译者 | 陈峻
审校 | 孙淑娟
鉴于图像分类在机器学习中的实际应用价值,本文将使用Fashion MNIST案例进行图像分类。其中,我们会将图像存储在SingleStore DB数据库中,使用Keras和Tensorflow来构建图像分类模型,并将预测结果存储在SingleStore DB中。最后,我们将使用Streamlit为数据库系统构建一个快速的可视化前端,使我们能够检索图像,并确定模型能否正确地识别它。文中使用到的SQL脚本、Python代码和notebook文件(包含DBC、HTML和iPython格式),都可以在GitHub上获得。
基本介绍
由于Fashion MNIST数据集被内置在Keras中,因此我们能够直接使用该数据集。正因为图像数据与模型预测一起存储在数据库系统中,我们可以创建独立于应用程序、且无需重新加载的原始数据集。
首先,我们需要在SingleStore网站上创建一个免费的Cloud帐户,并在Databricks网站上创建一个免费的CommunityEdition(CE)帐户。在撰写本文时,SingleStore的云帐户售价为500美元。而对于Databricks CE而言,我们需要的是注册免费帐户,而不是试用版。
接着,我们可以通过准备如下三个方面,来配置Databricks CE:
- Databricks Runtime版本9.1 LTSML
- 适用于Spark 3.1的SingleStore Spark Connector的最高版本
- MariaDB的Java客户端2.7.4 jar文件
创建数据库表
让我们在SingleStore Cloud帐户中,使用SQL编辑器创建一个新的数据库--ml:
SQL
CREATE DATABASE IF NOT EXISTS ml;- 1.
- 2.
接着我们通过如下代码,创建tf_images、img_use、categories、prediction_results四张表:
SQL
USE ml;
CREATE TABLE tf_images (
img_idx INT(10) UNSIGNED NOT NULL,
img_label TINYINT(4),
img_vector BLOB,
img_use TINYINT(4),
KEY(img_idx)
);
CREATE TABLE img_use (
use_id TINYINT(4) NOT NULL,
use_name VARCHAR(10) NOT NULL,
use_desc VARCHAR(100) NOT NULL,
PRIMARY KEY(use_id)
);
CREATE TABLE categories (
class_idx TINYINT(4) NOT NULL,
class_name VARCHAR(20) DEFAULT NULL,
PRIMARY KEY(class_idx)
);
CREATE TABLE prediction_results (
img_idx INT UNSIGNED NOT NULL,
img_label TINYINT(4),
img_use TINYINT(4),
t_shirt_top FLOAT,
trouser FLOAT,
pullover FLOAT,
dress FLOAT,
coat FLOAT,
sandal FLOAT,
shirt FLOAT,
sneaker FLOAT,
bag FLOAT,
ankle_boot FLOAT,
KEY(img_idx)
);- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
我们简单介绍一下上述四张表:
- tf_images用于以BLOB格式存储图像。同时,它还可以存储每个图像的标签ID,以表示是用于训练还是测试。
- img_use是一个由两行组成的简单表。其两行分别表示训练或测试,每一行都有一个简短的描述。
- categories包含数据集中十个不同的时装物品的名称。
- prediction_results包含了各种模型预测。
下面让我们通过如下SQL代码,从img_use和categories开始:
SQL
USE ml;
INSERT INTO img_use VALUES
(1, "Training", "The image is used for training the model"),
(2, "Testing", "The image is used for testing the model");
INSERT INTO categories VALUES
(0, "t_shirt_top"),
(1, "trouser"),
(2, "pullover"),
(3, "dress"),
(4, "coat"),
(5, "sandal"),
(6, "shirt"),
(7, "sneaker"),
(8, "bag"),
(9, "ankle_boot");- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
填写notebook
首先,让我们创建一个新的Databricks CE版的Python notebook。在此,我们将其称为Fashion MNIST的数据加载器,以便将新的notebook附加到Spark集群中。下面是设置环境的代码:
Python
from tensorflow import keras
from keras.datasets import fashion_mnist
import matplotlib.pyplot as plt
import numpy as np- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
加载数据集
接下来,我们将获取用于训练和测试的数据:
Python
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()- 1.
- 2.
我们可以打印出各种数据的形状:
Python
print("train_images: " + str(train_images.shape))
print("train_labels: " + str(train_labels.shape))
print("test_images: " + str(test_images.shape))
print("test_labels: " + str(test_labels.shape))- 1.
- 2.
- 3.
- 4.
- 5.
其结果应类似如下内容:
纯文本
train_images: (60000, 28, 28)
train_labels: (60000,)
test_images: (10000, 28, 28)
test_labels: (10000,)- 1.
- 2.
- 3.
- 4.
- 5.
至此,我们有了60,000张用于训练的图像、以及10,000张用于测试的图像。这些图像是灰度的,大小为28像素x28像素。让我们来查看其中一张:
Python
print(train_images[0])- 1.
- 2.
其结果如下(28列x28行):
纯文本
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 13 73 0 0 1 4 0 0 0 0 1 1 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 0 36 136 127 62 54 0 0 0 1 3 4 0 0 3]
[ 0 0 0 0 0 0 0 0 0 0 0 0 6 0 102 204 176 134 144 123 23 0 0 0 0 12 10 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 155 236 207 178 107 156 161 109 64 23 77 130 72 15]
[ 0 0 0 0 0 0 0 0 0 0 0 1 0 69 207 223 218 216 216 163 127 121 122 146 141 88 172 66]
[ 0 0 0 0 0 0 0 0 0 1 1 1 0 200 232 232 233 229 223 223 215 213 164 127 123 196 229 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 183 225 216 223 228 235 227 224 222 224 221 223 245 173 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 193 228 218 213 198 180 212 210 211 213 223 220 243 202 0]
[ 0 0 0 0 0 0 0 0 0 1 3 0 12 219 220 212 218 192 169 227 208 218 224 212 226 197 209 52]
[ 0 0 0 0 0 0 0 0 0 0 6 0 99 244 222 220 218 203 198 221 215 213 222 220 245 119 167 56]
[ 0 0 0 0 0 0 0 0 0 4 0 0 55 236 228 230 228 240 232 213 218 223 234 217 217 209 92 0]
[ 0 0 1 4 6 7 2 0 0 0 0 0 237 226 217 223 222 219 222 221 216 223 229 215 218 255 77 0]
[ 0 3 0 0 0 0 0 0 0 62 145 204 228 207 213 221 218 208 211 218 224 223 219 215 224 244 159 0]
[ 0 0 0 0 18 44 82 107 189 228 220 222 217 226 200 205 211 230 224 234 176 188 250 248 233 238 215 0]
[ 0 57 187 208 224 221 224 208 204 214 208 209 200 159 245 193 206 223 255 255 221 234 221 211 220 232 246 0]
[ 3 202 228 224 221 211 211 214 205 205 205 220 240 80 150 255 229 221 188 154 191 210 204 209 222 228 225 0]
[ 98 233 198 210 222 229 229 234 249 220 194 215 217 241 65 73 106 117 168 219 221 215 217 223 223 224 229 29]
[ 75 204 212 204 193 205 211 225 216 185 197 206 198 213 240 195 227 245 239 223 218 212 209 222 220 221 230 67]
[ 48 203 183 194 213 197 185 190 194 192 202 214 219 221 220 236 225 216 199 206 186 181 177 172 181 205 206 115]
[ 0 122 219 193 179 171 183 196 204 210 213 207 211 210 200 196 194 191 195 191 198 192 176 156 167 177 210 92]
[ 0 0 74 189 212 191 175 172 175 181 185 188 189 188 193 198 204 209 210 210 211 188 188 194 192 216 170 0]
[ 2 0 0 0 66 200 222 237 239 242 246 243 244 221 220 193 191 179 182 182 181 176 166 168 99 58 0 0]
[ 0 0 0 0 0 0 0 40 61 44 72 41 35 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
我们可以通过打印,来检查与该图像关联的标签:
Python
print(train_labels[0])- 1.
- 2.
其结果为:
纯文本
9- 1.
- 2.
该数值代表了Ankle Boot(短靴)。
我们可以使用如下代码,做出一个快速绘图:
Python
classes = [
"t_shirt_top",
"trouser",
"pullover",
"dress",
"coat",
"sandal",
"shirt",
"sneaker",
"bag",
"ankle_boot"
]
num_classes = len(classes)
for i in range(num_classes):
ax = plt.subplot(2, 5, i + 1)
plt.imshow(
np.column_stack(train_images[i].reshape(1, 28, 28)),
cmap = plt.cm.binary
)
plt.axis("off")
ax.set_title(classes[train_labels[i]])- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
其结果如下图所示:

图1:时尚MNIST
为tf_images准备Spark DataFrame
为了重塑数据集以便在后期能够正确地存储,我们将通过如下方式,创建两个临时Numpy数组:
Python
train_images_saved = train_images.reshape((train_images.shape[0], -1))
test_images_saved = test_images.reshape((test_images.shape[0], -1))- 1.
- 2.
- 3.
我们可以通过打印,来检查其形状:
Python
print("train_images_saved: " + str(train_images_saved.shape))
print("test_images_saved: " + str(test_images_saved.shape))- 1.
- 2.
- 3.
其结果为:
Python
train_images_saved: (60000, 784)
test_images_saved: (10000, 784)- 1.
- 2.
- 3.
由于我们已经扁平化了图像的结构,因此接下来需要设置训练值和测试值,以匹配存储在img_useuse_id表中的列值:
Python
train_code = 1
test_code = 2- 1.
- 2.
- 3.
现在我们将通过如下代码,创建两个列表来匹配tf_images表的结构:
Python
train_data = [
(i,
train_images_saved[i].astype(int).tolist(),
int(train_labels[i]),
train_code,
) for i in range(len(train_labels))
]
test_data = [
(i,
test_images_saved[i].astype(int).tolist(),
int(test_labels[i]),
test_code
) for i in range(len(test_labels))
]- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
同时,我们可以通过如下代码,定义自己的模式(schema),并创建两个Spark DataFrame:
Python
from pyspark.sql.types import *
schema = StructType([
StructField("img_idx", IntegerType(), True),
StructField("img", ArrayType(IntegerType()), True),
StructField("img_label", IntegerType(), True),
StructField("img_use", IntegerType(), True)
])
train_df = spark.createDataFrame(train_data, schema)
test_df = spark.createDataFrame(test_data, schema)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
现在我们将通过如下代码,连接两个DataFrame:
Python
tf_images_df = train_df.union(test_df)- 1.
- 2.
下面,让我们通过显示几个数值,来检查DataFrame的结构:
Python
tf_images_df.show(5)- 1.
- 2.
其结果应类似如下信息:
纯文本
+-------+--------------------+---------+-------+
|img_idx| img|img_label|img_use|
+-------+--------------------+---------+-------+
| 0|[0, 0, 0, 0, 0, 0...| 9| 1|
| 1|[0, 0, 0, 0, 0, 1...| 0| 1|
| 2|[0, 0, 0, 0, 0, 0...| 0| 1|
| 3|[0, 0, 0, 0, 0, 0...| 3| 1|
| 4|[0, 0, 0, 0, 0, 0...| 0| 1|
+-------+--------------------+---------+-------+
only showing top 5 rows- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
为了将img列中的数值转换为适合SingleStore DB的格式,我们可以使用以下UDF函数来实现:
Python
import array, binascii
def vector_to_hex(vector):
vector_bytes = bytes(array.array("I", vector))
vector_hex = binascii.hexlify(vector_bytes)
vector_string = str(vector_hex.decode())
return vector_string
vector_to_hex = udf(vector_to_hex, StringType())
spark.udf.register("vector_to_hex", vector_to_hex)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
我们可以按照如下方式应用该UDF:
Python
tf_images_df = tf_images_df.withColumn(
"img_vector",
vector_to_hex("img")
)- 1.
- 2.
- 3.
- 4.
- 5.
同时,我们通过如下代码,来再次检查DataFrame的结构:
Python
tf_images_df.show(5)- 1.
- 2.
其结果应类似如下内容:
纯文本
+-------+--------------------+---------+-------+-------------------+
|img_idx| img|img_label|img_use| img_vector|
+-------+--------------------+---------+-------+-------------------+
| 0|[0, 0, 0, 0, 0, 0...| 9| 1|0000000000000000...|
| 1|[0, 0, 0, 0, 0, 1...| 0| 1|0000000000000000...|
| 2|[0, 0, 0, 0, 0, 0...| 0| 1|0000000000000000...|
| 3|[0, 0, 0, 0, 0, 0...| 3| 1|0000000000000000...|
| 4|[0, 0, 0, 0, 0, 0...| 0| 1|0000000000000000...|
+-------+--------------------+---------+-------+-------------------+
only showing top 5 rows- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
现在,我们可以删除img列了:
Python
tf_images_df = tf_images_df.drop("img")- 1.
- 2.
创建模型
至此,我们已准备好处理原始训练和测试数据。首先,我们通过如下代码,在0和1之间缩放数值:
Python
train_images = train_images / 255.0
test_images = test_images / 255.0- 1.
- 2.
- 3.
接下来,我们将构建自己的模型:
Python
model = keras.Sequential(layers = [
keras.layers.Flatten(input_shape = (28, 28)),
keras.layers.Dense(128, activation = "relu"),
keras.layers.Dense(10, activation = "softmax")
])
model.compile(optimizer = "adam",
loss = "sparse_categorical_crossentropy",
metrics = ["accuracy"]
)
model.summary()- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
其结果应类似如下内容:
纯文本
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 128) 100480
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770 Trainable params: 101,770 Non-trainable
params: 0- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
现在,我们将此模型应用于训练数据:
Python
history = model.fit(train_images,
train_labels,
batch_size = 60,
epochs = 10,
validation_split = 0.2,
verbose = 2)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
其结果应类似如下内容:
纯文本
Epoch 1/10
800/800 - 4s - loss: 0.5326 - accuracy: 0.8149 - val_loss: 0.4358 - val_accuracy: 0.8503
Epoch 2/10
800/800 - 3s - loss: 0.4029 - accuracy: 0.8577 - val_loss: 0.3818 - val_accuracy: 0.8627
Epoch 3/10
800/800 - 3s - loss: 0.3600 - accuracy: 0.8702 - val_loss: 0.3740 - val_accuracy: 0.8683
Epoch 4/10
800/800 - 3s - loss: 0.3325 - accuracy: 0.8782 - val_loss: 0.3863 - val_accuracy: 0.8578
Epoch 5/10
800/800 - 3s - loss: 0.3137 - accuracy: 0.8861 - val_loss: 0.3603 - val_accuracy: 0.8686
Epoch 6/10
800/800 - 3s - loss: 0.2988 - accuracy: 0.8917 - val_loss: 0.3415 - val_accuracy: 0.8748
Epoch 7/10
800/800 - 3s - loss: 0.2836 - accuracy: 0.8962 - val_loss: 0.3270 - val_accuracy: 0.8837
Epoch 8/10
800/800 - 3s - loss: 0.2719 - accuracy: 0.9010 - val_loss: 0.3669 - val_accuracy: 0.8748
Epoch 9/10
800/800 - 3s - loss: 0.2612 - accuracy: 0.9034 - val_loss: 0.3311 - val_accuracy: 0.8806
Epoch 10/10
800/800 - 3s - loss: 0.2527 - accuracy: 0.9072 - val_loss: 0.3143 - val_accuracy: 0.8892- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
我们可以看到模型的精确度随着时间的推移而提高,我们可以据此创建一个图:
Python
plt.title("Model Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.plot(history.history["accuracy"])
plt.plot(history.history["val_accuracy"])
plt.legend(["Train", "Validation"])
plt.show()- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
其结果应类似如下图表:

图2:模型精确度
同时,我们也可以绘制出模型的损耗(Model Loss):
Python
plt.title("Model Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.legend(["Train", "Validation"])
plt.show()- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
其结果应类似如下图表:

图3:模型损耗
再通过如下代码,测试数据的准确性:
Python
(loss, accuracy) = model.evaluate(test_images, test_labels, verbose = 2)- 1.
- 2.
其结果应类似如下内容:
纯文本
313/313 - 1s - loss: 0.3441 - accuracy: 0.8804- 1.
- 2.
让我们使用该模型进行预测,并查看其中的一组预测:
Python
predictions = model.predict(test_images)
print(predictions[0])- 1.
- 2.
- 3.
- 4.
其结果应类似如下内容:
纯文本
[1.4662313e-06 3.3972729e-08 2.6234572e-06 3.2284215e-06
2.3253973e-05 1.0144556e-02 4.5736870e-05 1.1021643e-01
1.2890605e-05 8.7954974e-01]- 1.
- 2.
- 3.
- 4.
我们可以创建一个混淆矩阵(Confusion Matrix)来获得更多的洞见。
首先,我们将通过如下代码,来创建分类值:
Python
from sklearn.metrics import confusion_matrix
from keras.utils import np_utils
cm = confusion_matrix(
np.argmax(np_utils.to_categorical(test_labels, num_classes), axis = 1),
np.argmax(predictions, axis = 1)
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
接下来,我们采用Plotly和Stack Overflow上提及的解决方案:
Python
import plotly.graph_objects as go
data = go.Heatmap(
z = cm[::-1],
x = classes,
y = classes[::-1].copy(),
colorscale = "Reds"
)
annotations = []
thresh = cm.max() / 2
for i, row in enumerate(cm):
for j, value in enumerate(row):
annotations.append(
{
"x" : classes[j],
"y" : classes[i],
"font" : {"color" : "white" if value > thresh else "black"},
"text" : str(value),
"xref" : "x1",
"yref" : "y1",
"showarrow" : False
}
)
layout = {
"title" : "Confusion Matrix",
"xaxis" : {"title" : "Predicted"},
"yaxis" : {"title" : "True"},
"annotations" : annotations
}
fig = go.Figure(data = data, layout = layout)
fig.show()- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
其结果应类似如下内容:
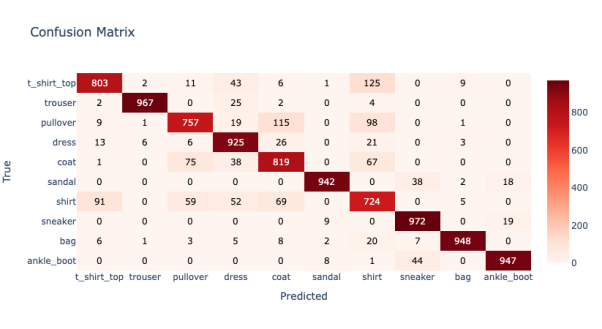
图4:混淆矩阵
我们可以看到,由于诸如:Shirts(衬衫)和T-Shirts(T恤)等项看起来非常相似,因此该模型对于某些时尚单品的准确性是比较低的。
同时,我们也可以绘制出精准率和召回率。其中精准率可以通过如下代码来实现:
Python
import plotly.express as px
from sklearn.metrics import precision_score
precision_scores = precision_score(
np.argmax(np_utils.to_categorical(test_labels, num_classes), axis = 1),
np.argmax(predictions, axis = 1),
average = None
)
fig = px.bar(precision_scores,
x = classes,
y = precision_scores,
labels = dict(x = "Classes", y = "Precision"),
title = "Precision Scores")
fig.update_xaxes(tickangle = 45)
fig.show()- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
其结果应类似如下内容:

图5:精准率
而通过如下代码,则可以实现召回率:
Python
from sklearn.metrics import recall_score
recall_scores = recall_score(
np.argmax(np_utils.to_categorical(test_labels, num_classes), axis = 1),
np.argmax(predictions, axis = 1),
average = None
)
fig = px.bar(recall_scores,
x = classes,
y = recall_scores,
labels = dict(x = "Classes", y = "Recall"),
title = "Recall Scores")
fig.update_xaxes(tickangle = 45)
fig.show()- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
其结果应类似如下内容:

图6:召回率
为prediction_results准备Spark DataFrame
下面,我们将通过如下代码,创建一个列表,来匹配prediction_results表的结构:
Python
prediction_results = [
(i,
predictions[i].astype(float).tolist(),
int(test_labels[i]),
test_code
)
for i in range(len(test_labels))
]- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
我们可以通过如下代码,定义自己的模式,并创建Spark DataFrame:
Python
prediction_schema = StructType([
StructField("img_idx", IntegerType()),
StructField("prediction_results", ArrayType(FloatType())),
StructField("img_label", IntegerType()),
StructField("img_use", IntegerType())
])
prediction_results_df = spark.createDataFrame(prediction_results, prediction_schema)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
让我们通过显示几个数值,来检查DataFrame的结构:
Python
prediction_results_df.show(5)- 1.
- 2.
其结果应类似如下内容:
纯文本
+-------+--------------------+---------+-------+
|img_idx| prediction_results|img_label|img_use|
+-------+--------------------+---------+-------+
| 0|[1.4662313E-6, 3....| 9| 2|
| 1|[2.3188923E-5, 6....| 2| 2|
| 2|[1.30073765E-8, 1...| 1| 2|
| 3|[7.774254E-7, 0.9...| 1| 2|
| 4|[0.11555459, 2.09...| 6| 2|
+-------+--------------------+---------+-------+
only showing top 5 rows- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
接着,我们通过如下代码,将prediction_results根据十个穿戴类别,为列中的每个值创建一个单独的列:
Python
import pyspark.sql.functions as F
prediction_results_df = prediction_results_df.select(
["img_idx", "img_label", "img_use"] + [F.col("prediction_results")[i] for i in range(num_classes)]
)
col_names = ["img_idx", "img_label", "img_use"] + [classes[i] for i in range(num_classes)]
prediction_results_df = prediction_results_df.toDF(*col_names)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
将Spark DataFrames写入SingleStore DB
为了将DataFramestf_images_df和prediction_results_df分别写入表tf_images和prediction_results,我们首先需要建立与SingleStore DB的连接:
Shell
%run ./Setup- 1.
- 2.
在Setup中,我们需要确保已为SingleStore DB的云集群添加了服务器地址和密码。我们可以通过如下代码,为SingleStore Spark连接器设置一些参数:
Python
spark.conf.set("spark.datasource.singlestore.ddlEndpoint", cluster)
spark.conf.set("spark.datasource.singlestore.user", "admin")
spark.conf.set("spark.datasource.singlestore.password", password)
spark.conf.set("spark.datasource.singlestore.disablePushdown", "false")- 1.
- 2.
- 3.
- 4.
- 5.
最后,为了使用Spark连接器将DataFrame写入SingleStore DB。我们首先可以对tf_images使用如下代码:
Python
(tf_images_df.write
.format("singlestore")
.option("loadDataCompression", "LZ4")
.mode("ignore")
.save("ml.tf_images"))- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
然后对prediction_results使用如下代码:
Python
(prediction_results_df.write
.format("singlestore")
.option("loadDataCompression", "LZ4")
.mode("ignore")
.save("ml.prediction_results"))- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
查询示例
至此,我们已经构建出了系统。下面,我们将针对前文提到的两部分,来运行一些查询示例。
首先,让我们查询在tf_images中存储了多少张图片:
SQL
SELECT COUNT(*) AS count
FROM tf_images;- 1.
- 2.
- 3.
其结果应类似如下内容:
纯文本
+-----+
|count|
+-----+
|70000|
+-----+- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
让我们查看其中的几行:
SQL
SELECT *
FROM tf_images
LIMIT 5;- 1.
- 2.
- 3.
- 4.
其结果应类似如下内容:
纯文本
+-------+---------+-------+--------------------+
|img_idx|img_label|img_use| img_vector|
+-------+---------+-------+--------------------+
| 0| 9| 1|00000000000000000...|
| 1| 0| 1|00000000000000000...|
| 2| 0| 1|00000000000000000...|
| 3| 3| 1|00000000000000000...|
| 4| 0| 1|00000000000000000...|
+-------+---------+-------+--------------------+- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
我们再来查看img_use表:
SQL
SELECT use_name AS Image_Role, use_desc AS Description
FROM img_use;- 1.
- 2.
- 3.
其结果应类似如下内容:
纯文本
+----------+--------------------+
|Image_Role| Description|
+----------+--------------------+
| Training|The image is used...|
| Testing|The image is used...|
+----------+--------------------+- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
接着,我们来查找如下类别:
SQL
SELECT class_name AS Class_Name
FROM categories;- 1.
- 2.
- 3.
其结果应类似如下内容:
纯文本
+-----------+
| Class_Name|
+-----------+
|t_shirt_top|
| pullover|
| trouser|
| sneaker|
| sandal|
| shirt|
| bag|
| ankle_boot|
| dress|
| coat|
+-----------+- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
此外,我们还可以通过如下代码,找到不同类别的穿戴单品:
SQL
SELECT cn.class_name AS Class_Name,
iu.use_name AS Image_Use,
img_vector AS Vector_Representation
FROM tf_images AS ti
INNER JOIN categories AS cn ON ti.img_label = cn.class_idx
INNER JOIN img_use AS iu ON ti.img_use = iu.use_id
LIMIT 5;- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
其结果应类似如下内容:
纯文本
+-----------+---------+---------------------+
| Class_Name|Image_Use|Vector_Representation|
+-----------+---------+---------------------+
| ankle_boot| Training| 00000000000000000...|
|t_shirt_top| Training| 00000000000000000...|
|t_shirt_top| Training| 00000000000000000...|
| dress| Training| 00000000000000000...|
|t_shirt_top| Training| 00000000000000000...|
+-----------+---------+---------------------+- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
为了获得训练和测试图像数量的摘要,我们可以输入如下代码:
SQL
SELECT class_name AS Image_Label,
COUNT(CASE WHEN img_use = 1 THEN img_label END) AS Training_Images,
COUNT(CASE WHEN img_use = 2 THEN img_label END) AS Testing_Images
FROM tf_images
INNER JOIN categories ON class_idx = img_label
GROUP BY class_name;- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
其结果应类似如下内容:
纯文本
+-----------+---------------+--------------+
|Image_Label|Training_Images|Testing_Images|
+-----------+---------------+--------------+
| sandal| 6000| 1000|
|t_shirt_top| 6000| 1000|
| shirt| 6000| 1000|
| ankle_boot| 6000| 1000|
| dress| 6000| 1000|
| coat| 6000| 1000|
| trouser| 6000| 1000|
| pullover| 6000| 1000|
| bag| 6000| 1000|
| sneaker| 6000| 1000|
+-----------+---------------+--------------+- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
而为了获取有关特定图像ID的详细信息,我们可以输入:
SQL
SELECT img_idx, img_label, use_name, use_desc
FROM tf_images
INNER JOIN img_use ON use_id = img_use
WHERE use_name = 'Testing' AND img_idx = 0;- 1.
- 2.
- 3.
- 4.
- 5.
其结果应类似如下内容:
纯文本
+-------+---------+--------+--------------------+
|img_idx|img_label|use_name| use_desc|
+-------+---------+--------+--------------------+
| 0| 9| Testing|The image is used...|
+-------+---------+--------+--------------------+- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
Streamlit可视化
我们可以使用Streamlit创建一个小应用,以实现选择图像,并显示模型预测。
安装所需的软件
我们需要安装如下软件包:
纯文本
streamlit
matplotlib
plotly
numpy
pandas
pymysql- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
上述列表可以在GitHub上的requirements.txt文件中找到。您可以通过运行如下命令,来一次性进行安装:
Shell
pip install -r requirements.txt- 1.
- 2.
应用程序示例
以下是streamlit_app.py的完整代码清单:
Python
# streamlit_app.py
import streamlit as st
import array
import binascii
import matplotlib.pyplot as plt
import plotly.express as px
import numpy as np
import pandas as pd
import pymysql
# Initialize connection.
def init_connection():
return pymysql.connect(**st.secrets["singlestore"])
conn = init_connection()
def hex_to_vector(vector):
vector_unhex = binascii.unhexlify(vector)
vector_list = list(array.array("I", vector_unhex))
return vector_list
img_idx = st.slider("Image Index", 0, 9999, 0)
img_df = pd.read_sql("""
SELECT img_vector
FROM tf_images
INNER JOIN img_use ON use_id = img_use
WHERE use_name = 'Testing' AND img_idx = %s;
""", conn, params = ([str(img_idx)]))
vector_string = img_df["img_vector"][0]
img = np.array(hex_to_vector(vector_string)).reshape(28, 28)
fig = plt.figure(figsize = (1, 1))
plt.imshow(img, cmap = plt.cm.binary)
plt.axis("off")
st.pyplot(fig)
predictions_df = pd.read_sql("""
SELECT t_shirt_top, trouser, pullover, dress, coat, sandal, shirt, sneaker, bag, ankle_boot, class_name
FROM prediction_results
INNER JOIN categories ON img_label = class_idx
WHERE img_idx = %s;
""", conn, params = ([str(img_idx)]))
classes = [
"t_shirt_top",
"trouser",
"pullover",
"dress",
"coat",
"sandal",
"shirt",
"sneaker",
"bag",
"ankle_boot"
]
num_classes = len(classes)
max_val = predictions_df[classes].max(axis = 1)[0]
predicted = (predictions_df[classes] == max_val).idxmax(axis = 1)[0]
actual = predictions_df["class_name"][0]
st.write("Predicted: ", predicted)
st.write("Actual: ", actual)
if (predicted == actual):
st.write("Prediction Correct")
else:
st.write("Prediction Incorrect")
probabilities = [predictions_df[class_name][0] for class_name in classes]
bar = px.bar(probabilities,
x = classes,
y = probabilities,
color = probabilities,
labels = dict(x = "Classes", y = "Probability"),
title = "Prediction")
bar.update_xaxes(tickangle = 45)
bar.layout.coloraxis.colorbar.title = "Probability"
st.plotly_chart(bar)
st.table(predictions_df)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
创建一个密钥文件
我们的本地Streamlit应用程序可以从应用根目录中的.streamlit/secrets.toml文件中读取密钥。请参照如下方式创建该文件:
纯文本
# .streamlit/secrets.toml
[singlestore]
host = "<TO DO>"
port = 3306
database = "ml"
user = "admin"
password = "<TO DO>"- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
在真实创建集群时,上述代码中的<TO DO>应被替换为从SingleStore Cloud处获取的数值。
运行代码
我们可以按如下方式运行Streamlit应用程序:
Shell
streamlit run streamlit_app.py- 1.
- 2.
我们可以在浏览器中看到类似于下面图7和图8的输出。我们可以通过移动滑块来选择图像。它将向我们展示对该图像的各种预测。

图7:Streamlit(上半部分)

图8:Streamlit(下半部分)
在图7中,我们使用滑块来选择图像ID,我们选择了图像632。而在图8中,我们可以看到穿戴单品被预测为Shirt(衬衫),而实际上却是Pullover(套头衫)。如您所见,图7中的图片看起来太大太粗糙,因此您可以按需改进对灰度图像的渲染。
小结
在本文中,我们讨论了SingleStore DB如何与Keras和Tensorflow一起协同工作。在SingleStore DB中,我们既可以存储测试和训练数据,又能够预测各种模型。最后,我们通过一个Streamlit应用展示了如何查看对于图像的预测。
译者介绍
陈峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。
原文标题:Image Classification Using SingleStore DB, Keras, and Tensorflow,作者:Akmal Chaudhri