作者:校娅 沈元 朱迪等
1. 背景
点评搜索是大众点评App的核心入口之一,用户通过搜索来满足不同场景下对生活服务类商户的找店需求。搜索的长期目标是持续优化搜索体验,提升用户的搜索满意度,这需要我们理解用户搜索意图,准确衡量搜索词与商户之间的相关程度,尽可能展示相关商户并将更相关的商户排序靠前。因此,搜索词与商户的相关性计算是点评搜索的重要环节。
大众点评搜索场景面临的相关性问题复杂多样,用户的搜索词比较多样,例如搜索商户名、菜品、地址、类目以及它们之间的各种复杂组合,同时商户也有多种类型的信息,包括商户名、地址信息、团单信息、菜品信息以及其他各种设施和标签信息等,导致Query与商户的匹配模式异常复杂,容易滋生出各种各样的相关性问题。具体来说,可以分为如下几种类型:
- 文本误匹配:在搜索时,为保证更多商户被检索和曝光,Query可能会被拆分成更细粒度的词进行检索,因此会带来Query错误匹配到商户不同字段的问题,如图1(a)所示的用户搜“生蚝火锅”应该想找汤底中包含生蚝的火锅,而“生蚝”和“火锅”分别匹配到商户的两个不同菜品。
- 语义偏移:Query与商户字面匹配,但商户与Query的主要意图在语义上不相关,如“奶茶”-“黑糖珍珠奶茶包”,如图1(b)所示。
- 类目偏移:Query与商户字面匹配且语义相关,但主营类目与用户需求不符,例如用户搜索“水果”时一家提供“果盘”的KTV商户明显与用户的需求不相关。

(a) 文本误匹配示例

(b) 语义偏移示例
图1 点评搜索相关性问题示例
基于字面匹配的相关性方法无法有效应对上述问题,为了解决搜索列表中的各类不符合用户意图的不相关问题,需要更准确地刻画搜索词与商户的深度语义相关性。本文在基于美团海量业务语料训练的MT-BERT预训练模型的基础上,在大众点评搜索场景下优化Query与商户(POI,对应通用搜索引擎中的Doc)的深度语义相关性模型,并将Query与POI的相关性信息应用在搜索链路各环节。
本文将从搜索相关性现有技术综述、点评搜索相关性计算方案、应用实战、总结与展望四个方面对点评搜索相关性技术进行介绍。其中点评搜索相关性计算章节将介绍我们如何解决商户输入信息构造、使模型适配点评搜索相关性计算及模型上线的性能优化等三项主要挑战,应用实战章节将介绍点评搜索相关性模型的离线及线上效果。
2. 搜索相关性现有技术
搜索相关性旨在计算Query和返回Doc之间的相关程度,也就是判断Doc中的内容是否满足用户Query的需求,对应NLP中的语义匹配任务(Semantic Matching)。在大众点评的搜索场景下,搜索相关性就是计算用户Query和商户POI之间的相关程度。
文本匹配方法:早期的文本匹配任务仅考虑了Query与Doc的字面匹配程度,通过TF-IDF、BM25等基于Term的匹配特征来计算相关性。字面匹配相关性线上计算效率较高,但基于Term的关键词匹配泛化性能较差,缺少语义和词序信息,且无法处理一词多义或者多词一义的问题,因此漏匹配和误匹配现象严重。
传统语义匹配模型:为弥补字面匹配的缺陷,语义匹配模型被提出以更好地理解Query与Doc的语义相关性。传统的语义匹配模型主要包括基于隐式空间的匹配:将Query和Doc都映射到同一个空间的向量,再用向量距离或相似度作为匹配分,如Partial Least Square(PLS)[1];以及基于翻译模型的匹配:将Doc映射到Query空间后进行匹配或计算Doc翻译成Query的概率[2]。
随着深度学习和预训练模型的发展,深度语义匹配模型也被业界广泛应用。深度语义匹配模型从实现方法上分为基于表示(Representation-based)的方法及基于交互(Interaction-based)的方法。预训练模型作为自然语言处理领域的有效方法,也被广泛使用在语义匹配任务中。

(a) 基于表示的多域相关性模型

(b) 基于交互的相关性模型
图2 深度语义匹配相关性模型
基于表示的深度语义匹配模型:基于表示的方法分别学习Query及Doc的语义向量表示,再基于两个向量计算相似度。微软的DSSM模型[3]提出了经典的双塔结构的文本匹配模型,即分别使用相互独立的两个网络构建Query和Doc的向量表示,用余弦相似度衡量两个向量的相关程度。微软Bing搜索的NRM[4]针对Doc表征问题,除了基础的Doc标题和内容,还考虑了其他多源信息(每类信息被称为一个域Field),如外链、用户点击过的Query等,考虑一个Doc中有多个Field,每个Field内又有多个实例(Instance),每个Instance对应一个文本,如一个Query词。模型首先学习Instance向量,将所有Instance的表示向量聚合起来就得到一个Field的表示向量,将多个Field的表示向量聚合起来得到最终Doc的向量。SentenceBERT[5]将预训练模型BERT引入到双塔的Query和Doc的编码层,采用不同的Pooling方式获取双塔的句向量,通过点乘、拼接等方式对Query和Doc进行交互。
大众点评的搜索相关性早期模型就借鉴了NRM和SentenceBERT的思想,采用了图2(a)所示的基于表示的多域相关性模型结构,基于表示的方法可以将POI的向量提前计算并存入缓存,线上只需计算Query向量与POI向量的交互部分,因此在线上使用时计算速度较快。
基于交互的深度语义匹配模型:基于交互的方法不直接学习Query和Doc的语义表示向量,而是在底层输入阶段就让Query和Doc进行交互,建立一些基础的匹配信号,再将基础匹配信号融合成一个匹配分。ESIM[6]是预训练模型引入之前被业界广泛使用的经典模型,首先对Query和Doc进行编码得到初始向量,再用Attention机制进行交互加权后与初始向量进行拼接,最终分类得到相关性得分。
引入预训练模型BERT进行交互计算时,通常将Query和Doc拼接作为BERT句间关系任务的输入,通过MLP网络得到最终的相关性得分[7],如图2(b)所示。CEDR[8]在BERT句间关系任务获得Query和Doc向量之后,对Query和Doc向量进行拆分,进一步计算Query与Doc的余弦相似矩阵。美团搜索团队[9]将基于交互的方法引入美团搜索相关性模型中,引入商户品类信息进行预训练,并引入实体识别任务进行多任务学习。美团到店搜索广告团队[10]提出了将基于交互的模型蒸馏到基于表示的模型上的方法,实现双塔模型的虚拟交互,在保证性能的同时增加Query与POI的交互。
3. 点评搜索相关性计算
基于表示的模型重在表示POI的全局特征,缺乏线上Query与POI的匹配信息,基于交互的方法可以弥补基于表示方法的不足,增强Query和POI的交互,提升模型表达能力,同时,鉴于预训练模型在文本语义匹配任务上的强劲表现,点评搜索相关性计算确定了基于美团预训练模型MT-BERT[11]的交互式方案。将基于预训练模型的交互式BERT应用在点评搜索场景的相关性任务中时,仍存在诸多挑战:
- 如何更好地构造POI侧模型输入信息:Doc侧模型输入信息的构造是相关性模型中的重要环节。在通用网页搜索引擎中,Doc的网页标题对相关性的判断极为重要,但在点评搜索场景下,POI信息具有字段多、信息复杂的特点,不存在能提供类似“网页标题”信息量的字段,每个商户都通过商户名、类目、地址、团单、商户标签等多种结构化信息来表达。在计算相关性分数时,大量多源商户信息无法全部输入到模型中,而仅使用商户名和类目等基础信息又会因为信息缺失无法达到满意的效果,因此如何更好地构造具有丰富信息量的POI侧模型输入是我们要解决的首要问题。
- 如何优化模型来更好地适配点评搜索相关性计算:大众点评搜索场景中的文本信息与通用的预训练模型语料信息有一定差异,例如通用语义场景下“开心”和“高兴”同义,但在点评搜索的场景下“开心烧烤”和“高兴烧烤”却是两家完全不同的品牌。同时,Query和POI的相关性判定逻辑与通用NLP场景的语义匹配任务也不完全相同,Query和POI的匹配模式非常复杂,当Query匹配到POI的不同字段时,相关性的判定结果也有所不同,例如Query“水果”匹配到“水果店”商户类目时相关性较高,而命中KTV的“水果拼盘”标签时则相关性较弱。因此,相比通用的基于交互的BERT句间关系语义匹配任务,相关性计算还需要关注Query和POI两部分之间的具体匹配情况。如何优化模型来适配点评搜索的场景,并能处理复杂多样的相关性判断逻辑,尽可能地解决各种不相关问题,是我们面临的主要挑战。
- 如何解决预训练相关性模型的在线性能瓶颈:基于表示的模型虽计算速度较快但表达能力有限,基于交互的模型可以增强Query和POI的交互从而提升模型效果,但在线上使用时存在较大的性能瓶颈。因此,在线上使用12层BERT的基于交互的模型时,如何在保证模型计算效果的同时保证整个计算链路的性能,使其在线上稳定高效运行,是相关性计算线上应用的最后一道关卡。
经过不断探索与尝试,我们针对POI侧的复杂多源信息,构造了适配点评搜索场景的POI文本摘要;为了让模型更好地适配点评搜索相关性计算,采用了两阶段训练的方法,并根据相关性计算的特点改造了模型结构;最后,通过优化计算流程、引入缓存等措施,成功降低了模型实时计算和整体应用链路的耗时,满足了线上实时计算BERT的性能要求。
3.1 如何更好地构造POI侧模型输入信息
在判定Query与POI的相关程度时,POI侧有十几个参与计算的字段,某些字段下的内容特别多(例如一个商户可能有上百个推荐菜),因此需要找到合适的方式抽取并组织POI侧信息,输入到相关性模型中。通用搜索引擎(如百度),或常见垂类搜索引擎(如淘宝),其Doc的网页标题或商品标题信息量丰富,通常是相关性判定过程中Doc侧模型输入的主要内容。
如图3(a)所示,在通用搜索引擎中,通过搜索结果的标题可以一眼看出对应网站的关键信息及是否与Query相关,而在图3(b)大众点评App的搜索结果中,仅通过商户名字段无法得到充足的商户信息,需要结合商户类目(奶茶果汁)、用户推荐菜品(奥利奥利奶茶)、标签(网红店)、地址(武林广场)多个字段才能判断该商户与Query“武林广场网红奶茶”的相关性。

(a) 通用搜索引擎搜索结果示例

(b) 大众点评App搜索结果示例
图3 通用搜索引擎与大众点评搜索结果对比
标签抽取是业界比较通用的抽取主题信息的途径,因此我们首先尝试了通过商户标签来构造POI侧模型输入的方法,根据商户的评论、基础信息、菜品、商户对应的头部搜索点击词等抽取出具有代表性的商户关键词来作为商户标签。在线上使用时,将已抽取的商户标签,及商户名和类目基础信息一起作为模型的POI侧输入信息,与Query进行交互计算。然而,商户标签对商户信息的覆盖仍不够全面,例如用户搜索菜品“鸡蛋羹”时,某个距用户很近的韩式料理店有鸡蛋羹售卖,但该店的招牌菜、头部点击词等均与“鸡蛋羹”无关,导致该店所抽取的标签词也与“鸡蛋羹”相关性较低,因此模型会将该店判断为不相关,从而对用户体验带来伤害。
为了获取最全面的POI表征,一种方案是不抽取关键词,直接将商户的所有字段拼接到模型输入中,但是这种方式会因为模型输入长度过长而严重影响线上性能,且大量冗余信息也会影响模型表现。
为构造更具信息量的POI侧信息作为模型输入,我们提出了POI匹配字段摘要抽取的方法,即结合线上Query的匹配情况实时抽取POI的匹配字段文本,并构造匹配字段摘要作为POI侧模型输入信息。POI匹配字段摘要抽取流程如图4所示,我们基于一些文本相似度特征,将与Query最相关且最具信息量的文本字段提取出来,并融合字段类型信息构建成匹配字段摘要。线上使用时,将已抽取的POI匹配字段摘要、商户名及类目基础信息一起作为POI侧模型输入。

图4 POI匹配字段摘要抽取流程在确定POI侧模型输入信息后,我们采用BERT句间关系任务,先用MT-BERT对Query侧和POI侧匹配字段摘要信息进行编码,然后使用池化后的句向量计算相关分。采用POI匹配字段摘要的方案构造POI侧模型输入信息后,配合样本迭代,相比基于标签的方法,模型的效果有了极大的提升。
3.2 如何优化模型来更好地适配点评搜索相关性计算
让模型更好地适配点评搜索相关性计算任务包含两层含义:大众点评搜索场景下的文本信息与MT-BERT预训练模型使用的语料在分布上存在着一定的差异;预训练模型的句间关系任务与Query和POI的相关性任务也略有不同,需要对模型结构进行改造。经过不断探索,我们采用基于领域数据的两阶段训练方案,结合训练样本构造,使预训练模型更适配点评搜索场景的相关性任务;并提出了基于多相似矩阵的深度交互相关性模型,加强Query和POI的交互,提升模型对复杂的Query和POI信息的表达能力,优化相关性计算效果。
3.2.1 基于领域数据的两阶段训练
为了有效利用用户点击数据,并使预训练模型MT-BERT更适配点评搜索相关性任务,我们借鉴百度搜索相关性[12]的思想,引入多阶段训练方法,采用用户点击和负采样数据进行第一阶段领域适配的预训练(Continual Domain-Adaptive Pre-training),采用人工标注数据进行第二阶段训练(Fine-Tune),模型结构如下图5所示:

图5 基于点击及人工标注数据的两阶段训练模型结构
基于点击数据的第一阶段训练
引入点击数据作为第一阶段训练任务的直接原因是在点评搜索场景下存在着一些特有的问题,例如“开心”和“高兴”两个词在通用场景下是几乎完全同义的词,但是在点评搜索的场景下“开心烧烤”和“高兴烧烤”却是两家完全不同的品牌商户,因此点击数据的引入能够帮助模型学习到搜索场景下的一些特有知识。但是直接将点击样本用于相关性判断会存在较大噪声,因为用户点击某个商户可能是由于排序较为靠前导致的误点击,而未点击某个商户也可能仅仅是因为商户距离较远,而并不是因为相关性问题,因此我们引入了多种特征和规则来提高训练样本自动标注的准确率。
在构造样本时,通过统计是否点击、点击位次、最大点击商户距用户的距离等特征筛选候选样本,将曝光点击率大于一定阈值的Query-POI对作为正例,并根据业务特点对不同类型商户调整不同的阈值。在负例的构造上,Skip-Above采样策略将位于点击商户之前且点击率小于阈值的商户才做为负样本。此外,随机负采样的方式可以为训练样本补充简单负例,但考虑随机负采样时也会引入一些噪声数据,因此我们利用人工设计的规则对训练数据进行降噪:当Query的类目意图与POI的类目体系较为一致时或者与POI名高度匹配时,则将其从负样本中剔除。
基于人工标注数据的第二阶段训练
经过第一阶段训练后,考虑到无法完全清除掉点击数据中的噪音,以及相关性任务的特点,因此需要引入基于人工标注样本的第二阶段训练来对模型进行纠偏。除了随机采样一部分数据交给人工去标注外,为了尽可能提升模型的能力,我们通过难例挖掘和对比样本增强方式生产大量高价值样本交给人工去标注。具体如下:
1)难例挖掘
- 特定类型样本挖掘:通过设计一种基于Query和POI的特征和两者的匹配情况来刻画BadCase类型的方法,自动化从候选数据集中筛选出特定BadCase类型的样本进行送标。
- 用户点击过但线上旧版模型判定为不相关的:该方法可以挖掘出当前线上模型预测错误及语义接近的用户难以区分的难例。
- 边缘采样:通过边缘采样的方式挖掘具有较高不确定性的样本,如抽取模型预测得分在阈值附近的样本。
- 模型或人工识别困难的样本:用当前模型预测训练集,将模型预测结果与标注标签不一致的样本,及人工标注标签有冲突的样本类型重新送标。
2)对比样本增强:借鉴对比学习的思想,为一些高度匹配的样本生成对比样本进行数据增强,并进行人工标注确保样本标签的准确率。通过对比样本之间的差异,模型可以关注到真正有用的信息,同时提升对同义词的泛化能力,从而得到更好的效果。
- 针对菜品词较容易出现的跨菜品匹配的相关性问题(例如搜“鹅肝汉堡”匹配到售卖“牛肉汉堡”和“鹅肝寿司”的商家),分别用菜品的各个子成分与推荐菜字段进行匹配,生产大量对比样本,加强模型对于跨菜品匹配问题的识别能力。
- 针对菜品词命中推荐菜前缀的问题,通过改造完全匹配到推荐菜的情况(搜“榴莲蛋糕”匹配到售卖“榴莲蛋糕”的商家),仅保留搜索词中的前缀,构造出匹配推荐菜前缀的对比样本(搜"榴莲"和售卖"榴莲蛋糕"的商家),使模型能更好的区分匹配推荐菜前缀时的情况。

图6 对比样本增强示例
以跨菜品匹配的相关性问题为例,如上图6所示,同样是Query拆开后与商户的多个推荐菜字段匹配的情况,Query“榴莲蛋糕”与推荐菜“榴莲千层、黑森林蛋糕”是相关的,但Query“鹅肝汉堡”与“铁板鹅肝、芝士牛肉汉堡”是不相关的,为了增强模型对这类高度匹配但结果相反的Case的识别能力,我们构造了“榴莲蛋糕”与“榴莲千层”、“鹅肝汉堡”与“铁板鹅肝”这两组对比样本,去掉了与Query在文本上匹配但对模型判断没有帮助的信息,让模型学到真正决定是否相关的关键信息,同时提升模型对“蛋糕”和“千层”这类同义词的泛化能力。类似地,其他类型的难例同样可以用这种样本增强方式来提升效果。
3.2.2 基于多相似矩阵的深度交互模型
BERT句间关系是一个通用的NLP任务,用于判断两个句子的关系,而相关性任务是计算Query和POI的相关程度。在计算过程中,句间关系任务不仅计算Query与POI的交互,还计算Query内部和POI内部的交互,而相关性计算更关注Query与POI的交互。此外,在模型迭代过程中,我们发现部分类型的困难BadCase对模型的表达能力有更高要求,例如文本高度匹配但不相关的类型。因此,为进一步提升模型对复杂的Query和POI在相关性任务上的计算效果,我们对第二阶段训练中的BERT句间关系任务进行改造,提出了基于多相似矩阵的深度交互模型,通过引入多相似矩阵来对Query和POI进行深度交互,引入indicator矩阵以更好地解决困难BadCase问题,模型结构如下图7所示:

图7 基于多相似矩阵的深度交互相关性模型
受CEDR[8]的启发,我们将经过MT-BERT编码后的Query和POI向量进行拆分,用于显式地计算两部分的深度交互关系,将Query和POI拆分并进行深度交互,一方面可以专门用于学习Query与POI的相关程度,另一方面,增加的参数量可以提升模型的拟合能力。
参考MatchPyramid[13]模型,深度交互相关性模型计算了四种不同的Query-Doc相似矩阵并进行融合,包括Indicator、Dot-product、余弦距离及欧氏距离,并与POI部分的输出进行Attention加权。其中Indicator矩阵用来描述Query与POI的Token是否一致,计算方式如下:
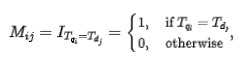
其中代表匹配矩阵的第行列对应的元素,代表Query的第个Token,代表POI的第个Token。由于Indicator矩阵是表示Query与POI是否字面匹配的矩阵,与另外三个语义匹配矩阵的输入格式不同,Dot-product、余弦距离、欧式距离三个匹配矩阵先进行融合,再将得到的结果与Indicator矩阵进一步融合后再计算最终的相关性得分。
Indicator矩阵可以较好地刻画Query和POI的匹配关系,该矩阵的引入主要考虑到判定Query和POI相关程度时的一个难点:有时即使文本高度匹配,两者也不相关。基于交互的BERT模型结构更容易将文本匹配程度高的Query和POI判定为相关,但是在点评搜索场景中,有些难例却未必如此。比如“豆汁”和“绿豆汁”虽然高度匹配,但并不相关。“猫空”和“猫的天空之城”虽然是拆开匹配,但因为前者是后者的缩写而相关。因此,将不同的文本匹配情况通过Indicator矩阵直接输入给模型,让模型显式地接收“包含”、“拆开匹配”等文本匹配情况,在帮助模型提升对难例判别能力的同时,也不会影响大部分正常的Case的表现。
基于多相似矩阵的深度交互相关性模型将Query和POI拆分后计算相似矩阵,相当于让模型对Query和POI进行显式交互,使模型更加适配相关性任务。多个相似矩阵则增加了模型对Query和POI相关程度计算的表征能力,而Indicator矩阵则是针对相关性任务中复杂的文本匹配情况做的特殊设计,让模型对不相关结果的判断更加准确。
3.3 如何解决预训练相关性模型的在线性能瓶颈
将相关性计算部署在线上时,现有方案通常会采用知识蒸馏的双塔结构[10,14]以保证线上计算效率,但此种处理方式或多或少对于模型的效果是有损的。点评搜索相关性计算为保证模型效果,在线上使用了基于交互的12层BERT预训练相关性模型,需要对每个Query下的数百个POI经过12层BERT的模型预测。为保证线上计算效率,我们从模型实时计算流程和应用链路两个角度出发,通过引入缓存机制、模型预测加速、引入前置黄金规则层、将相关性计算与核心排序并行化等措施优化相关性模型在线上部署时的性能瓶颈,使得12层基于交互的BERT相关性模型在线上稳定高效运行,保证可以支持数百个商户和Query间的相关性计算。
3.3.1 相关性模型计算流程性能优化

图8 相关性模型线上计算流程图
点评搜索相关性模型的线上计算流程如图8所示,通过缓存机制及TF-Serving模型预测加速来优化模型实时计算的性能。
为有效利用计算资源,模型线上部署引入缓存机制,将高频Query的相关性得分写入缓存。后续调用时会优先读取缓存,若命中缓存则直接输出打分,未命中缓存的则进行线上实时计算。缓存机制大大节省了计算资源,有效缓解在线计算的性能压力。
对未命中缓存的Query,将其处理为Query侧模型输入,通过图4所述的流程获取每个POI的匹配字段摘要,并处理为POI侧模型输入格式,再调用线上相关性模型输出相关分。相关性模型部署在TF-Serving上,在模型预测时,采用美团机器学习平台的模型优化工具ART框架(基于Faster-Transformer[15]改进)进行加速,在保证精度的同时极大地提高了模型预测速度。
3.3.2 应用链路性能优化

图9 相关性模型在点评搜索链路中的应用
相关性模型在搜索链路中的应用如上图9所示,通过引入前置黄金规则、将相关性计算与核心排序层并行化来优化整体搜索链路中的性能。
为了进一步对相关性调用链路加速,我们引入了前置黄金规则对Query分流,对部分Query通过规则直接输出相关分,从而缓解模型计算压力。在黄金规则层中利用文本匹配特征对Query和POI进行判断,例如,若搜索词跟商户名完全一致,则通过黄金规则层直接输出“相关”的判定,而无需通过相关性模型计算相关分。
在整体计算链路中,相关性计算过程与核心排序层进行并发操作,以保证相关性计算对搜索链路的整体耗时基本无影响。在应用层,相关性计算被用在搜索链路的召回和排序等多个环节。为降低搜索列表的首屏不相关商户占比,我们将相关分引入到LTR多目标融合排序中进行列表页排序,并采用多路召回融合策略,利用相关性模型的结果,仅将补充召回路中的相关商户融合到列表中。
4. 应用实战
4.1 离线效果
为精准反映模型迭代的离线效果,我们通过多轮人工标注方式构造了一批Benchmark,考虑到当前线上实际使用时主要目标为降低BadCase指标,即对不相关商户的准确识别,我们采用负例的准确率、召回率、F1值作为衡量指标。经过两阶段训练、样本构造及模型迭代带来的收益如下表1所示:

表1 点评搜索相关性模型迭代离线指标
初始方法(Base)采用Query拼接POI匹配字段摘要信息的BERT句对分类任务,Query侧模型输入采用用户输入的原始Query,POI侧采用商户名、商户类目及匹配字段摘要文本拼接方式。引入基于点击数据的两阶段训练后,负例F1指标相比Base方法提升1.84%,通过引入对比样本、难例样本持续迭代训练样本并配合第二阶段的模型输入构造,负例F1相比Base显著提升10.35%,引入基于多相似矩阵的深度交互方法后,负例F1相比Base提升11.14%。模型在Benchmark上的整体指标也达到了AUC为0.96,F1为0.97的高值。
4.2 线上效果
为有效衡量用户搜索满意度,点评搜索每天对线上实际流量进行抽样并人工标注,采用列表页首屏BadCase率作为相关性模型效果评估的核心指标。相关性模型上线后,点评搜索的月平均BadCase率指标相比上线前显著下降了2.9pp(Percentage Point,百分比绝对点),并在后续几周BadCase率指标稳定在低点附近,同时,搜索列表页的NDCG指标稳定提升2pp。可以看出相关性模型可以有效识别不相关商户,显著降低了搜索的首屏不相关性问题占比,从而提升了用户的搜索体验。
下图10列举了部分线上BadCase解决示例,小标题是该示例对应的Query,左边为应用了相关性模型的实验组,右边为对照组。图10(a)中当搜索词为“佩姐”时,相关性模型将商户核心词包含“佩姐”的商户“佩姐名品”判断为相关,并将用户可能想找但输错的高质目标商户“珮姐老火锅”也判断为相关,同时,通过引入地址字段标识,将地址中位于“珮姐”旁边的商户判断为不相关;图10(b)中用户通过Query“柚子日料自助”想找一家名为“柚子”的日料自助店,相关性模型将拆词匹配到有柚子相关商品售卖的日料自助店“竹若金枪鱼”正确判断为不相关并将其排序靠后,保证展示在靠前的均为更符合用户主要需求的商户。

(a) 佩姐
 (b) 柚子日料自助图10 线上BadCase解决示例
(b) 柚子日料自助图10 线上BadCase解决示例
5. 总结与展望
本文介绍了大众点评搜索相关性模型的技术方案及应用实战。为了更好地构造商户侧模型输入信息,我们引入了实时抽取商户匹配字段摘要文本的方法来构造商户表征作为模型输入;为了优化模型来更好地适配点评搜索相关性计算,使用了两阶段训练的方式,采用基于点击和人工标注数据的两阶段训练方案来有效利用大众点评的用户点击数据,并根据相关性计算的特点提出了基于多相似矩阵的深度交互结构,进一步提升相关性模型的效果;为缓解相关性模型的线上计算压力,在线上部署时引入缓存机制和TF-Serving预测加速,引入黄金规则层对Query分流,将相关性计算与核心排序层并行化,从而满足了线上实时计算BERT的性能要求。通过将相关性模型应用在搜索链路各环节,显著降低了不相关问题占比,有效改善了用户的搜索体验。
目前,点评搜索相关性模型在模型表现及线上应用上仍有提升空间,在模型结构方面,我们将探索更多领域先验知识的引入方式,例如识别Query中实体类型的多任务学习、融入外部知识优化模型的输入等;在实际应用方面,将进一步细化为更多档位,以满足用户对于精细化找店的需求。我们还会尝试将相关性的能力应用到非商户模块中,优化整个搜索列表的搜索体验。
6. 作者简介
校娅*、沈元*、朱迪、汤彪、张弓等,均来自美团/点评事业部搜索技术中心。*为本文共同一作。