作者 | 胡一博(上唐)
数据实时入仓所面临的挑战:高性能、可更新、大规模
大数据场景下,实时数据如何写入实时数仓永远是一个比较大的话题,根据业务场景需求,常见的写入类型有:
- Append only:传统日志类数据(日志、埋点等)中,记录(Record)和记录之间没有关联性,因此新来的记录只需要append到系统中就好了。这是传统大数据系统最擅长的一种类型。
- Insert or Replace:根据设置的主键(Primary Key, PK)进行检查,如果系统中不存在此PK,就把这行记录append进系统; 如果存在,就把系统中旧的记录用新的记录整行覆盖。典型的使用场景有:
上游数据库通过Binlog实时同步,这种写入就是Insert or Replace。
Flink的结果实时写出。Flink持续刷新结果,需要Insert or Replace的写目标表。
Lambda架构下的离线回刷。Lambda架构下离线链路T+1回刷实时结果表中昨天的记录。
- Insert or Update:通常使用在多个应用更新同一行数据的不同字段,实现多个数据源的JOIN。如果这行记录存在,各个应用直接根据PK去update各自的字段;但如果这行记录不存在,那么第一个要写入这行记录的应用就需要INSERT这行记录。典型的使用场景:
画像类应用。这类应用在实时风控、实时广告投放等非常常见。上游多个Flink Job实时计算画像的不同维度,并实时写入到同一行记录的不同字段中。
实时离线数据整合。在需要同时用到实时和离线计算的场合,把同一个PK的实时和离线结果放在同一行记录的不同字段中,就可以方便的同时取到实时和离线的计算结果。

下文中,我们把Insert or Replace和Insert or Update统称为Upsert。
而要保持非常高效的写入性能,实时数仓技术都面临着非常大的挑战,典型的挑战有以下几个方面:
挑战一:Merge on Read还是Merge on Write?
Upsert模式下,新旧数据的合并发生在什么时候,如果希望查询性能好,那么肯定希望合并发生在写入时(Merge on Write)。这样,在系统中任何时刻任一主键都只有一条记录;而如果希望写入性能好,那么就是写入不做合并,查询时再做合并(Merge on Read)。这对于查询是非常不友好的,极大限制查询性能。
Merge on Read原理示例:

Merge on Write原理示例:

挑战二:是否支持主键(Primary Key)模型?
实时数仓在数据模型上是不是支持主键对于Upsert的实时写入是至关重要的。如果没有主键,在写入侧数据的更新就很容易退化成全表更新,性能非常差,在查询侧,Merge On Read也无从做起。
挑战三:是否保证写入的Exactly Once?
如果上游因为failover等因素导致写入重复执行,能不能保证系统中只有一条记录(Merge on Write)或者查询时等效只有一条数据(Merge on Read)且是最新的数据?大数据系统复杂,上游系统failover是常态,不能因为上游failover,就导致实时数仓数据重复。
问题四:数据是否写入即可见?
数据写入的时效性也是实时数仓的重要能力之一。对于BI类等延迟不敏感的业务查询,如果写入时延几秒甚至几分钟可能是可以接受的。而对于很多生产系统,如实时风控、实时大屏等场景,要求数据写入即可见。如果写入出现延迟,就会查询不到最新的数据,严重影响线上业务决策。
挑战五:如何支持超大的数据量和超高的RPS实时写入(每秒记录数,Record Per Second)?
如果数据量小,写入RPS要求低,一个传统的数据库就能很好的解决这个问题。但是在大数据场景下,当RPS达到几十万几百万时,如何更好支持数据的实时写入?同时,如果目标表中已经有海量数量(十亿、百亿甚至更多)时,Upsert要求访问和订正已有数据,这时是否还能支持高性能的Upsert?
Hologres的实时写入模型与性能
Hologres是阿里自研的一站式大数据实时数仓,在设计之初就对实时写入场景进行了充分的考虑,主要有以下几个方面:
- 支持主键,可以高效利用主键更新、删除数据。
- 支持Upsert:完整支持高性能的Append Only、Insert or Replace、Insert or Update 3种能力,可根据业务场景选择写入模式。
- 对于列存表,自动使用Merge on Write方案。对于行存表,自动使用Merge on Read方案,原因如下:
对于列存表,主要是做复杂的OLAP分析,因此查询性能最重要。
对于行存表来说,查询主要是点查,此时Merge on Read单行的开销足够小,因此重点考虑写入性能。在阿里很多点查场景,写入要求非常高的RPS。
- 支持Exactly Once。通过单行SQL事务和主键PK自动去重来实现。无论是批量数据写入(一次更新几亿条记录),还是逐条记录实时写入,Hologres都是保证单条SQL的原子性(ACID)。而对于上游Flink等failover造成的SQL重发,Hologres通过目标表的主键,实现自动覆盖或者忽略(对于Upsert是自动覆盖;对于append,是自动忽略Insert or Ignore)。因此,目标表是幂等的。
- 写入即可见。Hologres没有类似ElasticSearch的build过程,也没有类似ClickHouse或者Greenplum的攒批过程,数据通过SQL写入时,SQL返回即表示写入完成,数据即可查询。因此通过Flink等实时写入(背后也是SQL写入)能满足写入即可见,无延迟。
这5个设计选取也是传统数据库的选择。经验证明,这对于用户来说是最自然、最友好的使用方式。Hologres的创新在于把这个方案成功的应用于大数据领域(超高RPS写入和超大存储量)。
下图为Hologres 128C实例下,10个并发实时写入20列的列存表的测试结果。其中竖轴表示每秒写入记录数,4个场景分别为:
- case1:写入无主键表;
- case2:写入有主键表(Insert or Replace),并且每次INSERT的主键和表已有数据都不冲突;
- case3:写入有主键表(Insert or Replace),并且每次INSERT的主键和表已有数据均冲突,表中数据量为2亿。
- case4:写入有主键表(Insert or Replace),并且每次INSERT的主键和表已有数据均冲突,表中数据量为20亿。

结果解读:
- 对比case1和case2,可以看到Hologres判断主键是否存在性能损失较小;
- 对比case2,case3,case4,可以看到主键冲突时,hologres定位数据所在文件并标记DELETE基本不随数据规模上涨而上涨,可以应对海量数据下的高速Upsert。
与常见产品对比
写入方式 | 更新/删除方式 | 更新删除对查询的影响 | |
ClickHouse | 攒批写入,每个批次完成才能查询到数据 | merge on read | 查询明细时相同pk可能多次出现,取决于compaction时机 |
Doris | 攒批写入,每个批次完成才能查询到数据 | merge on read | 查询时要进行合并,性能有损失 |
Hudi/iceberg/delta lake等数据湖产品 | 攒批写入,每个批次完成才能查询到数据 | merge on read或copy on write,大多会造成全量数据重写,导致IO放大 | merge on read,查询时要进行合并,性能有损失;copy on write,查询性能没有影响 |
Hologres | 流式写入,写入即可查询,低延迟 | Merge on write强主键模型,更新/删除成本非常低。 | 通过delete bitmap技术实现Merge on Write,更新/删除对查询没有影响 |
Merge on Write模式下 实时写入与更新的常见原理
一个典型的Upsert(Insert or Replace)场景如下,一张用户表,通过INSERT INTO ON CONFLICT执行插入新用户/更新老用户操作:
CREATE TABLE users (
id int not null,
name text not null,
age int,
primary key(id)
);
INSERT INTO users VALUES (?,?,?)
ON CONFLICT(id) DO UPDATE
SET name = EXCLUDED.name, sex = EXCLUDED.sex, age = EXCLUDED.age;
性能最高的实现方式是写入时APPEND ONLY不断写入新文件,在查询时进行数据逻辑合并(Merge on Read)。但这种对查询的性能打击是致命的,每次查询要多个版本的数据join过才能获取到一行最新的值。实时数仓在写时合并(Merge on Write)方案下,Upsert的实现一般分为三步:
- 定位旧数据所在文件。
- 处理旧数据
- 写入新数据
要实现高RPS的实时Upsert,本质就是要把这3个步骤都做快。
1.定位旧数据所在文件
快速定位旧数据文件,有如下几种做法:
1)bloom过滤器
bloom过滤器原理上是为每个key生成若干个hash值,通过hash碰撞来判断是否存在相同的key。为每个文件生成一个bloom过滤器,可以明确排除不存在该key的文件。Bloom过滤器可以以很高的精度(99%甚至更高)确定一个Key不在一个文件中。
2)范围过滤器
范围过滤器就是记录文件内列的最大最小值,是一个代价非常小的过滤方式,当key基本处于一个递增态势是可以得到一个非常好的过滤效果。
3)外部索引
Hudi支持HBase索引,在HBase中保存PK->file_id的映射。HBase LSM-tree的存储结构对于key-value的查询非常高效,Hudi通过这种方式也不再需要去猜测哪些文件可能包含了这个PK。但是这里有两个问题:
- HBase状态和Hudi表状态的一致性,因为HBase和Hudi是独立的两套系统,一方如果发生故障可能导致索引失效。
- 性能上限是HBase的PK点查性能。要取得更好的写入性能是困难的。
2.处理旧数据+写入新数据
常见的是两种处理方法:
1)刷新数据文件
定位到数据所在文件后,将文件和新数据合并后生成一个新的数据文件覆盖旧文件。(Copy on Write)。Iceberg支持这种模式。这会导致非常严重的写放大。
2)引入delta文件
定位到数据所在文件后:
- 在数据文件对应的delta文件中标记该行旧数据为删除状态。
- 在delta中追加新数据的信息。
这种方式没有写放大,但是在查询时需要将数据文件和对应的delta文件做join操作。
Hologres 基于Memtable的写入原理
Hologres的实时写入与更新基本遵循Merge on Write的原理。对于实时数仓场景下的record级别的更新/插入,Hologres采用强主键的方式来让单行更新/插入足够轻量化,采用memtable + wal log的方式,支持高频次的写入操作。
1.文件模型
Hologres每张列存表底层会保存三种文件:
第一种是主键索引文件,采用行存结构存储,提供高速的key-value服务,索引文件的key为表的主键,value为unique_id和聚簇索引。unique_id每次Upsert自动生成,单调递增。主键索引文件实现高效的主键冲突判定并辅助数据文件定位;
第二种是数据文件,采用列存结构存储,文件内按照聚簇索引+unique_id生成稀疏索引,并对unique_id生成范围过滤器;
第三种是delete bitmap文件,每个file id对应一个bitmap,bitmap中第N位为1表示file id中的第N行标记为删除。delete bitmap在列存模型下,相当于是表的一列数据。Update时只刷新bitmap信息既保留了Merge on Write对查询性能几乎零破坏的优点,又极大降低了IO的开销。
三类文件都是先写入memtable,memtable达到特定大小后转为不可变的memtable对象,并生成新的memtable供后续写入使用。不可变的memtable对象由异步的flush线程将其持久化为磁盘上的文件。
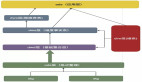
2.Upsert流程
通过这个流程图可以看到:
- 如果主键没有发生冲突,那么一次Upsert的的开销= 一次索引查询 + 两次内存写入操作;
- 如果主键发生了冲突,那么一次Upsert的开销=一次索引查询 + 一次文件及行号定位 +三次内存写入操作。

3.Upsert示例
下面通过示例来展示一次Upsert的过程。假设pk为id,cluserting key为name,数据列为age。(deleted信息物理上存储于delete bitmap中,但逻辑上等同与表的一列,下文将合并在数据文件中一同描述)
CREATE TABLE users (
id text not null,
name text not null,
age int,
primary key(id)
);
表初始数据如下:
id | name | age |
u0 | 张三 | 10 |
u1 | 李四 | 11 |
u2 | 王五 | 12 |

此时执行如下SQL:
INSERT INTO users VALUES ('u1','新李四',12)
ON CONFLICT(id) DO UPDATE
SET name = EXCLUDED.name
, age = EXCLUDED.age;
更新过程如下:

更新完成后表数据如下:
id | name | age |
u0 | 张三 | 10 |
u1 | 新李四 | 12 |
u2 | 王五 | 12 |
Hologres写入全链路优化,雕琢细节
Hologres在接口上完全兼容PostgreSQL(包括语法、语义、协议等),所以可以直接使用PostgreSQL的JDBC Driver连接Hologres进行数据读写。除了写入原理上的创新性外,Hologres也针对写入进行了全链路的优化,以达到更高性能的吞吐。
1.Fixed Plan:降低、避免SQL解析与优化器的开销
- Query Optimizer进行shortcut
对于符合pattern的Upsert sql,Hologres的Query Optimizer进行了相应的short cut,Upsert Query并不会进入Opimizer的完整流程。Query进入FrontEnd后它会交由Fixed Planner进行处理,并由其生成对于的Fixed Plan(Upsert的物理Plan),Fixed Planner非常轻,无需经过任何的等价变换、逻辑优化、物理优化等步骤,仅仅是基于AST树进行了一些简单的分析并构建出对应的Fixed Plan,从而尽量规避掉优化器的开销。
- Prepared Statement
尽管Query Optimizer对Upsert Query进行了short cut,但是Query进入到FrontEnd后的解析开销依然存在、Query Optimizer的开销也没有完全避免。
Hologres兼容Postgres,Postgres的前、后端通信协议有extended协议与simple协议两种:
1) simple协议:是一次性交互的协议,Client每次会直接发送待执行的SQL给Server,Server收到SQL后直接进行解析、执行,并将结果返回给Client。simple协议里Server无可避免的至少需要对收到的SQL进行解析才能理解其语义。
2)extended协议:Client与Server的交互分多阶段完成,整体大致可以分成两大阶段。
- 第一阶段:Client在Server端定义了一个带名字的Statement,并且生成了该Statement所对应的generic plan(不与特定的参数绑定的通用plan)。

- 第二阶段:用户通过发送具体的参数来执行第一阶段中定义的Statement。第二阶段可以重复执行多次,每次通过带上第一阶段中所定义的Statement名字,以及执行所需要的参数,使用第一阶段生成的generic plan进行执行。由于第二阶段可以通过Statement名字和附带的参数来反复执行第一个阶段所准备好的generic plan,因此第二个段在Frontend的开销几乎等同于0。
为此Hologres基于Postgres的extended协议,支持了Prepared Statement,做到了Upsert Query在Frontend上的开销接近于0。
2.高性能的内部通信
- Reactor模型、全程无锁的异步操作
内部通信原理类似reactor模型,每个目标shard对应一个eventloop,以“死循环”的方式处理该shard上的请求。由于HOS(Hologres Operation System)对调度执行单元的抽象,即使是shard很多的情况下,这种工作方式的基础消耗也足够低。
- 高效的数据交换协议binary row
通过自定义一套内部的数据通信协议binary row来减少整个交互链路上的内存的分配与拷贝。
- 反压与凑批
BHClient可以感知后端的压力,进行自适应的反压与凑批,在不影响原有Latency的情况下提升系统吞吐。
3.稳定可靠的后端实现
- 基于C++纯异步的开发
Hologres采用C++进行开发,相较于Java,native语言使得我们能够追求到更极致的性能。同时基于HOS提供的异步接口进行纯异步开发,HOS通过抽象ExecutionContext来自我管理CPU的调度执行,能够最大化的利用硬件资源、达到吞吐最大化。
- IO优化与丰富的Cache机制
Hologres实现了非常丰富的Cache机制row cache、block cache、iterator cache、meta cache等,来加速热数据的查找、减少IO访问、避免新内存分配。当无可避免的需要发生IO时,Hologres会对并发IO进行合并、通过wait/notice机制确保只访问一次IO,减少IO处理量。通过生成文件级别的词典及压缩,减少文件物理存储成本及IO访问。
总结
Hologres是阿里巴巴自主研发的一站式实时数仓引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与即席分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),并在阿里巴巴双11等大促核心场景上,Hologres写入峰值达11亿条+/秒,经过大规模数据生产验证。
常见的数据仓库产品,大多都会牺牲读性能或者牺牲写性能,并且它们往往文件作为访问介质,这天然约束了数据更新的频率。Hologres 通过memtable使数据可以高频更新,通过delete map让读操作避免了join操作保持了良好的读性能,通过主键模型解决了写操作时的效率问题,做到了读写性能的兼顾。同时Hologres同Flink、Spark等计算框架原生集成,通过内置Connector,支持高通量数据实时写入与更新,支持源表、结果表、维度表多种场景,支持多流合并等复杂操作。
从阿里集团诞生到云上商业化,随着业务的发展和技术的演进,Hologres也在持续不断优化核心技术竞争力,为了让大家更加了解Hologres,我们计划持续推出Hologres底层技术原理揭秘系列,从高性能存储引擎到高效率查询引擎,高吞吐写入到高QPS查询等,全方位解读Hologres,请大家持续关注!