一、简介
1.1 RocketMQ 简介
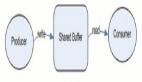
RocketMQ是由阿里巴巴开源的分布式消息中间件,支持顺序消息、定时消息、自定义过滤器、负载均衡、pull/push消息等功能。RocketMQ主要由 Producer、Broker、Consumer 、NameServer四部分组成,其中Producer 负责生产消息,Consumer 负责消费消息,Broker 负责存储消息。NameServer充当名字路由服务,整体架构图如下所示:

roducer:负责生产消息,一般由业务系统生产消息,可通过集群方式部署。RocketMQ提供多种发送方式,同步发送、异步发送、顺序发送、单向发送。同步和异步方式均需要Broker返回确认信息,单向发送不需要。
Consumer:负责消费消息,一般是后台系统负责异步消费,可通过集群方式部署。一个消息消费者会从Broker服务器拉取消息、并将其提供给应用程序。提供pull/push两者消费模式。
Broker Server:负责存储消息、转发消息。RocketMQ系统中负责接收从生产者发送来的消息并存储、同时为消费者的拉取请求作准备,存储消息相关的元数据,包括消费者组、消费进度偏移和主题和队列消息等。
Name Server:名字服务,充当路由消息的提供者。生产者或消费者能够通过名字服务查找各主题相应的Broker IP列表。多个NameServer实例组成集群,相互独立,没有信息交换。
本文基于Apache RocketMQ 最新版本主要讲述RocketMQ的消费者机制,分析其启动流程、pull/push机制,消息ack机制以及定时消息和顺序消息的不同。
1.2 工作流程
(1)启动NameServer。
NameServer起来后监听端口,等待Broker、Producer、Consumer连上来,相当于一个路由控制中心。
(2)启动Broker。
跟所有的NameServer保持长连接,定时发送心跳包。心跳包中包含当前Broker信息(IP+端口等)以及存储所有Topic信息。注册成功后,NameServer集群中就有Topic跟Broker的映射关系。
(3)创建Topic。
创建Topic时需要指定该Topic要存储在哪些Broker上,也可以在发送消息时自动创建Topic。
(4)Producer发送消息。
启动时先跟NameServer集群中的其中一台建立长连接,并从NameServer中获取当前发送的Topic存在哪些Broker上,轮询从队列列表中选择一个队列,然后与队列所在的Broker建立长连接从而向Broker发消息。
(5)Consumer消费消息。
跟其中一台NameServer建立长连接,获取当前订阅Topic存在哪些Broker上,然后直接跟Broker建立连接通道,开始消费消息。
二、消费者启动流程
官方给出的消费者实现代码如下所示:
public class Consumer {
public static void main(String[] args) throws InterruptedException, MQClientException {
// 实例化消费者
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("TestConsumer");
// 设置NameServer的地址
consumer.setNamesrvAddr("localhost:9876");
// 订阅一个Topic,以及Tag来过滤需要消费的消息
consumer.subscribe("Test", "*");
// 注册回调实现类来处理从broker拉取回来的消息
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
// 标记该消息已经被成功消费
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
// 启动消费者实例
consumer.start();
System.out.printf("Consumer Started.%n");
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
下面让我们来分析消费者在启动中每一阶段中做了什么吧,let’s go.
2.1 实例化消费者
第一步主要是实例化消费者,这里采取默认的Push消费者模式,构造器中参数为对应的消费者分组,指定同一分组可以消费同一类型的消息,如果没有指定,将会采取默认的分组模式,这里实例化了一个DefaultMQPushConsumerImpl对象,它是后面消费功能的主要实现类。
// 实例化消费者
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("TestConsumer");- 1.
- 2.
主要通过DefaultMQPushConsumer实例化DefaultMQPushConsumerImpl,它是主要的消费功能实现类。
public DefaultMQPushConsumer(final String consumerGroup, RPCHook rpcHook,
AllocateMessageQueueStrategy allocateMessageQueueStrategy) {
this.consumerGroup = consumerGroup;
this.allocateMessageQueueStrategy = allocateMessageQueueStrategy;
defaultMQPushConsumerImpl = new DefaultMQPushConsumerImpl(this, rpcHook);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
2.2 设置NameServer和订阅topic过程
// 设置NameServer的地址
consumer.setNamesrvAddr("localhost:9876");
// 订阅一个或者多个Topic,以及Tag来过滤需要消费的消息
consumer.subscribe("Test", "*");- 1.
- 2.
- 3.
- 4.
2.2.1 添加tag
设置NameServer地址后,这个地址为你名字服务集群的地址,类似于zookeeper集群地址,样例给出的是单机本地地址,搭建集群后,可以设置为集群地址,接下来我们需要订阅一个主题topic下的消息,设置对应的topic,可以进行分类,通过设置不同的tag来实现,但目前只支持"||"进行连接,如:"tag1 || tag2 || tag3"。归根在于构造订阅数据时,源码通过"||"进行了字符串的分割,如下所示:
public static SubscriptionData buildSubscriptionData(final String consumerGroup, String topic,
String subString) throws Exception {
SubscriptionData subscriptionData = new SubscriptionData();
subscriptionData.setTopic(topic);
subscriptionData.setSubString(subString);
if (null == subString || subString.equals(SubscriptionData.SUB_ALL) || subString.length() == 0) {
subscriptionData.setSubString(SubscriptionData.SUB_ALL);
} else {
String[] tags = subString.split("\\|\\|");
if (tags.length > 0) {
for (String tag : tags) {
if (tag.length() > 0) {
String trimString = tag.trim();
if (trimString.length() > 0) {
subscriptionData.getTagsSet().add(trimString);
subscriptionData.getCodeSet().add(trimString.hashCode());
}
}
}
} else {
throw new Exception("subString split error");
}
}
return subscriptionData;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
2.2.2 发送心跳至Broker
前面构造好订阅主题和分类后,将其放入了一个ConcurrentMap中,并调用
sendHeartbeatToAllBrokerWithLock()方法,进行心跳检测和上传过滤器类至broker集群(生产者启动过程也会进行此步骤)。如下所示:
public void sendHeartbeatToAllBrokerWithLock() {
if (this.lockHeartbeat.tryLock()) {
try {
this.sendHeartbeatToAllBroker();
this.uploadFilterClassSource();
} catch (final Exception e) {
log.error("sendHeartbeatToAllBroker exception", e);
} finally {
this.lockHeartbeat.unlock();
}
} else {
log.warn("lock heartBeat, but failed.");
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
首先会对broker集群进行心跳检测,在此过程中会施加锁,它会执行sendHeartbeatToAllBroker方法,构建心跳数据heartbeatData,然后遍历消费和生产者table,将消费者和生产者信息加入到heartbeatData中,当都存在消费者和生产者的情况下,会遍历brokerAddrTable,往每个broker 地址发送心跳,相当于往对应地址发送一次http请求,用于探测当前broker是否存活。
this.mQClientAPIImpl.sendHearbeat(addr, heartbeatData, 3000);- 1.
2.2.3上传过滤器类至FilterServer
之后会执行uploadFilterClassSource()方法,只有push模式才会有此过程,在此模式下,它会循环遍历订阅数据SubscriptionData,如果此订阅数据使用了类模式过滤,会调用uploadFilterClassToAllFilterServer()方法:上传用户自定义的过滤消息实现类至过滤器服务器。
private void uploadFilterClassSource() {
Iterator<Entry<String, MQConsumerInner>> it = this.consumerTable.entrySet().iterator();
while (it.hasNext()) {
Entry<String, MQConsumerInner> next = it.next();
MQConsumerInner consumer = next.getValue();
if (ConsumeType.CONSUME_PASSIVELY == consumer.consumeType()) {
Set<SubscriptionData> subscriptions = consumer.subscriptions();
for (SubscriptionData sub : subscriptions) {
if (sub.isClassFilterMode() && sub.getFilterClassSource() != null) {
final String consumerGroup = consumer.groupName();
final String className = sub.getSubString();
final String topic = sub.getTopic();
final String filterClassSource = sub.getFilterClassSource();
try {
this.uploadFilterClassToAllFilterServer(consumerGroup, className, topic, filterClassSource);
} catch (Exception e) {
log.error("uploadFilterClassToAllFilterServer Exception", e);
}
}
}
}
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
过滤器类的作用:消费端可以上传一个Class类文件到 FilterServer,Consumer从FilterServer拉取消息时,FilterServer会把请求转发给Broker,FilterServer收取到Broker消息后,根据上传的过滤类中的逻辑做过滤操作,过滤完成后再把消息给到Consumer,用户可以自定义过滤消息的实现类。
2.3 注册回调实现类
接下来就是代码中的注册回调实现类了,当然,如果你是pull模式的话就不需要实现它了,push模式需要定义,两者区别后面会讲到,它主要用于从broker实时获取消息,这里有两种消费上下文类型,用于不同的消费类型。
ConsumeConcurrentlyContext:延时类消息上下文,用于延时消息,即定时消息,默认不延迟,可以设置延迟等级,每个等级对应固定时间刻度,RocketMQ中不能自定义延迟时间,延迟等级从1开始,对应的时间间隔如下所示:
"1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";- 1.
ConsumeOrderlyContext :顺序类消息上下文,控制发送消息的顺序,生产者设置分片路由规则后,相同key只落到指定queue上,消费过程中会对顺序消息所在的queue加锁,保证消息的有序性。
2.4 消费者启动
我们先来看下消费者启动的过程,如下所示:

(1)this.checkConfig():首先是检测消费配置项,包括消费分组group、消息模型(集群、广播)、订阅数据、消息监听器等是否存在,如果不存在的话,会抛出异常。
(2)copySubscription():构建主题订阅信息SubscriptionData并加入到RebalanceImpl负载均衡方法的订阅信息中。
(3)getAndCreateMQClientInstance():初始化MQ客户端实例。
(4)offsetStore.load():根据不同消息模式创建消费进度offsetStore并加载:BROADCASTING-广播模式,同一个消费group中的consumer都消费一次,CLUSTERING-集群模式,默认方式,只被消费一次。
switch (this.defaultMQPushConsumer.getMessageModel()) {
case BROADCASTING:
this.offsetStore = new LocalFileOffsetStore(this.mQClientFactory, this.defaultMQPushConsumer.getConsumerGroup());
break;
case CLUSTERING:
this.offsetStore = new RemoteBrokerOffsetStore(this.mQClientFactory, this.defaultMQPushConsumer.getConsumerGroup());
break;
default:
break;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
可以通过setMessageModel方式设置不同模式;广播模式下同消费组的消费者相互独立,消费进度在本地单独进行存储;集群模式下,同一条消息只会被同一个消费组消费一次,消费进度会参与到负载均衡中,消费进度是共享在整个消费组中的。
(5)consumeMessageService.start():根据不同消息监听类型实例化并启动。这里有延时消息和顺序消息。
这里主要讲下顺序消息,RocketMQ也帮我们实现了,在启动时,如果是集群模式并是顺序类型,它会启动定时任务,定时向broker发送批量锁,锁住当前顺序消费发往的消息队列,顺序消息因为生产者生产消息时指定了分片策略和消息上下文,只会发往一个消费队列。
定时任务发送批量锁,锁住当前顺序消息队列。
public void start() {
if (MessageModel.CLUSTERING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())) {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
ConsumeMessageOrderlyService.this.lockMQPeriodically();
}
}, 1000 * 1, ProcessQueue.REBALANCE_LOCK_INTERVAL, TimeUnit.MILLISECONDS);
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
发送锁住队列的消息至broker,broker端返回锁住成功的队列集合lockOKMQSet,顺序消息具体实现可查看后面第四节。
(6)mQClientFactory.registerConsumer():MQClientInstance注册消费者,并启动MQClientInstance,没有注册成功会结束消费服务。
(7)mQClientFactory.start():最后会启动如下服务:远程客户端、定时任务、pull消息服务、负载均衡服务、push消息服务,然后将状态改为运行中。
switch (this.serviceState) {
case CREATE_JUST:
this.serviceState = ServiceState.START_FAILED;
// If not specified,looking address from name server
if (null == this.clientConfig.getNamesrvAddr()) {
this.mQClientAPIImpl.fetchNameServerAddr();
}
// Start request-response channel
this.mQClientAPIImpl.start();
// Start various schedule tasks
this.startScheduledTask();
// Start pull service
this.pullMessageService.start();
// Start rebalance service
this.rebalanceService.start();
// Start push service
this.defaultMQProducer.getDefaultMQProducerImpl().start(false);
log.info("the client factory [{}] start OK", this.clientId);
this.serviceState = ServiceState.RUNNING;
break;
case RUNNING:
break;
case SHUTDOWN_ALREADY:
break;
case START_FAILED:
throw new MQClientException("The Factory object[" + this.getClientId() + "] has been created before, and failed.", null);
default:
break;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
全部启动完毕后,整个消费者也就启动好了,接下来就可以对生产者发送过来的消息进行消费了,那么是如何进行消息消费的呢?不同的消息模式有何区别呢?
三、pull/push 模式消费

3.1 pull模式-DefaultMQPullConsumer
pull拉取式消费:应用通常主动调用Consumer的拉消息方法从Broker服务器拉消息、主动权由应用程序控制,可以指定消费的位移,【伪代码】如下所示:
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("TestConsumer");
// 设置NameServer的地址
consumer.setNamesrvAddr("localhost:9876");
// 启动消费者实例
consumer.start();
//获取主题下所有的消息队列,这里根据主题从nameserver获取的
Set<MessageQueue> mqs = consumer.fetchSubscribeMessageQueues("Test");
for (MessageQueue queue : mqs) {
//获取当前队列的消费位移,指定消费进度offset,fromstore:从broker中获取还是本地获取,true-broker
long offset = consumer.fetchConsumeOffset(queue, true);
PullResult pullResult = null;
while (offset < pullResult.getMaxOffset()) {
//第二个参数为tag,获取指定topic下的tag
//第三个参数表示从哪个位移下开始消费消息
//第四个参数表示一次最大拉取多少个消息
try {
pullResult = consumer.pullBlockIfNotFound(queue, "*", offset, 32);
} catch (Exception e) {
e.printStackTrace();
System.out.println("pull拉取消息失败");
}
//代码省略,记录消息位移
offset = pullResult.getNextBeginOffset();
//代码省略,这里为消费消息
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
可以看到我们是主动拉取topic对应下的消息队列,然后遍历它们,获取当前消费进度并进行消费。
3.2 push模式-DefaultMQPushConsumer
该模式下Broker收到数据后会主动推送给消费端,该消费模式一般实时性较高,现在一般推荐使用该方式,具体示例可以观看第一章开头的官方demo。
它也是通过实现pull方式来实现的,首先,前面2.4消费者启动之后,最后会启动拉取消息服务pullMessageService和负载均衡rebalanceService服务,它们启动后会一直有线程进行消费。
case CREATE_JUST:
//......
// Start pull service
this.pullMessageService.start();
// Start rebalance service
this.rebalanceService.start();
//.......
this.serviceState = ServiceState.RUNNING;
break;
case RUNNING:- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
这里面调用doRebalance()方法,进行负载均衡,默认每20s做一次,会轮询所有订阅该实例的topic。
public class RebalanceService extends ServiceThread {
//初始化,省略....
@Override
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
this.waitForRunning(waitInterval);
//做负载均衡
this.mqClientFactory.doRebalance();
}
log.info(this.getServiceName() + " service end");
}
@Override
public String getServiceName() {
return RebalanceService.class.getSimpleName();
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
然后根据每个topic,以及它是否顺序消息模式来做rebalance。
具体做法就是先对Topic下的消息消费队列、消费者Id进行排序,然后用消息队列的平均分配算法,计算出待拉取的消息队列,将分配到的消息队列集合与processQueueTable做一个过滤比对,新队列不包含或已过期,则进行移除 。
public void doRebalance(final boolean isOrder) {
Map<String, SubscriptionData> subTable = this.getSubscriptionInner();
if (subTable != null) {
for (final Map.Entry<String, SubscriptionData> entry : subTable.entrySet()) {
final String topic = entry.getKey();
try {
/根据 /每个topic,以及它是否顺序消息模式来做rebalance
this.rebalanceByTopic(topic, isOrder);
} catch (Throwable e) {
if (!topic.startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {
log.warn("rebalanceByTopic Exception", e);
}
}
}
}
this.truncateMessageQueueNotMyTopic();
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
rebalanceByTopic中广播和集群模式都会执行updateProcessQueueTableInRebalance()方法,最后会分发请求dispatchPullRequest,通过executePullRequestImmediately()方法将pull请求放入pull请求队列pullRequestQueue中,注意,pull模式下分发请求方法dispatchPullRequest()实际实现是一个空方法,这里两者很大不同,push模式实现如下:
@Override
public void dispatchPullRequest(List<PullRequest> pullRequestList) {
for (PullRequest pullRequest : pullRequestList) {
this.defaultMQPushConsumerImpl.executePullRequestImmediately(pullRequest);
log.info("doRebalance, {}, add a new pull request {}", consumerGroup, pullRequest);
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
然后再PullMessageService中,因为前面consumer启动成功了,PullMessageService线程会实时去取pullRequestQueue中的pull请求。
@Override
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
PullRequest pullRequest = this.pullRequestQueue.take();
if (pullRequest != null) {
this.pullMessage(pullRequest);
}
} catch (InterruptedException e) {
} catch (Exception e) {
log.error("Pull Message Service Run Method exception", e);
}
}
log.info(this.getServiceName() + " service end");
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
取出来的pull请求又会经由DefaultMQPushConsumerImpl的消息监听类,调用pullMessage()方法。
private void pullMessage(final PullRequest pullRequest) {
final MQConsumerInner consumer = this.mQClientFactory.selectConsumer(pullRequest.getConsumerGroup());
if (consumer != null) {
DefaultMQPushConsumerImpl impl = (DefaultMQPushConsumerImpl) consumer;
impl.pullMessage(pullRequest);
} else {
log.warn("No matched consumer for the PullRequest {}, drop it", pullRequest);
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
pullMessage()中pullKernelImpl()有一个Pullback方法用于执行消息的回调,它会通过submitConsumeRequest()这个方法来处理消息,总而言之就是通过线程回调的方式让push模式下的监听器能够感知到。
//Pull回调
PullCallback pullCallback = new PullCallback() {
@Override
public void onSuccess(PullResult pullResult) {
if (pullResult != null) {
pullResult = DefaultMQPushConsumerImpl.this.pullAPIWrapper.processPullResult(pullRequest.getMessageQueue(), pullResult,
subscriptionData);
switch (pullResult.getPullStatus()) {
case FOUND:
//省略...消费位移更新
DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(
pullResult.getMsgFoundList(),
processQueue,
pullRequest.getMessageQueue(),
dispathToConsume);- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
这个方法对应的不同消费模式有着不同实现,但都是会构建一个消费请求ConsumeRequest,里面有一个run()方法,构建完毕后,会把它放入到listener监听器中。
//监听消息
status = listener.consumeMessage(Collections.unmodifiableList(msgs), context);- 1.
- 2.
还记得前面我们样例给出的注册监听器回调处理方法吗?
我们可以点击上面的consumeMessage方法,查看它在源码中的实现位置,发现它就回到了我们前面的2.3注册回调实现类里面了,整个流程是不是通顺了呢?这个监听器中就会收到push的消息,拉取出来进行业务消费逻辑,下面是我们自己定义的消息回调处理方法。
// 注册回调实现类来处理从broker拉取回来的消息
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
// 标记该消息已经被成功消费
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
3.3 小结
push模式相比较于pull模式不同的是,做负载均衡时,pullRequest请求会放入pullRequestQueue,然后PullMessageService线程会实时去取出这个请求,将消息存入ProcessQueue,通过线程回调的方式让push模式下的监听器能够感知到,这样消息从分发请求到接收都是实时的,而pull模式是消费端主动去拉取指定消息的,需要指定消费进度。
对于我们开发者来说,选取哪种模式实现我们的业务逻辑比较合适呢?别急,先让我们总结下他们的特点:
共同点:
- 两者底层实际一样,push模式也是基于pull模式来实现的。
- pull模式需要我们通过程序主动通过consumer向broker拉消息,而消息的push模式则只需要我们提供一个listener监听,实时获取消息。
优点:
- push模式采用长轮询阻塞的方式获取消息,实时性非常高;
- push模式rocketMQ处理了获取消息的细节,使用起来比较简单方便;
- pull模式可以指定消费进度,想消费多少就消费多少,灵活性大。
缺点:
- push模式当消费者能力远远低于生产者能力的时候,会产生一定的消费者消息堆积;
- pull模式实时性很低,频率不好设置;
- 拉取消息的间隔不好设置,太短则产生很多无效Pull请求的RPC开销,影响MQ整体的网络性能,太长则实时性差。
适用场景:
- 对于服务端生产消息数据比较大时,而消费端处理比较复杂,消费能力相对较低时,这种情况就适用pull模式;
- 对于数据实时性要求高的场景,就比较适用与push模式。
现在的你是否明确业务中该使用哪种模式了呢?
四、顺序消息
4.1 实现MQ顺序消息发送存在问题
- 一般消息发送会采取轮询方式把消息发送到不同的queue(分区队列);而消费消息的时候从多个queue上拉取消息,broker之间是无感知的,这种情况发送和消费是不能保证顺序。
- 异步方式发送消息时,发送的时候不是按着一条一条顺序发送的,保证不了消息到达Broker的时间也是按照发送的顺序来的。
消息发送到存储,最后到消费要经历这么多步骤,我们该如何在业务中使用顺序消息呢?让咱们来一步步拆解下吧。
4.2 实现MQ顺序消息关键点
既然分散到多个broker上无法追踪顺序,那么可以控制发送的顺序消息只依次发送到同一个queue中,消费的时候只从这个queue上依次拉取,则就保证了顺序。在发送时设置分片路由规则,让相同key的消息只落到指定queue上,然后消费过程中对顺序消息所在的queue加锁,保证消息的有序性,让这个queue上的消息就按照FIFO顺序来进行消费。因此我们满足以下三个条件是否就可以呢?
1)消息顺序发送:多线程发送的消息无法保证有序性,因此,需要业务方在发送时,针对同一个业务编号(如同一笔订单)的消息需要保证在一个线程内顺序发送,在上一个消息发送成功后,在进行下一个消息的发送。对应到mq中,消息发送方法就得使用同步发送,异步发送无法保证顺序性。
//采用的同步发送方式,在一个线程内顺序发送,异步发送方式为:producer.send(msg, new SendCallback() {...})
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {//…}- 1.
- 2.
2)消息顺序存储:MQ 的topic下会存在多个queue,要保证消息的顺序存储,同一个业务编号的消息需要被发送到一个queue中。对应到mq中,需要使用MessageQueueSelector来选择要发送的queue。即可以对业务编号设置路由规则,像根据队列数量对业务字段hash取余,将消息发送到一个queue中。
//使用"%"操作,使得订单id取余后相同的数据路由到同一个queue中,也可以自定义路由规则
long index = id % mqs.size();
return mqs.get((int) index);- 1.
- 2.
- 3.
3)消息顺序消费:要保证消息顺序消费,同一个queue就只能被一个消费者所消费,因此对broker中消费队列加锁是无法避免的。同一时刻,一个消费队列只能被一个消费者消费,消费者内部,也只能有一个消费线程来消费该队列。这里RocketMQ已经为我们实现好了。
List<PullRequest> pullRequestList = new ArrayList<PullRequest>();
for (MessageQueue mq : mqSet) {
if (!this.processQueueTable.containsKey(mq)) {
if (isOrder && !this.lock(mq)) {
log.warn("doRebalance, {}, add a new mq failed, {}, because lock failed", consumerGroup, mq);
continue;
}
//....省略
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
消费者重新负载,并且分配完消费队列后,需要向mq服务器发起消息拉取请求,代码实现在RebalanceImpl#updateProcessQueueTableInRebalance()中,针对顺序消息的消息拉取,mq做了以上判断,即消费客户端先向broker端发起对messageQueue的加锁请求,只有加锁成功时才创建pullRequest进行消息拉取,这里的pullRequest就是前面pull和push模式消息体,而updateProcessQueueTableInRebalance这个方法也是在前面消费者启动过程中有讲到过哦。
具体加锁逻辑如下:
public boolean lock(final MessageQueue mq) {
FindBrokerResult findBrokerResult = this.mQClientFactory.findBrokerAddressInSubscribe(mq.getBrokerName(), MixAll.MASTER_ID, true);
if (findBrokerResult != null) {
LockBatchRequestBody requestBody = new LockBatchRequestBody();
requestBody.setConsumerGroup(this.consumerGroup);
requestBody.setClientId(this.mQClientFactory.getClientId());
requestBody.getMqSet().add(mq);
try {
Set<MessageQueue> lockedMq =
this.mQClientFactory.getMQClientAPIImpl().lockBatchMQ(findBrokerResult.getBrokerAddr(), requestBody, 1000);
for (MessageQueue mmqq : lockedMq) {
ProcessQueue processQueue = this.processQueueTable.get(mmqq);
if (processQueue != null) {
processQueue.setLocked(true);
processQueue.setLastLockTimestamp(System.currentTimeMillis());
}
}
boolean lockOK = lockedMq.contains(mq);
log.info("the message queue lock {}, {} {}",
lockOK ? "OK" : "Failed",
this.consumerGroup,
mq);
return lockOK;
} catch (Exception e) {
log.error("lockBatchMQ exception, " + mq, e);
}
}
return false;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
可以看到,就是调用lockBatchMQ方法发送了一个加锁请求,成功获取到消息处理队列就设为获取到锁,返回锁定成功,如果加锁成功,同一时刻只有一个线程进行消息消费。加锁失败,会延迟1000ms重新尝试向broker端申请锁定messageQueue,锁定成功后重新提交消费请求。
怎么样,这样的加锁方式是不是很像我们平时用到的分布式锁呢?由你来设计实现你会怎么做呢?
五、消息ack机制
5.1 消息消费失败处理
消息被消费者消费了,那么如何保证被消费成功呢?消息消费失败会出现什么情况呢?
消息被消费,那么如何保证被消费成功呢?这里只有使用方控制,只有使用方确认成功了,才会消费成功,否则会重新投递。
RocketMQ其实是通过ACK机制来对失败消息进行重试和通知的,具体流程如下所示:


消息成功与否是由使用方控制,只有使用方确认成功了,才会消费成功,否则会重新投递,Consumer会通过监听器监听回调过来的消息,返回ConsumeConcurrentlyStatus.CONSUME_SUCCESS表示消费成功,如果消费失败,返回ConsumeConcurrentlyStatus.RECONSUME_LATER状态(消费重试),RocketMQ就会默认为这条消息失败了,延迟一定时间后(默认10s,可配置),会再次投送到ConsumerGroup,重试次数与间隔时间关系上图所示。如果持续这样,失败到一定次数(默认16次),就会进入到DLQ死信队列,不再投递,此时可以通过监控人工来干预。
5.2 消息重投带来问题
RocketMQ 消费消息因为消息重投很大一个问题就是无法保证消息只被消费一次,因此需要开发人员在业务里面自己去处理。

六、总结
本文主要介绍了RocketMQ的消费者启动流程,结合官方源码和示例,一步步讲述消费者在启动和消息消费中的的工作原理及内容,并结合平时业务工作中,对我们所熟悉的顺序、push/pull模式等进行详细分析,以及对于消息消费失败和重投带来问题去进行分析。
对于自己而言,希望通过主动学习源码方式,能够明白其中启动的原理,学习里面优秀的方案,像对于pull/push,顺序消息这些,学习之后能够了解到push模式是何如做到实时拉取消息的,顺序消息是如何保证的,再就是能够联想到平时遇到这种问题该如何处理,像顺序消息在消息被消费时保持和存储的顺序一致,这里自己施加分布式锁写能不能实现等,文中也有很多引导性问题,希望能引起读者自己的思考,能够对整个消费者启动和消息消费流程有着较为直观的认知,但还有着一些技术细节由于篇幅原因没做出详细说明,也欢迎大家一起探讨交流~
参考资料:
- RocketMQ官网示例
- RocketMQ系列之pull(拉)消息模式(七)
- RocketMQ的顺序消息(顺序消费)