爬虫中很重要的一个点就是JS的逆向破解加密,今天我们来浅析一下。
背景
先简单介绍一下为什么要有JS解密,目前大部分网页都是采用的前后端分离的方式,所以呢,爬虫的一般破解之道都是从后端接口来做文章,进行突破。
不过道高一尺,魔高一丈,网页开发会对API接口请求参数进行加密,来增加爬虫抓取的门槛。为此可以通过js逆向来分析破解加密方式,模拟浏览器发送请求获取接口数据。
当然,先说明,这篇文章并不是非常专业的JS解密,因为JS的解密涉及很多种,多种行为的解密,本文只是对其中一种情况进行简单的介绍。
来吧,让我们一起简单学习一下。

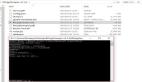
上面这个图是请求翻译的全过程。

我们能清晰的看到这是直接以表单的形式提交的数据到后端API层,然后API来执行翻译的作用。
接下来我们用python模拟以下这个过程。

一定要注意的是,请求头写全,包括cookie和user-agent这些,还有下面的params一定要按照网页中的来。
代码给到大家。
import requests
#请求头
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Content-Length": "255",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "OUTFOX_SEARCH_USER_ID_NCOO=1992896419.125546; OUTFOX_SEARCH_USER_ID=1708647615@10.108.162.133; fanyi-ad-id=306808; fanyi-ad-closed=1; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abcJJxrChyTjz_26EmBgy; ___rl__test__cookies=1656205889631",
"Host": "fanyi.youdao.com",
"Origin": "http://fanyi.youdao.com",
"Referer": "http://fanyi.youdao.com/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
"X-Requested-With": "XMLHttpRequest",
}
#提交参数
params = {
"i": "love you , my baby",
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": "16562058896377",
"sign": "f85458213e7db4207f135599c7ddfac7",
"lts": "1656205889637",
"bv": "bdc0570a34c12469d01bfac66273680d",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME",
}
url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
#发起POST请求
response = requests.post(url=url,headers=headers,data=params).json()
print(response)
一部分是header信息,一部分是params信息
我们可以看到,参数params中除了我们要传递的参数翻译内容之外,还有好多我们不认识的参数,如果这里错了会怎么样呢,随便改一下其中的一个参数,我们看看效果。

可以看到,直接返回错误了,很明显被禁止了,或者说是校验没通过,属于非法请求。
我们再来看一下,只改变翻译的内容,靠这些盐和签名是不是能够成功翻译呢?

结果发现,我们只改变了要翻译的内容,结果还是不行,很明显生成这些校验参数的过程是和要翻译的内容是相关的。
搜索不同的关键词,请求body参数如下,分析发现除了我们要传递的翻译内容外还有4个参数是变量:
"salt": "16562058896377",
"sign": "f85458213e7db4207f135599c7ddfac7",
"lts": "1656205889637",
"bv": "bdc0570a34c12469d01bfac66273680d",
这些就是属于请求盐和校验参数,有对应的加密格式,接下来我们围绕这四个参数来进行破解。
接下来我们打开控制台,打开我们要分析的JS程序,直接ctrl+f全局搜索salt关键字。

找到我们要分析的地方,然后在打上断点,重新请求一遍。
F10往下一步一步的执行。

当执行到如图所示的位置的时候,我们把鼠标移动到r这个对象的位置上去,为什么要看这个对象呢,因为你看下面的salt、sign、lts、bv这些参数都是属于r这个对象的属性。
我们能够看到此时r对象的这几个属性已经被赋予了值了。

接着看看这个r到底是什么。

var r = function(e) {
var t = n.md5(navigator.appVersion)
, r = "" + (new Date).getTime()
, i = r + parseInt(10 * Math.random(), 10);
return {
ts: r,
bv: t,
salt: i,
sign: n.md5("fanyideskweb" + e + i + "Ygy_4c=r#e#4EX^NUGUc5")
}
};
进一步分析发现:
- r:当前的时间戳。
- i:当前的时间戳+(0到10的随机数)。
- salt:salt=i。
- e:搜索关键字。
- sign:md5("fanyideskweb" + e + i + "Ygy_4c=r#e#4EX^NUGUc5")。
至此完成签名算法的实现,接下来可以通过python来实现。

代码如下:
import requests
from hashlib import md5
import time
import random
#请求地址
url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
appVersion = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Content-Length": "244",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "OUTFOX_SEARCH_USER_ID=-1506602845@10.169.0.82; JSESSIONID=aaaUggpd8kfhja1AIJYpx; OUTFOX_SEARCH_USER_ID_NCOO=108436537.92676207; ___rl__test__cookies=1597502296408",
"Host": "fanyi.youdao.com",
"Origin": "http://fanyi.youdao.com",
"Referer": "http://fanyi.youdao.com/",
"user-agent": appVersion,
"X-Requested-With": "XMLHttpRequest",
}
def r(e):
# bv
t = md5(appVersion.encode()).hexdigest()
# lts
r = str(int(time.time() * 1000))
# i
i = r + str(random.randint(0,9))
return {
"ts": r,
"bv": t,
"salt": i,
"sign": md5(("fanyideskweb" + e + i + "Ygy_4c=r#e#4EX^NUGUc5").encode()).hexdigest()
}
def fanyi(word):
data = r(word)
params = {
"i": word,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": data["salt"],
"sign": data["sign"],
"lts": data["ts"],
"bv": data["bv"],
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME",
}
response = requests.post(url=url,headers=headers,data=params)
#返回json数据
return response.json()
if __name__ == "__main__":
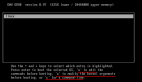
while True:
word = input("请输入要翻译的语句:")
result = fanyi(word)
#对返回的json数据进行提取,提取出我们需要的数据
r_data = result["translateResult"][0]
print(r_data[0]["src"])
print(r_data[0]["tgt"])