作者 | 董哲
需求背景
数据探查上线之前,数据验证都是通过写 SQL 方式进行查询的,从编写 SQL,到解析运行出结果,不仅时间长,还会反复消耗计算资源,探查上线后,只需要一次探查,就可以得到整张表的探查报告,但后续我们还发现了一些问题,主要有三点:
- 无法看到探查的数据明细以及关联的行详情,无法对数据进行预处理操作。
- 探查还是需要资源调度,等待时长平均分钟级。
- 与质量监控没有打通,探查数据的后续走向不明确。
针对这些问题,我们进一步开发了动态探查需求,解决的问题如下:
- 基于大数据预览的探查,支持对数据进行函数级别的预处理。
- 探查结果秒级更新,实时响应。
- 与数据监控打通,探索 SQL 的生成模式。

本文主要介绍动态探查的应用场景和相关的技术实现。
应用场景
探查主要应用在元数据管理,数据研发,数仓的开发以及数据治理,可为对数据质量有需求的场景提供数据质量的发现和识别能力。目标用户除了研发同学,也包含不是以 SQL 研发为主的群体,比如算法建模和数据挖掘等领域。
探查可以有效的打通三个闭环:
- 元数据管理 -> 探查 -> 数据预览探查(库表的质量报告)
- 数据监控 <-> 数据探查
- 动态探查 -> SQL -> 数据开发 -> 调试 -> 探查报告(质量分析)

名词解释
- 全量探查:基于库表的全量探查,后端引擎执行,展示探查后列的统计分布结果。
- 动态探查:基于抽样的部分数据探查,展示字段明细,可以使用操作对数据进行预处理,并实时动态的展示统计分布结果。数据获取后的过程都由前端执行。
两者的对比示意图


技术实现
除了数据的抽样部分在后端做,其他的都是前端实现的。包括大数据展示,探查计算,卡片联动,操作栈交互,以及未来要做的函数编辑器以及 SQL 生成。
技术架构

1)抽样能力:对数据进行基于质量分布特征的抽取。
目前做的是随机抽样,后续尝试基于特征来抽样。
2)数据展现:大容量的数据载体,支持对数据处理的实时展现。
前端目前是基于虚拟滚动 Table 做的,后续打算迁移到 canvas table 上。
3)前端探查:实时探查,可视化展现数据分布,突出质量指标。
4)数据处理能力:函数处理能力(GroupBy..)
5)操作栈:需要对数据操作进行管理和回溯
基于 immutable 和操作流实现操作栈。
6)编辑器:提供完整函数的功能,需要:词法解析,智能提醒,语法高亮。
基于编辑器实现函数的功能,antlr4 实现词法解析,配合 monaco editor 实现一些智能提醒和语法高亮。
7)生成 SQL:将可视化的交互式操作转换成可执行的 SQL。
目前 sql generator 有以下几种方式:
- 基于链式调用生成
- 基于标签模板生成
- 基于 AST(抽象语法树)去做
关键技术及实现
大数据渲染
由于动态探查场景下前端需要支持最大 5000 条数据的展示和交互,所以在渲染这块存在比较大的压力,主要集中在探查卡片和数据预览两个部分。
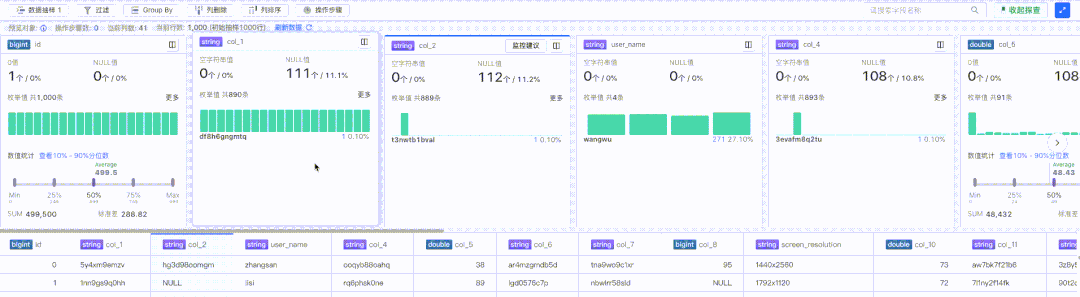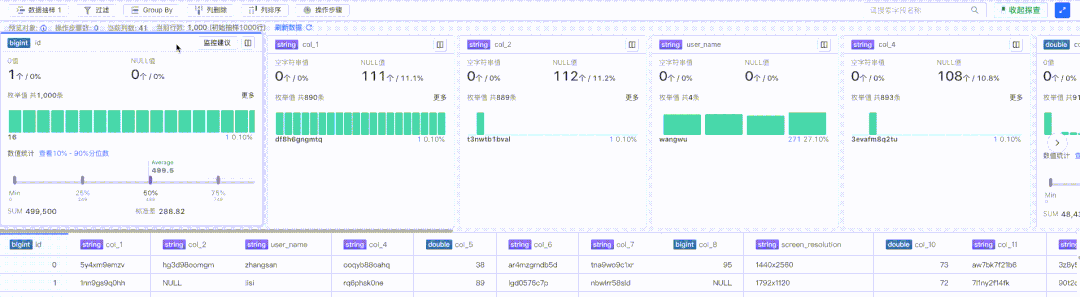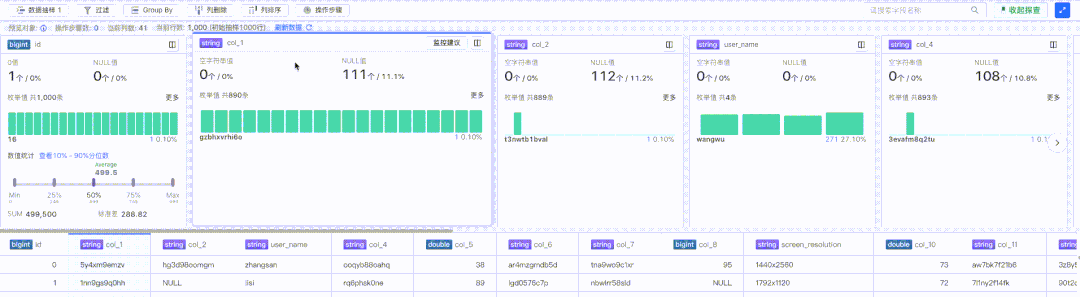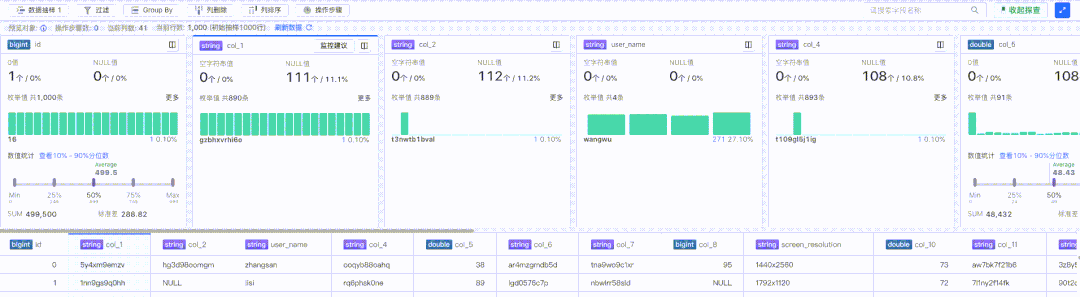
探查卡片包含了特定列的部分关键信息汇总,比如 0 值、Null 值、枚举值等,如下图红框部分:

探查卡片部分由于存在较多定制化内容,所以采用了虚拟列表方案进行渲染,支持收起状态和展开状态:

数据预览部分展示的是探查的全部数据集合,可以快速查看原始数据的详细内容,由于内容同质化比较高,所以数据预览采用的是基于团队内部维护的 canvas 版本 Table 方案进行渲染,如下图红框部分:


卡片联动
由于卡片和数据预览列的宽度差异较大,并且上下两部分滑动是独立的,造成在选择查看某个具体列的时候,上下对齐位置会比较麻烦,为了解决这个问题,这块增加了自动定位功能,演示效果如下:

这部分需要解决的问题有两个:卡片中间点坐标计算和自动定位逻辑。

中间点坐标计算逻辑如下:
// 计算卡片中点坐标 index是卡片序号,adsorbSider表示是否吸边
getCardCenter(index: number, adsorbSider?: boolean) {
...
// 获取卡片信息
const cardBox: IBaseBox = this.cardList[index];
// 获取列信息
const colBox: IBaseBox = this.colList[index];
const clientWidth = getClientWidth();
if(adsorbSider) {
// 吸边处理
if(cardBox.offset < this.cardScroll) {
return cardBox.offset;
}
if(cardBox.offset + cardBox.width - this.cardScroll > clientWidth) {
return cardBox.offset + cardBox.width - clientWidth;
}
return this.cardScroll;
}
return getTargetPosition(colBox, this.tableScroll, cardBox);
}
// 获取滚动目标位置
// originBox: 滚动起始对象
// originScroll: 滚动起始左侧scroll
// targetBox: 滚动结束对象
const getTargetPosition = (originBox: IBaseBox, originScroll: number, targetBox: IBaseBox) => {
const clientWidth = getClientWidth();
if(!originBox || !targetBox) return 0;
let offsetLeftSider = Math.max(originBox?.offset - originScroll, 0);
if(offsetLeftSider + targetBox.width >= clientWidth) {
if(targetBox.offset + targetBox.width > clientWidth) {
// 此处容易出现吸边
return targetBox.offset + targetBox.width - clientWidth;
} else {
return 0;
}
}
const scroll = targetBox?.offset - offsetLeftSider + (targetBox.width - originBox.width) / 2;
return Math.max(
Math.min(targetBox.offset, scroll),
0
);
}
获取到中点坐标后,自动定位需要符合如下规则:
- 选中卡片后,表格要自动滚动定位到下方居中对齐,无法满足对齐标准的,尽量靠近选中卡片位置。
- 选中表格列后,卡片要自动滚动定位到上方居中对齐,无法满足对齐标准的,尽量靠近选中表格位置。
- 搜索选中列后,卡片和表格要自动满足上面两个规则,并滚动到可视区域内。
规则中有几种边界情况,参考下图:

居中对齐是对于卡片和列宽在 scroll 距离允许情况下的理想对齐方式,贴边对齐是针对卡片在起始和结束位置 scroll 不足以满足居中对齐要求时候的对齐方式,除此之外还有一种是卡片的宽度远大于列宽,并且不是起始或者结束位置的时候所采取的对齐方式,如下如卡片 B 因为无法滚动,卡片 A 的宽度又占据了底部第二列的一部分,所以此时卡片 B 只能高亮和底部的列进行对齐。

操作栈
动态探查支持了对于探查结果的基础分析能力,比如列删除、过滤、排序等,如下图红框部分:

用户对于探查结果的每一次操作都会被记作一次操作,多次操作串联起来形成操作栈,可以自由的修改或者删减操作栈里的操作,并实时查看最新结果,以过滤操作演示效果如下:

操作栈部分需要处理的问题主要有以下几点:
1)如何管理多种操作进行串行计算
这里把所有操作都抽象成了Input + Logic = Ouput的结构,Input 是输入参数,此处可以是指某一列的数据、上一步操作的结果或者其他计算值,Logic 是操作的具体逻辑,负责根据 Input 转换生成 Output,Output 可以作为最终结果进行渲染,也可以再次进入下一环节参与计算,拿列删除操作举个栗子,下面是大体代码实现:
class ColDelOpt {
run = (params: IOptEngineMetaInfo) => {
// 操作Input部分
const {
columns = [],
dataSourceMap = {}
} = params;
const {
fields = []
} = this.params;
// 操作Logic部分
const nextColumns = columns.filter((item) => !fields.includes(item.name));
// 操作的Output
return {
columns: nextColumns,
dataSourceMap
}
}
}可以看到 ColDelOpt 内部有一个 run 方法,该方法支持传入一个包含了列信息 columns 和数据集 dataSourceMap 的 params 对象,此处 params 即被抽象的外部输入参数 Input,run 方法内部的逻辑部分即被抽象的 Logic 部分,最后方法返回值包含了最新的 columns 和 dataSourceMap,即为 Output 部分。基于这种结构,用户所有的操作都可以被初始化成不同的 Opt 实例,由操作引擎统一调用实例的 run 方法,并传入所需的参数,最终得到计算结果。
2)某个操作被修改后如何进行二次计算
操作栈的计算是由计算引擎来完成的,引擎负责根据外部事件,来自动执行现有操作的数据处理工作,引擎执行流程和大体代码如下:

// 操作引擎
class OptEngine {
// 操作列表
private optList: IOptEngineItem[] = [];
// 原始数据
private metaData: IOptEngineMetaInfo = {
columns: [],
dataSourceMap: {},
};
// 执行算子
optRun = () => {
let {
columns = [],
dataSourceMap = {}
} = this.metaData;
if(!this.optList.length) return {
columns,
dataSourceMap
};
for(let index = 0; index < this.optList.length; index++) {
// 读取操作算子
const optItem = this.optList[index];
let startTime = performance.now();
try {
// 执行算子计算
const result = optItem.run({
columns,
dataSourceMap
});
// 更新算子结果
columns = result.columns || [];
dataSourceMap = result.dataSourceMap || {};
} catch(e) {
// 报错后直接直接返回
return {
columns,
dataSourceMap,
// 装填报错信息
errorInfo: {
key: optItem.key || '',
message: e.message
}
}
}
}
return {
columns,
dataSourceMap,
}
}
autoRun = (
metaInfo: IOptEngineMetaInfo,
optList: IOptItem[],
callback: (params: IAutoRunResult) => void
) => {
// 装填数据
this.setupMetaData(metaInfo);
// 装填操作栈
this.setupOptList(optList.map((item) => {
// 行过滤
if(item.type === OPT_TYPE.FILTER) {
return new FilterOpt({
key: item.key,
params: item.params
})
}
// 其余类型操作
...
// 默认原值返回
return new IdentityOpt({
key: item.key,
})
}));
// 执行操作计算
const result = this.optRun();
// 返回数据
return {
// 计算列
columns: result.columns,
// 执行结果
dataSource: Object.entries(result.dataSourceMap).map(([key, value]) => ({
field: key,
value
})),
// 操作栈执行异常信息
errorInfo: result.errorInfo
};
}
}
应用实践
以一个小例子来演示下动态探查的使用。前端开发过程中,有一个真实的场景,我们为了排查一个竖屏显示器的 bug(1080*1920),想找到关联的用户,看其分布情况,就可以很方便的用动态探查去寻找。

后续计划
关注动态探查的操作丰富性以及之后的数据走向,比如离线数据导出,和生成 SQL 等,技术方向上主要放在以下几个方面:
更多的探查类型和图表支持
动态探查目前支持空值,枚举值,零值,数据统计等基础的探查功能,未来会计划支持包括 map,json,time,sql 语句等类型的识别和探查。同时提供更丰富的图表支持。
操作栈的编辑器体验
动态探查目前还是以类 Excel 的操作为主,未来主要提供编辑器级别的操作体验,可以提供 HSQL 支持的大部分函数,包括支持多表 join 功能。
操作流程的 SQL 生成
动态探查目前的 SQL 能力还未建设完成,会在未来结合编辑器级别的操作,并支持多表,配合词法解析功能,提供更精准的生成 SQL 能力。