摘要:本文整理自快手实时计算团队技术专家刘建刚在 Flink Forward Asia 2021 生产实践专场的演讲。主要内容包括:
- 快手 Flink 的历史及现状
- Flink 容错能力提升
- Flink 引擎控制与实践
- 快手批处理实践
- 未来规划
01快手 Flink 的历史与现状

快手从 2018 年开始对 Flink 进行深度整合,经过 4 年发展,实时计算平台逐渐完善并赋能周边各种组件。
- 2018 年我们针对 Flink 1.4 进行了平台化建设并大幅提升运维管理能力,达到了生产可用。
- 2019 年我们开始基于 1.6 版本进行迭代开发,很多业务都开始实时化,比如优化 interval join 为商业化等平台带来显著收益、开发实时多维分析加速超大多维报表的实时化,这一年我们的 Flink SQL 平台也投入使用。
- 到了 2020 年,我们升级到 1.10,对 sql 的功能进行了非常多的完善,同时进一步优化 Flink 的核心引擎,保障了 Flink 的易用性、稳定性、可维护性。
- 2021 年我们开始发力离线计算,支持湖仓一体的建设,进一步完善 Flink 生态。

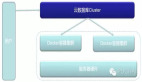
上图是快手基于 Flink 的技术栈。
- 最核心、最底层是 Flink 的计算引擎,包括流计算和批处理,我们针对稳定性和性能做了大量工作。
- 外面一层是跟 Flink 打交道的周边组件,既有 Kafka、rocketMQ 等中间件,也有 ClickHouse、Hive 等数据分析工具,还有 Hudi 等数据湖的使用。用户可以基于 Flink 和这些组件构建各种应用,涵盖了实时、近实时、批处理的各种场景。
- 最外层是具体的使用场景,常见的有电商、商业化等视频相关的业务方,应用场景包含机器学习、多维分析等。另外还有很多技术部门基于 Flink 来实现数据的导入、转换,比如 CDC、湖仓一体等。

应用规模上,我们有 50 万 CPU 核,主要通过 Yarn 和 K8s 的方式进行资源托管,上面运行着 2000+ 作业,峰值处理达到了 6亿/秒,日处理条数达到了 31.7 万亿,节假日或活动的时候流量甚至会翻倍。
02容错能力提升

容错能力主要包含以下部分:
- 首先是单点恢复,支持任意多个 task 失败时的原地重启,long-running 作业基本可以做到永不断流;
- 其次,是集群故障的应对,包含冷备、热备以及 Kafka 双集群的集成;最后是黑名单的使用。

Flink 为了做到 exactly-once,任何节点出现故障都需要重启整个作业,全局重启会带来长时间的停顿,最高可达十几分钟。有些场景不追求 exactly-once,比如推荐等实时场景,但它们对服务可用性的要求很高,无法容忍作业的断流,还有模型训练等初始化很慢的场景,重启时间特别长,一旦重启将会造成很大的影响。基于以上考虑,我们开发了单点恢复功能。

上图是单点恢复的基本原理。如图有三个 task,其中中间的 task 失败了,那么首先 Flink 的主节点会重新调度中间的 task,此时上下游的 task 不会失败,而是等待重连。等中间的 task 调度成功后,master 节点会通知下游的 task 去重连上游的 task,与此同时中间的 task 也会去连它上游的 task,通过重新构建读视图来恢复数据的读取。等上下游都连接成功后这个作业就可以正常工作了。

了解完基本原理,再来看一下线上多 task 恢复的案例。实际环境中经常会出现多个 task 同时失败的情况,这个时候我们会按照拓扑顺序来逐个恢复失败的 task,比如上图中是按照从左往右的顺序恢复。
这个功能上线之后,我们内部有将近 100 个作业使用了这个功能,常规故障下作业都可以做到不断流,即便出现小的流量波动,业务也可以做到无感知,业务方彻底告别了服务断流的噩梦。

集群故障一旦发生就是致命性的,所有的数据都会流失,服务也会挂掉。我们的方案主要包含冷备、热备,以及 Flink 和 Kafka 的双集群集成。

冷备主要指的是对数据做备份,集群挂掉以后可以快速在另外一个集群启动计算任务。
如上图,KwaiJobManager 是快手的作业管理服务,其中的 failover coordinator 主要负责故障处理。我们会把所有 jar 包等文件保存在 HDFS,所有的信息保存在 Mysql,这两者都做到了高可用。作业运行在主集群 ClusterA,线上用的是增量快照,会存在文件依赖的问题,所以我们定期做 savepoint 并拷贝到备集群。为了避免文件过多,我们设置了定时删除历史快照。
一旦服务检测到集群 A 故障,就会立刻在集群B启动作业,并从最近一次的快照恢复,确保了状态不丢失。对于用户来说,只需要设置一下主备集群,剩下的全都交由平台方来做,用户全程对故障无感知。

热备就是双集群同时运行一样的任务。我们的热备都是全链路的,Kafka 或者 ClickHouse 等都是双跑。最上面的展示层只会使用其中一份结果数据做展示,一旦出现故障,展示层会立刻切换到另外一份数据,切换过程在一秒以内,用户全程无感知。
相比冷备,热备需要等量的资源来备份运行,但切换的速度更快,比较适用于春晚等要求极高的场景。

Flink 与 Kafka 的双集群集成,主要是因为快手的 Kafka 都具备双集群的能力,所以需要 Flink 支持读写双集群的 Kafka topic,这样某个 Kafka 集群挂掉时Flink可以在线无缝切换。如上图所示,我们 Flink 对 Kafka 双集群做了抽象,一个逻辑上的 topic 底层对应两个物理上的 topic,里面由多个 partition 组合而成,Flink 消费逻辑 topic 就相当于同时读取底层两个物理 topic 的数据。
针对集群的各种变动,我们全部抽象成了 partition 上的扩缩容,比如集群挂掉,可以看成是逻辑 topic 的 partition 缩容;单集群切双集群,可以看成是逻辑 topic 的扩容;topic 的迁移,可以看成逻辑 topic 先扩容再缩容。这里我们都是按照双集群来举例,实际上无论是双集群还是更多的集群,原理都是一样的,我们都提供了支持。

出现以下两种情况的时候需要使用黑名单功能。第一种是反复调度有故障的机器,导致作业频繁失败。另一种是机器因为硬件或网络等原因,导致 Flink 个别节点卡主但未失败。
针对第一种情况,我们开发了阈值拉黑,如果作业在同一个机器上失败或者多次部署阈值失败,超过配置的阈值就会拉黑;针对第二种情况,我们建立了异常分类机制,针对网络卡顿和磁盘卡顿情况,直接驱除容器并且拉黑机器。另外我们还对外暴露了拉黑接口,打通了运维 Yarn 等外部系统,实现了实时拉黑。我们还以 Flink 黑名单为契机,建立了一套完整的硬件异常处理流程,实现了作业自动迁移,全程自动化运维,用户无感知。
03Flink 引擎控制与实践
3.1 Flink实时控制

针对 long-running 的实时作业,用户经常需要作出变更比如调整参数来更改行为,还有一些系统运维比如作业降级、修改日志级别等,这些变更都需要重启作业来生效,有时会高达几分钟到几十分钟,在一些重要的场合,这是无法容忍的。比如在活动期间或者排查问题的关键点,作业一旦停止将会功亏一篑,所以我们需要在不停止作业的情况下实时调整作业的行为,也就是实时控制。

从更广泛的角度来看,Flink 不仅是计算任务,也是一个 long-running service。我们的实时控制正是基于这样的考虑,来为实时计算提供交互式的控制模式。如上图所示,用户通过经典的 kv 数据类型与 Flink dispatcher 交互,Flink 收到消息后,会先将它们持久化到 zk 用于 failover,然后根据具体的消息做相应的控制,比如控制 resource manager、控制 job master 或者其他组件。

我们既支持用户自定义动态参数,也为用户提供了很多现成的系统控制。用户自定义主要是使用 RichFunction 来获取动态参数,并且实现相应的逻辑,这样在作业运行的时候就可以实时传入参数,达到实时控制的效果。
系统提供的实时控制能力,主要包含数据源限速、采样、重置 Kafka offset、调整快照参数以及运维相关的更改日志级别、拉黑节点等功能。除此之外,我们还支持动态修改部分 Flink 原生配置。
快手内部对实时控制功能实现了产品化,用户使用起来非常方便。
3.2 源端控制能力

Flink 处理历史任务或者作业性能跟不上的的时候,会引发以下的问题:
首先 source 的各个并发处理速度不一致,会进一步加重数据的乱序、丢失、对齐慢等问题。其次,快照会持续变大,严重影响作业性能。另外还有流量资源的不可控,在高负载的情况下会引发 CPU 打满、oom 等稳定性问题。
由于 Flink 是一种 pipeline 实时计算,因此从数据源入手可以从根本上解决问题。

首先来看下历史数据精准回放功能。上图是以二倍速率去消费 Kafka 的历史数据,Flink 作业追上 lag 之后就可以转成实时消费。通过这种方式可以有效解决复杂任务的稳定性问题。
上图的公式是一个基本原理,消费倍率 = Kafka 的时间差 / Flink 的系统时间差,用户使用的时候只需要配置倍率即可。

另外一个能力是 QPS 限速。数据流量很大的时候,会导致 Flink 的负载很高以及作业不稳定。我们基于令牌桶算法,实现了一套分布式的限速策略,可以有效减缓 Flink 的压力。使用 QPS 限速后,作业变得非常健康,上图绿色部分可见。19 年的春晚大屏,我们就是通过这个技术实现了柔性可用的保障。
另外我们还支持自动适配 partition 的变更和实时控制,用户可以随时随地调整作业的 QPS。

最后一个功能是数据源对齐,主要指 watermark 的对齐。首先每个 subtask 都会定期向主节点汇报自己的 watermark 进度,主要包括 watermark 的大小和速度。主节点会计算下一个周期的 target,即预期的最大 watermark,再加一个 diff 返回给各个节点。各个 source task 会保证下一个周期的 watermark 不超过设置的 target。上图最下面是 target 的计算公式,预测每个 task 下个周期结束时候的 waterMark 值,再加上我们允许的 maxdiff 然后取最大值,通过这种方式可以保障各个 source 的进度一致,避免 diff 过大导致的稳定性问题。
3.3 作业均衡调度

生产环境中经常会出现资源不均衡的现象,比如第一点 Flink 的 task 分布不均匀,导致 task manager 资源使用不均衡,而作业的性能又往往受限于最繁忙的节点。针对这个问题,我们开发了作业均衡调度的策略;第二点是 CPU 使用不均衡,有些机器被打满而有些机器很闲。针对这个问题,我们开发了 CPU 均衡调度的功能。

上图中有三个 jobVertex,通过 hash shuffle 的方式来连接。上图中间部分显示了 Flink 的调度,每个 jobVertex 都是自上而下往 slot 里调度 task,结果就是前两个 slot 很满而其他 slot 很空闲,第一个 task manager 很满而第二个 task manager 很空闲。这是一个很典型的资源倾斜的场景,我们对此进行了优化。调度的时候首先计算需要的总资源,也就是需要多少个 task manager,然后计算每个 TM 分配的 slot 个数,确保 TM 中的 slot 资源均衡。最后均衡分配 task 到各个 slot 中,确保 slot 中 task 均衡。

实际运行过程中还存在另外一种倾斜情况 —— CPU 倾斜,我们来看下怎么解决这个问题。上图左侧,用户申请了一个核但实际只使用了 0.5 个核,也有申请了一个核实际使用了一个核。按照默认调度策略,大量此类 case 可能会导致有的机器 CPU 使用率很高,有的却很闲,负载高的机器不论是性能还是稳定性都会比较差。那么如何让申请和使用的 diff 尽可能小?
我们的方案是对作业资源精准画像,具体做法分为以下步骤:作业运行过程中统计每个 task 所在容器的 CPU 使用率,然后建立 task 到 executionSlotSharingGroup,再到 container 的映射,这样就知道了每个 task 所在 slot 的 CPU 使用情况,然后根据映射关系重启作业,根据 task 所在 slot 的历史 CPU 使用率来申请相应的资源,一般来说会预留一些 buffer。如上图右图所示,如果预测足够准,重启后 task manager 使用的资源不变,但是申请值变小了,二者的 diff 就变小了。
其实业界一些先进的系统,比如 borg 是支持动态修改申请值的,但我们的底层调度资源不持这种策略,所以只能在 Flink 这一层使用资源画像来解决这个问题。当然资源画像不能保证百分百准确,我们还有其他策略,比如限制高 CPU 负载的机器继续分配资源,尽可能减少不均衡。另外我们还建立了分级保障制度,不同优先级的作业有不同的 cgroup 限制,比如低优先级作业不再超配,高优先级作业允许少量超配,从而避免 CPU 使用过多导致的不均衡。
04快手批处理实践

上图是我们的批处理架构图。最底层为离线集群,中间是 Flink 引擎以及 Flink 的 data stream API、SQL API,再上面是一些平台方比如 sql 入口、定时调度平台等,此外还有一些流批一体的探索,最上面是各种用户比如视频、商业化等。
流批一体中,流的特性是低延时,批的特性是高吞吐。针对流批一体,我们期待系统既能处理 unfield batch 数据,也可以调整数据块的 shuffle 大小等来均衡作业的吞吐和时延。

快手内部对流批一体进行了很多探索,我们为存储数据建立了统一的 Schema 标准,包括流表和批表,用户可以使用相同的代码来处理流表和批表,只是配置不同。产生的结果也需要符合统一的 Schema 标准,这样就可以打通上下游,实现尽可能多的逻辑复用。Schema 统一是我们快手数据治理的一部分,湖仓一体等场景也都有这个需求。
应用场景主要包括以下几个方面:
- 指标计算,比如实时指标和报表计算。
- 数据回溯,利用已有的离线数据重新生成其他指标。
- 数仓加速,主要是数据仓库和数据湖的实时加速。
流批一体带来的收益是多方面的,首先是降低了开发和运维成本,实现了尽可能多的代码逻辑复用,运维不再需要维护多个系统。其次是实时处理和批处理的口径保持一致,保障了最终结果的一致。最后是资源方面的收益,有些场景只需要一套实时系统。

我们在调度方面进行了优化。如上图所示的三个 task,起初 a 和 c 已经完成,b 还在运行。这时 a 失败了,按照默认的策略 ABC 都需要重新运行,即便 c 已经完成。在实际场景中会有大量的 c 进行重算,带来巨大的资源损耗。针对这种情况如果,我们默认开启了以下策略:如果 a 的结果是决定性的(实际上大部分批处理的输出都是决定性的),可以不再重算 c,只需计算 a 和 b。

上图是我们快手内部针对批处理的优化和改进。
第一个是 shuffle service,现在既有内部的集成,也在试用社区的版本,主要是为了实现存储和计算的解耦,同时提高 shuffle 的性能。第二个是动态资源的调度,主要是根据数据量来自动决定算子的并发,避免人工反复调整。第三个是慢节点规避,也叫推测执行,主要是为了减少长尾效应,减少总执行时间。第四个是 hive 的优化,比如 UDF 适配、语法兼容。另外针对 partition 生成 split,我们增加了缓存、多线程生成等方式,极大减少了分片的时间。最后是一些压缩方式的支持,比如支持 gzip、zstd 等。
05未来规划

我们的未来规划主要分为以下几个方面:
- 首先是实时计算,进一步增强 Flink 的性能、稳定性和应用性,并通过实时计算来加速各种业务场景。
- 第二个是在线和离线的统一,包含实时、近实时和批处理。我们期待能用 Flink 统一快手的数据同步、转换和在离线计算,让ETL、数仓、数据湖处理等各类场景,都使用一套 Flink 计算系统。
- 最后一个是弹性可伸缩,主要是云原生相关,包含在离线混部和作业的弹性伸缩等。