












随着企业急于获得边缘所能提供的低延迟、灵活性、成本和性能方面的好处,边缘计算的需求正在急剧扩大。IDC估计,2022年全球在边缘硬件、软件和服务方面的支出将达到1760亿美元,比上一年增长14.8%,到2025年将达到2740亿美元。因此,你的开发者很可能现在就在开发边缘应用,或者在不久的将来会这样做。
然而,在你深入研究之前,有一些事情需要考虑。我作为企业架构师有与开发组织合作的经验,让我告诉你创建边缘应用时的一些教训。牢记这些教训可以帮助你避免走弯路,并确保你充分利用边缘所能提供的优势。

教训1:挑战你的思维方式
很多时候,开发者在创建边缘应用时,就好像它们与数据中心或云端的应用一样。但边缘是一个不同的范式,需要用不同的方法来编写代码,也需要用深思熟虑的方法来选择适合边缘的应用。
大多数开发者习惯于集中式的计算环境,在少量的服务器中拥有大量的计算资源。但是,边缘计算将这种情况翻转过来,相对适度的资源分布在不同地点的许多服务器上。这可能会影响任何一个边缘工作负载的可扩展性。例如,一个使用大量内存的应用程序可能无法在成百上千的边缘实例中很好地扩展。由于这个原因,大多数边缘应用程序将是专门为边缘设计的,而不是从现有的数据中心或云部署中“提升和迁移”。
你需要认真思考边缘架构如何影响你的应用,以及哪些应用将从这种分布式方法中受益。把逻辑带到数据所在的地方通常更容易。因此,如果数据更加区域化,或者需要访问大型集中式数据存储,基于云的方法可能是合理的。但是,当一个应用程序使用在边缘产生的数据时--例如来自在线用户的请求/响应、cookies和头信息--这就是边缘计算真正可以大放异彩之处。
教训2:不要忽视基础知识
虽然将代码分布到边缘可以改善延迟和可扩展性,但它不会神奇地运行得更快。低效的代码在边缘也会同样低效。如前所述,边缘的每个存在点都会比典型的集中式计算环境受到更多的资源限制,特别是在无服务器的边缘环境中。在为边缘编写代码时,优化效率对于充分利用这种架构至关重要。
当向边缘推送功能相对快速和容易时,你仍然需要向管理其它代码那样应用勤奋的管理流程。这包括良好的变更管理流程,将代码存储在源代码控制中,并使用代码审查来评估代码质量。
教训3:重新思考可扩展性
在边缘,你是在“扩大”而不是“增加”。因此,你需要开发代码以适应每个请求的约束,而不是从每个服务器的约束角度考虑。这包括对内存用量、CPU周期和每次请求时间的约束。制约因素会因你所使用的边缘平台而不同,所以了解它们并相应地设计你的代码很重要。
一般来说,你想用每个操作所需的最小数据集来操作。例如,如果你在边缘做A/B测试,你只想存储你正在操作的特定请求或页面所需的数据子集,而不是整个规则集。对于基于位置的体验,你只需要在一个轻量级的查询中保存该边缘实例所服务的特定州或地区的数据,而不是所有地区的数据。
教训4:为可靠性编码
确保边缘应用程序的可靠性对于提供积极的用户体验是绝对必要的。请确保在你的QA计划中包括测试边缘代码。添加适当的错误处理也很重要,以确保你的代码能够优雅地处理错误,包括计划和测试事件发生时的回退行为。例如,如果你的代码超出了平台的限制,要创建一个回退到一些默认的内容,这样用户就不会收到一个影响他们体验的错误信息。
进行分布式负载测试是一个很好的做法,可以确认你的应用程序的可扩展性。一旦你部署了代码,就继续监测平台,以确保不超过CPU和内存的限制,并跟踪任何错误。
教训5:优化性能
边缘计算的主要好处是通过将数据和计算资源移至用户附近而大幅减少延迟。当你在成百上千个存在点(PoPs)上进行扩展时,创建轻量级、高效的代码对于实现这一好处至关重要。完成一个功能所需的数据也应该在边缘。开发需要从集中式数据存储中获取数据的代码会抹去边缘提供的延迟优势。
对高效执行的强调同样适用于边缘应用所利用的任何第三方代码。一些现有的代码库是低效的,损害了性能或超过了边缘平台的CPU和内存限制。因此,在将任何代码纳入边缘部署之前,要仔细评估它。
教训6:不要重复造轮子
虽然边缘是一种新的模式,但这并不意味着你必须从头开始编写一切。大多数边缘平台都与各种内容分发网络(CDN)功能集成,允许你创建自定义逻辑,生成一个输出信号,提示现有的CDN功能,如缓存。
把你的代码设计成可重用的也是一个好主意,这样它既可以在边缘也可以在集中的计算环境中执行。将核心功能抽象为不依赖浏览器、Node.JS或特定平台功能的库,可以使代码具有“同构性”,能够在客户端、服务器和边缘运行。
使用现有的开源库是避免重写通用功能的另一种方式。但要注意那些需要Node.JS或浏览器功能的库。并考虑与你正在使用的边缘平台集成的第三方开发商合作,这可以节省时间和精力,同时提供成熟的互操作性优势。
将这些经验付诸实践
为了说明这些最佳实践的影响,请考虑一个真实的案例:一个组织在边缘实施地理围栏应用时遇到了困难。他们遇到了因超过平台的CPU和内存限制而导致的高错误率问题。
看看他们是如何建立自己的应用程序的,他们有所有地理围栏区域的数据,900KB的JSON,存储在每个边缘PoP中。使用一个CPU密集型算法来检查每个地理围栏的兴趣点,当在检查前几个区域没有找到兴趣点时,就会触发CPU超时。
为了解决这个问题,每个地理围栏区域的数据被转移到一个键值存储(KVS)中,每个区域存储在一个单独的条目中。增加了一个轻量级的检查,以确定一个兴趣点的可能的“候选区域”(通常是1到3个候选区域)。完整的数据和CPU密集型检查只在候选区域进行,极大地减少了CPU的工作量。这些变化将错误率降低到可忽略的水平,同时改善了初始化时间并减少了内存的使用,如下图所示。
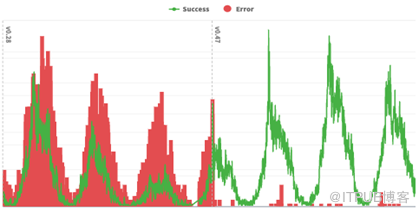
图1:成功率和错误率的前后对比(注意,成功和错误指标的尺度不同,因此不能直接比较)。
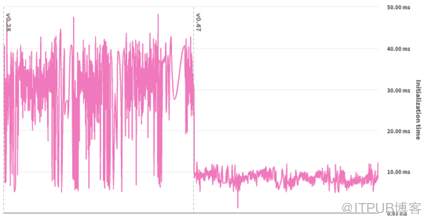
图2:初始化时间的前后比较
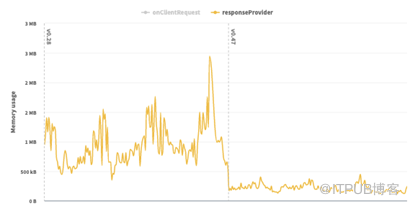
图3:之前和之后的内存使用情况比较(图片来源:Akamai)
充分发挥边缘的作用
边缘计算为贴近用户、快速高效地提供个性化用户体验的应用程序提供了巨大的优势。成功的关键是确保应用程序是一个很好的边缘平台候选者,然后优化你的代码,以充分利用边缘平台的功能,同时在其限制条件下工作。
请注意我在与组织合作中所学到的经验教训,你可以以更快的速度获得边缘的优势,且没有令人头疼的问题。















