取代 LLVM 中的启发式算法。根据作者描述,LLVM 上有两处 MLGO 优化:
1)通过内联减少代码量;
2)通过寄存器分配提高代码性能。
这两种优化都可以在 LLVM 资源库中获得,并已在生产中部署。
1 MLGO是如何工作的?
内联(Inlining)有助于通过做出能够删除冗余代码的决策来减少代码大小。在下面的示例中,调用者函数 foo()调用被调用者函数 bar(),而 bar()本身又调用了 baz()。内联这两个调用站点将返回一个简单的 foo()函数,该函数将减小代码大小。

图注:内联通过删除冗余代码来减少代码大小
在实际代码中,有成千上万的函数相互调用,因此构成了一个调用图(Call graph)。在内联阶段,编译器遍历(traverses)所有调用者-被调用者对的调用图,并决定是否内联一个调用者-被调用者对。这是一个连续的决策过程,因为以前的内联决策会改变调用图,影响后面的决策和最终的结果。在上面的例子中,调用图foo() → bar() → baz()需要在两条边上做出“yes”的决定,以使代码大小减少。
在MLGO之前,内联/非内联的决定是由启发式方法做出的,随着时间的推移,这种方法越来越难以改进。MLGO用一个机器学习模型代替了启发式方法。在调用图的遍历过程中,编译器通过输入图中的相关特征(即输入)来寻求神经网络对是否内联特定的调用者-被调用者对的建议,并按顺序执行决策,直到遍历整个调用图为止。

图注:内联过程中MLGO的图示,“ # bbs”、“ # users”和“ callsite height”是调用者-被调用者对特性的实例
MLGO 使用策略梯度和进化策略算法对决策网络进行 RL 训练。虽然没有关于最佳决策的基本事实,但在线 RL 使用经过培训的策略在培训和运行汇编之间进行迭代,以收集数据并改进策略。特别是,考虑到当前训练中的模型,编译器在内联阶段咨询模型,以做出内联/不内联的决策。编译完成后,它产生一个顺序决策过程的日志(状态、行动、奖励)。然后,该日志被传递给训练器以更新模型。这个过程不断重复,直到得到一个满意的模型为止。

图注:训练期间的编译器行为——编译器将源代码foo.cpp编译成对象文件foo.o,并进行了一系列的优化,其中一个是内联通道。
训练后的策略被嵌入到编译器中,在编译过程中提供内联/非内联的决策。与训练场景不同的是,该策略不生成日志。TensorFlow 模型被嵌入 XLA AOT ,它将模型转换为可执行代码。这避免了TensorFlow运行时的依赖性和开销,最大限度地减少了在编译时由ML模型推理引入的额外时间和内存成本。

图注:生产环境中的编译器行为
我们在一个包含30k 模块的大型内部软件包上培训了大小内联策略。训练后的策略在编译其他软件时可以推广,并减少了3% ~ 7% 的时间和内存开销。除了跨软件的通用性之外,跨时间的通用性也很重要,软件和编译器都在积极开发之中,因此训练有素的策略需要在合理的时间内保持良好的性能。我们在三个月后评估了该模型在同一组软件上的性能,发现只有轻微的退化。

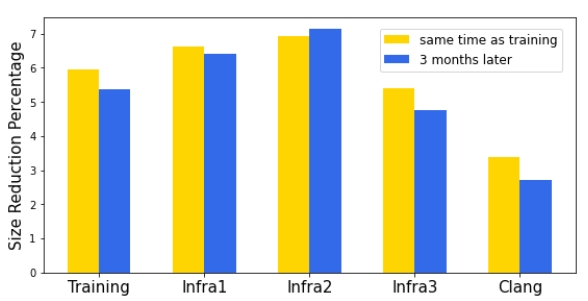
图注:内联大小策略大小减少百分比,x 轴表示不同的软件,y 轴表示减小的百分比。“Training”是训练模型的软件,“InfraX”是不同的内部软件包。
MLGO 的内联换大小训练已经在 Fuchsia 上部署,Fuchsia 是一个通用的开源操作系统,旨在为不同的硬件和软件生态系统提供动力,其中二进制大小是关键。在这里,MLGO 显示 C++ 翻译单元的大小减少了6.3%。
2 寄存器分配
作为一个通用框架,我们使用 MLGO 来改进寄存器分配(Register allocation)通道,从而提高 LLVM 中的代码性能。寄存器分配解决了将物理寄存器分配给活动范围(即变量)的问题。
随着代码的执行,不同的活范围在不同的时间完成,释放出的寄存器供后续处理阶段使用。在下面的例子中,每个 "加法 "和 "乘法 "指令要求所有操作数和结果都在物理寄存器中。实时范围x被分配到绿色寄存器,并在蓝色或黄色寄存器的实时范围之前完成。x 完成后,绿色寄存器变得可用,并被分配给活范围t。
在代码执行过程中,不同的活范围在不同的时间完成,释放出的寄存器供后续处理阶段使用。在下面的例子中,每个“加法”和“乘法”指令要求所有操作数和结果都在物理寄存器中。活动范围 x 被分配到绿色寄存器,并在蓝色或黄色寄存器的实时范围之前完成。x 完成后,绿色寄存器变得可用,并被分配给活范围 t 。

图注:寄存器分配示例
当分配活动范围 q 时,没有可用的寄存器,因此寄存器分配通道必须决定哪个活动范围可以从其寄存器中“驱逐”,以便为 q 腾出空间。这被称为“现场驱逐”问题,是我们训练模型来取代原始启发式算法的决策。在这个例子中,它将 z 从黄色寄存器中驱逐出去,并将其赋给 q 和 z 的前半部分。
我们现在考虑实际范围 z 的未分配的下半部分。我们又有一个冲突,这次活动范围 t 被驱逐和分割,t 的前半部分和 z 的最后一部分最终使用绿色寄存器。Z 的中间部分对应于指令 q = t * y,其中没有使用 z,因此它没有被分配给任何寄存器,它的值存储在来自黄色寄存器的堆栈中,之后被重新加载到绿色寄存器中。同样的情况也发生在 t 上。这给代码增加了额外的加载/存储指令,降低了性能。寄存器分配算法的目标是尽可能地减少这种低效率。这被用作指导 RL 策略训练的奖励。
与内联大小策略类似,寄存器分配(regalloc-for-Performance)策略在 Google 内部一个大型软件包上进行了培训,并且可以在不同的软件上通用,在一组内部大型数据中心应用程序上每秒查询次数(QPS)提高了0.3% ~ 1.5% 。QPS 的改进在部署后持续了几个月,显示该模型的可推广性。
3 总结
MLGO使用强化学习训练神经网络来作决策,是一种机器学习策略取代复杂的启发式方法。作为一个通用的工业级框架它将更深入、更广泛应用于更多环境,不仅仅在内联和寄存器分配。
MLGO可以发展为:1)更深入,例如增加更多的功能,并应用更好的 RL 算法;2)更广泛,可应用于内联和重新分配之外的更多优化启发式方法。
作者对 MLGO 能够为编译器优化领域带来的可能性充满热情,并期待着它的进一步采用和研究界未来的贡献。