分析引擎在为企业提供低延迟和低成本的实时分析方面发挥着至关重要的作用。随着数据规模和多样性爆炸式增长,企业应用要求分析系统具备高并发查询和高吞吐,同时支持对结构化和非结构化数据的查询。
为了满足这些要求,分析引擎和数据库通常依赖于将查询计划编译为本机代码。手动编写算子的方式,如filter,join和group by,通常包含处理不同参数和数据类型所需的控制流。本机代码生成的目的是通过消除不必要的代码并将其专门用于底层平台,从而最大限度地减少指令数量。
然而,上述方案在易用性和硬件兼容性方面往往存在局限性,我们总结为三点:
1. 数据获取:没有有效的方法过滤非必要的数据,大量计算资源被浪费
2. 数据计算:算子通过JAVA、Scala等高级语言实现,无法充分发挥算力;算子优化困难
3. 数据层优化:要解决端到端流程中的问题,各个引擎需要做垂直优化
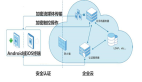
为此,鲲鹏应用使能套件BoostKit中提供了大数据的Runtime底座——OmniRuntime, 通过五个核心组件,如下图所示,实现针对数据接入、传输、计算全周期开展性能优化,提升大数据分析场景的性能提升30%以上。

图. 大数据的Runtime底座——OmniRuntime

图. OmniRuntime核心组件示意图
●OmniJit:一个透明、易于使用的即时编译框架,不需要对任何低级代码生成框架(如LLVM或Janino)的了解。
●OmniVec:一种列式内存格式,提供高性能内存访问、全内存生命周期管理和内置SIMD操作。它还支持所有常用的数据类型,如int、double、varchar和decimal等。
●OmniOperator:native 算子库,充分利用当今异构计算环境中可用硬件的计算能力,与OmniJit结合使用时,能够动态地适应工作负载、参数和数据配置文件,以实现最佳性能。
●OmniCache:一种关系型缓存,性能优于传统的面向块的缓存,命中率极高。
●OmniData:快速数据访问和协作层,提供数据层和计算层之间的双向通信和数据传输。
1 OmniJit
OmniJit组件对分析工作负载的整体性能提高做出了重大贡献。
OmniJit旨在为普通开发人员提供即时编译支持。它提供了一个易于使用的高级语言框架,如C/C++。OmniJit自动识别运算符中最关键的性能代码部分并优化它们。生成的运算符是专门使用查询、运行时和硬件特定的计算机代码的。OmniJit依赖于运行时信息来基于查询上下文应用最佳优化。这可以是数据集基数、列大小、数据类型、可用硬件(SIMD、加速器等)以及许多其他信息,以产生最佳运算符优化。
通过使用OmniJit,分析引擎开发人员将不再需要与LLVM或Janino等系统提供的复杂低级API交互,以提取最佳性能。

图2. OmniJit分支裁剪和循环展开优化
2 OmniOperator
OmniOperator表示处理特定查询数据的计算逻辑代码。SQL查询可以由许多不同的算子组成,OmniJit负责动态优化它们。OmniJit优化了C++算子,以生成具有最小执行指令计数的可执行文件。

算子接口的结构与火山模型相似,因为它遵循类似的接口生命周期:实例化、AddInput、GetOuput和Close。所有OmniOperators都提供相同的标准接口,实现对分析引擎不透明。
通过利用标准接口,我们可以轻松地将这些运算符暴露给上层计算引擎。此外,它还帮助我们提供一致的开发生命周期体验,同时允许跨各种分析平台的可移植性。开发人员可以让OmniJit使用自动化方法优化运算符。或者,他可以指导优化策略,如参数固定、循环开发和代码中特定核心方法的矢量化自适应执行。
与本机平台运算符相比,生成的OmniOperators执行的指令计数更少,资源消耗更低,开发开销也更低。下图显示了Java Analytics平台中的整体OmniOperator生命周期。由于大多数分析引擎都是用Java编码的,我们还提供了一个JNI接口来促进集成。

图3. OmniOperator引擎与Native Operator的交互
3 OmniVector
OmniVector是OmniRuntime的另一个组件。OmniVector定义了标准的列式内存格式。OmniVector设计为可移植的、独立于列的内存数据格式。OmniVector支持丰富的数据类型系统,旨在满足各种分析数据系统的需求。这种内存数据格式为数据密集型应用程序提供高性能和高可扩展性。
OmniVector的核心代码是在C++中实现的,带有高级语言绑定,以实现交叉兼容性。它提供了一个异步接口,允许读取和写入操作由各种组件并行进行。这允许我们在写入或持久化操作被继续时公开OmniVector的内容。
下图显示了OmniVec的整体架构。

图4. OmniVec Binging和Native架构
基于作用域的全生命周期管理的OmniVector不仅消除了内存泄漏的可能性,而且提供了高性能的内存访问。每个OmniVector在其生命周期中都会经历几个步骤。每个步骤都由OmniVctor操作触发:
1. 作用域创建:为了进行有效的内存管理并避免页面故障开销,向量在特定的执行作用域内分配。这允许高效的内存池,从而最大限度地减少内存管理开销。
2. OmniVector分配:通过使用上面创建的范围,开发人员现在可以分配新的向量。
3. OmniVector 修改:API支持Set和Put操作。前者在特定对应的索引位置操作单个值。后者是批处理put方法,在该方法中,数组插入到指定的开始位置。
4. OmniVector读取:与修改一样,我们支持单值检索或批处理操作。
5. OmniVector释放:一旦不使用向量,就可以将其释放到作用域内存池
6. 作用域释放:释放所有向量后,我们可以释放作用域和关联的内存池。
由于此设计,OmniVector支持以下功能:
●零拷贝操作
●支持数据生命周期管理和内存泄漏检测。
●支持复杂的数据结构,如MAP、列表和结构。
●SIMD指令优化和硬件加速接口
●自动溢出到存储
●高性能内存分配和池化。
4 OmniJit、OmniVctor和OmniOperator性能数据
我们在openLooKeng、Spark和Hive等流行的大数据系统中集成了OmniRuntime和OmniJit。然后,我们使用TPC-H在openLooKeng上进行了基准测试,实验结果表明集成了Omniruntime框架的性能明显优于原始分析引擎。

图5. OmniJit优化的算子效果
5 OmniCache
OmniCache是OmniRuntime中的关系型缓存。OmniCache不仅缓存数据,还维护数据与缓存中的数据之间的关系。OmniCache构造虚拟数据集,缓存从物理集数据或其他虚拟数据集派生的关系数据,并使用SQL SELECT语句定义用于缓存的关系数据。
这种方法比传统的基于文件块的缓存系统具有优势。传统缓存系统中整个文件块必须缓存或丢弃,这可能会导致许多数据换入和换出操作,导致缓存命中率非常低。
为了维护关系信息,OmniCache将其状态和结构信息提供给查询优化器,以最大限度地提高命中率。公开的缓存元数据有助于分析引擎优化查询计划,并首先访问缓存中的数据,而不是通过慢速数据存储。此外,缓存还能够存储中间查询结果。它允许通过使查询计划程序直接访问先前计算的数据,而不是执行如图6所示的完整查询计划来加速操作。

图6. OmniCache
Omnicache具备以下功能:
●缓存管理:通过使用物化视图命令生成和管理物化视图。
●SQL重写:SQL重写使用关系代数和成本模型执行,以有效利用缓存数据。
●缓存存储:全局内存池的关系型缓存,基于堆外内存实现,可进行高效的数据存储和访问。
6 OmniData
OmniData是OmniRuntime的快速数据访问和协作层,旨在减少数据存储层和计算层之间的数据传输,这在现代存算分离的数据中心中非常有效。
OmniData不会直接从存储端加载文件,然后处理数据,而是将特定操作卸载到存储端进行近数据处理。目标是减少所需的网络通信量和整体计算量。

OmniData通过将查询执行划分为几个与数据分布匹配的阶段来实现这一目标。然后,代表子处理操作的每个阶段都被发送到存储节点附近或存储节点上执行。亲和性调度用于避免存储节点计算能力过载,并保持较高的整体吞吐量。阶段性操作允许本地数据加载和处理。

图. OmniData实现原理
未来展望
OmniRuntime使用OmniJit、OminVector、OmniOperator、OmniCache和OmniData的组合,为分析平台提供通用的数据处理基础,为不同分析引擎提供具有上下文优化功能的通用引擎,显著减轻创建自定义优化的负担,并支持异构硬件环境。
OmniRuntime持续提供强大的数据处理能力,使数据分析引擎能够满足高并发、高吞吐量、结构化和非结构化查询的业务需求。未来,OmniRuntime将继续聚焦更多的功能实现,如decimal类型支持、UDF框架、表达式优化,以及实现向量化优化等。
欢迎大家登录hikunpeng.com——鲲鹏社区鲲鹏BoostKit专区了解更多关于OmniRuntime的详细信息。