文章的动机是避开源代码的中间表示,将源代码表示为图像,直接提取代码的语义信息以改进缺陷预测的性能。
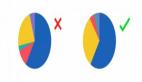
首先,看到如下图所示的motivation示例。File1.java和File2.java两个示例中,虽然都包含了1个if语句、2个for语句和4个函数调用,但代码的语义和结构特征是不相同的。为验证将源代码转换成图像是否有助于区分不同的代码,作者进行了实验:将源代码根据字符的ASCII十进制数对应到像素,排列成像素矩阵,获取源代码的图像。作者指出,不同的源代码图像存在差异。

Fig. 1 Motivation Example
文章主要的贡献如下:
将代码转换成图像,从中提取语义和结构信息;
提出一种端到端的框架,结合自注意力机制和迁移学习实现缺陷预测。
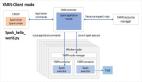
文章提出的模型框架如图2所示,分为两个阶段:源代码可视化和深度迁移学习建模。
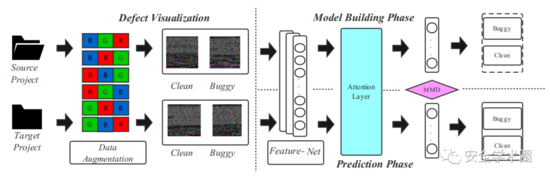
Fig. 2 Framework
1.源代码可视化
文章将源代码转换成6个图像,过程如图3所示。将源代码字符的10进制ASCII码转换成8bit无符号整数向量,按行和列对这些向量进行排列,生成图像矩阵。8bit整数直接对应到灰度等级。为解决原始数据集较小的问题,作者在文章中提出了一种基于颜色增强的数据集扩充方法:对R、G、B三个颜色通道的值进行排列组合,产生6个彩色图。这里看着挺迷的,变换了通道值后,语义和结构信息应该有所改变吧?但是作者在脚注上进行了解释,如图4所示。
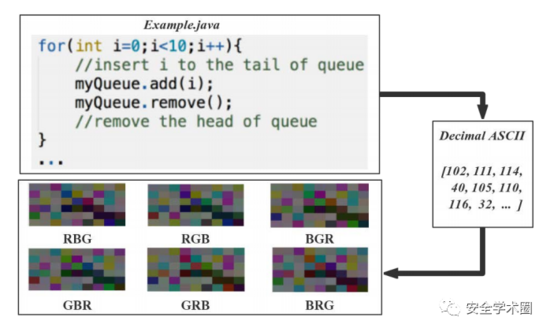
Fig. 3 源代码可视化流程

Fig. 4 文章脚注2
2.深度迁移学习建模
文章使用DAN网络来捕获源代码的语义和结构信息。为增强模型对重要信息的表达能力,作者在原始DAN结构中加入了Attention层。训练与测试流程如图5所示,其中conv1-conv5来自于AlexNet,4个全连接层fc6-fc9作为分类器。作者提到,对于一个新的项目,训练深度学习模型需要有大量的标签数据,这是困难的。所以,作者首先在ImageNet 2012上训练了一个预训练模型,使用预训练模型的参数作为初始参数来微调所有卷积层,进而减少代码图像和ImageNet 2012中图像的差异。
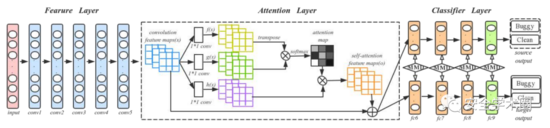
Fig. 5 训练与测试流程
3.模型训练和预测
对Source项目中有标签的代码和Target项目中无标签的代码生成代码图像,同时送入模型;二者共享卷积层和Attention层来提取各自的特征。在全连接层计算Source和Target之间的MK-MDD(Multi Kernel Variant Maximum Mean Discrepancy)。由于Target没有标签,所以只对Source计算交叉熵。模型使用mini-batch随机梯度下降沿着损失函数训练模型。对每一个<source, target>对的500个epoch,根据最好的F-measure从中选出一个epoch。
在实验部分,作者选择了PROMISE数据仓库中所有开源的Java项目,收集了它们的版本号、class name、是否存在bug的标签。根据版本号和class name在github中下载源码。最终,共采集了10个Java项目的数据。数据集结构如图6所示。
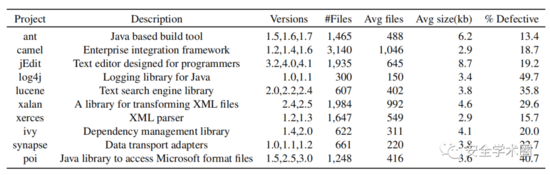
Fig. 6 数据集结构
对于项目内缺陷预测,文章选择如下baseline模型进行对比:

对于跨项目缺陷预测,文章选择如下baseline模型进行对比:

总结一下,虽然是两年前的论文了,但感觉思路还是比较新奇的,避开AST等一系列代码中间表示,直接将代码转换成图像提取特征。但是还是比较疑惑,代码转换成的图像真的包含源代码语义和结构信息吗?感觉可解释性不太强,哈哈。后面需要做实验分析下吧。