Meta Platforms今天开放了NLLB-200的系统代码,NLLB-200是Meta内部开发的一个人工智能系统,可以翻译200种语言的文本。
Meta还公布了一套工具,旨在帮助研究人员更轻松地将NLLB-200应用于软件项目。
根据Meta的说法,NLLB-200可以理解的200种语言中,许多语言都没有得到其他AI翻译系统的良好支持。目前被广泛使用的翻译工具支持的非洲语言不到25种,而NLLB-200 支持多达55种非洲语言。
Meta表示,翻译准确性是NLLB-200优于其他工具的另一个方面。Meta采用的是BLEU评估系统的准确性标准,BLEU是一种用于衡量机器翻译文本质量的算法。Meta称,NLLB-200的BLEU评分比之前平均高出44%。
Meta首席执行官Mark Zuckerberg表示:“我们刚刚开源了一个自主开发的AI模型,该模型可以翻译200种不同的语言——其中许多语言未得到当前翻译系统的支持。我们把这个项目称之为No Language Left Behind,我们使用的人工智能建模技术正在为全球数十亿人所使用的语言进行高质量的翻译。”
NLLB-200有超过500亿个参数,这些配置决定了AI系统处理数据的方式。人工智能系统参数越多,准确性就越高。
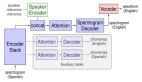
NLLB-200具有如此大量的参数,并不是它能够以高精度支持200种语言的唯一因素,因为NLLB-200系统还借鉴了Meta工程师开发的很多其他AI创新。
Meta使用内部开发的LASER工具包为机器学习相关研究提供支持。研究人员使用该工具包可以对神经网络进行训练,以一种语言执行某个特定的任务,然后相对轻松地使神经网络适应其他语言,这对于翻译这一用途来说是很有用处的。Meta开发了新的NLLB-200系统,支持改进版LASER——LASER3。
LASER的原始版本包括一个名为LSTM的神经网络,这是一个将文本转换为AI系统可以理解的、以数学方式表示的专用组件。这种数学表示有助于生成更准确的翻译结果。在LASER3中,Meta用Transformer代替了LSTM神经网络,前者是一种高级自然语言处理模型,可以更有效地执行相同的任务。
Meta还使用了其他几种方法来改进NLLB-200的功能,例如Meta升级了用于收集训练数据的系统,并对AI训练工作流程进行了更改。

Meta使用内部开发的Research SuperCluster超级计算机(如图)来训练NLLB-200。今年1月Meta首次介绍Research SuperCluster的时候称,该系统配备了6080个Nvidia最新的A100数据中心GPU,最终将升级到配置16000个GPU。
Meta计划使用NLLB-200在Facebook、Instagram和其他平台上提供更好的自动翻译功能,预计该系统每天将支持超过250亿次翻译。
Meta在内部努力推广NLLB-200的同时,还计划帮助其他企业组织将该系统应用到他们自己的软件项目中。
除了NLLB-200之外,Meta还开源了可用于训练AI的代码,以及一个名为FLORES-200的数据集,用于评估翻译的准确性。Meta将提供高达200000美元的资金,以帮助非营利组织采用NLLB-200。除此之外,Meta还将与Wikimedia Foundation展开合作,将自动翻译技术应用于维基百科文章。