Tubes是一套面向C端搭建场景,支持灵活扩展、极致性能和高稳定性的终端渲染解决方案,目前广泛运用在淘宝、天猫,包括:双11、618会场、淘宝新人版首页等业务场景。
介绍
响应性数据系统指的是程序在使用系统提供的数据的同时会自动订阅自己所使用的数据,被订阅的数据发生变化时使用了(订阅了)这个数据的程序会对数据的变化做出响应。
响应性是 Vue.js 最具特色的特性(之前叫响应式,Vue3给翻译成响应性,我认为响应性这个词整挺好),不过 Tubes 的响应性原理和 Vue.js 略有不同。
响应性数据系统在Tubes中发挥的作用
Tubes 为什么需要响应性数据系统,这来源于一个重要的业务问题:“如何解决会场分屏渲染问题”,站在技术视角要解决的问题是:“Tube多次执行的设计问题”。
正在读文章的你可能不了解Tubes体系,不清楚什么是Tube,没关系,你可以把问题想象成:如何解决 Express.js 的中间件多次执行、如何解决 Webpack 的Loader多次执行。
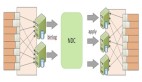
分屏渲染指的是在搭建体系中,产出的页面会先渲染首屏的模块,再渲染次屏模块。在Tubes体系中,从第一个Tube开始执行,执行到最后一个Tube则完成一次渲染(这与 Express.js 的中间件机制有点类似,一个请求进来从第一个 Middleware 开始执行,执行到最后一个Middleware结束),如下图所示:

从第一个Tube执行到最后一个Tube则完成一次模块的渲染。在会场分屏渲染的场景下,通常第一轮执行完毕表示完成了首屏模块的渲染。那么想要渲染次屏模块,只需要再执行一轮Tube就可以将次屏模块渲染出来。那么问题来了,Tube多次执行的机制如何设计比较优雅?
我们设计了两种方案:“方案一:基于循环系统实现”、“方案二:基于响应性数据系统实现”。下面我们对比下两个方案的区别:
▐ 方案一:基于循环系统实现
基于循环系统,Tube可以一圈一圈执行。第一圈渲染时,Tube开发者可以在内部调用API通知 Tubes-Engine 本轮执行完后还需要再执行一轮。通过这样的机制,实现第一圈渲染首屏模块,第二圈渲染次屏模块。
这里的问题是由于并不是所有Tube都需要执行多次,因此 Tubes-Engine 需要为Tube提供一些属性和方法(例如:当前执行的圈数、once方法等)方便 Tube 根据 “圈数” 做一些逻辑、或者使用 once 声明自己只需要在第一轮执行一次,后面的其他轮次不参与执行。
其实只有和“首屏”、“次屏”渲染逻辑强相关的Tube需要多次执行(举个例子:env tube的逻辑是初始化一些环境信息,比如是否是Android或者iOS,PC还是Mobile,这个逻辑只需要在第一轮执行时执行一次就可以),在基于循环系统的实现下,不需要多次执行的Tube就需要开发者明确声明这个Tube只需要执行一次(就是说,如果开发者判断自己的Tube只需要执行一次,那么他需要为这个Tube做一些额外的处理)。
现在我们总结下这个方案的优缺点:
优点: Tubes-Engine内部实现简单(意味着不容易出错)
缺点:
1.Tube开发者需深入理解Tube运行机制(轮圈制)以及背后为什么设计成“轮圈制”
2.每个Tube,都需要处理轮圈制相关的逻辑,例如:
只需要执行一次的Tube:需要使用once声明自己只需要执行一次
需要执行多次的Tube:需要根据圈数来判断本轮做什么事情,以及是否需要再来下一轮并调用API通知 Tubes-Engine 再执行一轮。
这个方案很直观,可以解决问题。但也可以看出,该方案对Tube开发者来说使用成本很高,无论Tube是否需要多次执行,开发者都需要深入理解背后的轮圈原理并对自己开发的Tube做相应的判断(是否需要多次执行)和处理。
▐ 方案二:基于响应性数据系统实现
设计之初,Tube的本质就是一个具备 “幂等性” 的执行单元(函数),它的一面是输入,另一面是输出,前一个Tube的输出是下一个Tube的输入,多个Tube组合在一起完成页面渲染。
Tube是用于处理渲染的执行单元(函数),Tubes 的设计理念是利用若干简单的执行单元(Tube)让计算结果不断渐进,逐层推导复杂的运算,而不是设计一个复杂的执行过程。—— Tubes官网
具备 “幂等性” 意味着,输入相同的情况下,输出一定相同。也就是说输入不变的情况下,输出也没有变化,因此没有必要让其重新执行。只有输入变了,才意味着输出会变,这时候就需要重新执行Tube使其重新计算并输出新的结果。
方案的关键思路是“根据输入输出的变化来决定哪个Tube应该再次执行”,而实现这个能力的关键技术就是“响应性数据系统”。
因此,基于响应性数据系统指的是:只有某个Tube所使用的数据发生“变化”时,才重新“按序”执行Tube。“按序”执行是指如果多个Tube都使用了同一个数据,且该数据发生了变化,那么这些 Tube 按照Tube的编排顺序执行。
例如:渲染了首屏后,“数据Tube”请求了次屏数据并将次屏数据也放入了Store中,那么这个放入数据的操作,就会触发一个数据的 update,那么此时使用了该数据的Tube会再次执行,且只有使用了该数据的Tube会再次执行。再次执行的Tube或许又会修改数据,依赖这个数据的后续Tube又会加入到“执行队列”中再次执行,以此实现一条 “基于依赖的执行链” 即:前一个 Tube 修改了数据并写入响应性数据系统,后面读取了这份数据的 Tube 会被再次执行并将重新计算后的新数据写入响应性数据系统,而这个写入行为又会再次触发后面的其他 Tube 执行,直到完成最终渲染。
现在我们总结下这个方案的优缺点:
- 优点:
没有对Tube增加额外负担(无新增方法、无新增属性、无需Tube内部配合Tubes-Engine实现流程控制)
Tube对首屏次屏场景下的多次执行无感知
只执行需要执行的Tube(而不是先执行,再由中间件内部判断是否跳过)
- 缺点: 内部实现复杂(意味着容易出错)
基于响应性数据系统,可以很智能的“挑选”出哪些Tube应该被执行,该方案对Tube开发者没有任何额外负担,而且它只执行需要执行的Tube,执行效率上也更好。最终,我们选择了使用响应性数据系统。

 响应性数据系统的设计与原理
响应性数据系统的设计与原理
历史上,为了将性能优化到极致,Tubes 的响应性数据系统的实现原理共设计了三个版本,由于第二个版本是第一个版本的改良版,因此本节为您详细介绍第二个版本和第三个版本的实现原理。
▐ 经典实现
当我们研究响应性数据系统的原理时,本质上我们在研究三件事:响应性数据、收集依赖、触发依赖。

- 响应性数据
响应性数据最关键的两个核心是:监听器、依赖存储。
监听器
所谓的监听器指的是我们采用什么样的方式拦截用户对数据的操作,主流的实现方式有以下几种:
- Getter / Setter
- Proxy
- 自定义 Set/Get API
Tubes 采用第三种方式实现,原因是 Tube 开发者希望可以在原始数据中修改数据且不触发响应性,例如:
const data = this.store.get('data'); // 希望只在这里绑定依赖关系
const name = data.name; // 希望这个操作不触发Getter
data.name = name + '!'; // 希望这个操作不触发Setter
this.store.set('data', data); // 希望执行到这行代码时再统一触发响应性
Tube 开发者希望自由控制什么时候触发响应性,在这种场景下 Tubes 采用了自定义API的方式拦截用户对数据的操作。
依赖存储
当监听器拦截到用户对某个数据进行操作后,需要找到这个数据对应的“依赖”,如何找到数据对应的“依赖”主要看“依赖”如何存储,实现方式有很多种,传统的实现方式比如Vue2是直接将“依赖”存在数据身上,找到了数据也就找到了这个数据对应的“依赖”,不得不说这很方便,Tubes最初也是这样实现的,如下图所示:

如上图所示,依赖都保存在 __dep__ 这个属性中,而这个属性则直接保存在数据中。
- 收集依赖
关于依赖收集,本质上我们要解决的问题是“什么时候收集”、“收集谁”、“如何收集”、“收集到哪里”等问题。
什么时候收集
什么时候收集?答案是:“读取数据的时候收集依赖”。当监听器拦截到读取数据时,就可以开始进行依赖收集了。
收集谁
收集谁?回答这个问题似乎不那么简单,事实上这个问题没有标准答案。如果用发布&订阅者模式来理解,那么我们收集的是“订阅者”,当数据发生变化时我们要通知给订阅了这个数据的“订阅者”,但订阅者是谁?这取决于我们具体的需求,也就是我们希望使用响应性数据系统做什么事。
在 Tubes 中,我们希望响应性数据系统能帮助我们将需要再次执行的 Tube 挑选出来,那么我们的“订阅者”就是Tube,一旦数据发生变化,就能找到这个数据的依赖(也就是 Tube),随后就可以将这些 Tube 发送到调度系统中去执行。
在 Vue.js 中,希望响应性数据系统能帮助将需要重新渲染的组件挑选出来,那么这个时候订阅者就是组件,数据发生变化后,能找到数据的依赖(也就是组件),随后用新数据重新渲染组件。
实际上,Tubes 中的订阅者并不是 Tube,因为 Tube 需要支持并行执行,如果并行执行的 Tube 同时使用了某个数据,那么在收集他们的时候需要保持好并行Tube的数据结构,因此在 Tubes 内部,并行执行的 Tube 为一组,订阅者其实是这个小组。也就是先把 Tube 添加到这个小组,然后再把这个小组添加到依赖列表中。假设并行执行的 Tube 只有其中一个使用了某个数据,那么这个数据的订阅者就是一个小组,然后这个小组里面只有一个 Tube,如果并行执行的 Tube 有多个使用了某个数据,那么这个小组里面就有多个 Tube。
如何收集
现在我们已经知道了“什么时候收集”、“收集谁”以及“收集到哪里”,下面详细介绍一下怎么收集,我们用一个例子来说明:
const data = ctx.store.get('a.d');
在 Tubes 中,由于同一时间只有一个 Tube 在执行,而且不存在嵌套关系,因此定位哪个 Tube 中执行了 ctx.store.get 并不困难,伪代码如下:
function get(keypath) {
this.ctx.tb.store.effect = effect;
this.ctx.tb.store.tube = tube;
const res = this.ctx.tb.store.get(keypath);
this.ctx.tb.store.tube = null;
this.ctx.tb.store.effect = null;
return res;
}
上面伪代码展示了当用户调用 this.store.get 时,如何定位当前正在执行的 Tube 和 Tube 所属的那个组(effect)。
收集到哪里
前面讲响应性数据的时候我们讲依赖是直接存在数据上的,因为这样方便修改数据的时候找到该数据对应的依赖,但只将依赖保存在被修改的数据身上是不够的。
试想一个场景,Tube A 使用了数据 a.d,这时候相当于订阅了 a.d 这个数据,现在另一个 Tube 修改了数据 a,或者数据 a.d.x 那么此时 Tube A要不要响应?答案是:要!
因此,我们得到一个结论:依赖不只是保存到目标数据身上,还要保存到目标数据的所有父级和所有子级中,如下图所示:

上图红色圈表示需要被订阅的数据,绿色圈表示依赖保存的位置,右侧表示当 Tube 读取 a.d 时,需要同时订阅 a、a.d、a.d.e和a.d.f。
这里有一个细节,图中绿色圈比我们要订阅的数据高一个层级,这是因为数据的最底部会出现基本类型的数据,而基本类型的数据是无法挂载额外属性的,因此我们选择将每个数据的依赖都保存在父级节点中。
- 读取依赖
触发依赖的时机是 “修改数据的时候” ,当监听器拦截到用户修改数据时,将对应数据的依赖找到就可以了。在 Tubes 中,依赖被找到后会发送给调度系统执行。
▐ 基于哈希表的响应性数据系统
这种实现方式的原理和核心思想与传统方式没有太大区别,本质上我们仍在研究三件事:响应性数据、收集依赖、触发依赖。
顾名思义,这种实现方式最大的特点是使用哈希表来存储依赖,如下图所示:

- 为什么使用哈希表存储依赖
使用哈希表来存储依赖和将依赖直接保存在数据身上的主要区别在于操作依赖的 “速度”。
前面我们讲收集依赖的时候除了要将依赖保存在当前读取的那个数据之外还需要将依赖保存在所有父级和所有子级中。将依赖保存在所有父级中并不怎么影响性能,但将依赖保存到所有子级,这需要遍历到每一个子级和子级的子级,如果数据非常大,那么这个遍历的过程将非常耗时,在低端机尤其明显。
使用哈希表来存储依赖,操作依赖的速度则不受数据大小的影响,存储依赖不再需要遍历数据的每个子级,无论是保存依赖还是读取依赖都不受数据量大小的影响,可以在一瞬间完成。
下面我们详细介绍使用哈希表如何存储和读取依赖。
- 存储依赖
使用哈希表存储依赖非常简单,只需要使用 keypath 作为 Key,值是一个列表,将依赖追加到列表中即可。这里需要注意去重的逻辑,避免将同一个依赖重复添加到列表中。一图胜千言:

如上图所示,当用户执行 ctx.store.get('a.d') 时,直接使用 a.d 作为哈希表中的KEY将依赖追加到列表中,逻辑简单且执行效率高。
值得注意的是哈希表中还使用一个列表保存了依赖对应的ID,这用于避免将重复的依赖追加到列表中。
- 读取依赖
使用哈希表存储依赖时,如何读取某个数据对应的依赖?
这是个好问题,当依赖保存在数据上面时,读取数据时只要找到了数据,就找到了数据对应的依赖,逻辑非常简单高效。而使用哈希表存储依赖由于依赖并不保存在数据身上,所以找到了数据并不等于找到了依赖,因此我们需要一段额外的逻辑来拿到数据对应的依赖。
我们先回顾下前面的逻辑,前面我们讲当 Tube 读取 a.d 时,需要同时订阅 a、a.d、a.d.e和a.d.f。

也就是说,当我们修改了某个数据时,除了该数据外,该数据的所有父级以及所有子级都需要做出响应,现在这个逻辑仍然适用。因此,不难得出,当我们修改 a.d 时,我们需要在哈希表中将 a、a.d、a.d.* 的依赖取出来,其中 a、为父级,a.d为数据本身,a.d.*为所有子级,如下图所示:

值得注意的是,同一个KEY下面的依赖会去重, 但不同KEY之间有可能有重复的依赖,为了避免重复响应,取出来的数据需要做一个去重处理。
- 性能提升
经过验证,相比于传统实现,使用哈希表来存储依赖在低端机的性能提升尤其明显。在维持写入速度不变的情况下,提升读取数据的速度 “1,349.8” 倍,在业务中的表现是会场的首屏速度提升452.6ms,以下是详细数据:
- 读取速度:提升了1,349.8倍,Android低端机由64.79ms(10次平均值)降低为0.048ms(10次平均值)。
- 写入速度:维持现有速度不变
- 时间复杂度:旧算法会随着数据量大小而“增加写入时长”,而新算法写入速度始终保持在 0ms ~ 0.2ms 区间
- 旧算法:读取数据为O(N)
- 新算法:读取数据为O(1)
- 对会场首屏速度的影响 (新旧算法渲染10次取平均数):提升452.6ms
- 旧算法:2,924.7ms
- 新算法:1,917.5ms
- 测试环境:低端机
- 设备:红米7
- 系统:Android 9
- 页面:活动中心页面

小结
基于哈希表的响应性数据系统和传统实现在本质上没有区别,区别在于存储依赖的方式,不同的存储依赖的方式决定了存储和读取依赖的算法不同,不同的算法决定了执行效率。
总结
本文详细介绍了响应性数据系统在 Tubes 中的运用,以及响应性数据系统的三种不同设计与原理,遗憾的是,该项目目前只针对阿里内部开源,但一些技术思路仍可以供您学习与参考。