01 京东零售流量数仓架构
1. 京东零售——流量简介
① 什么是流量?
简单来说,流量就是用户作用在京东页面上,产生一系列行为数据的集合。
② 流量数据的来源
数据来源主要是移动端和PC端,以及线下店、外部采买、合作商的数据等。

这些数据是如何流转到数仓的呢?
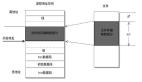
2. 京东零售——流量数据处理架构
由架构图可以看出,对不同的终端采取不同的采集模式;例如,对APP原生页面采取SDK的采集模式,对于PC、H5页面是JS采集,数据采集后按照实时和离线双写,离线直接写到CFS分布式文件系统中,每小时从CFS拉取数据文件,同时对数据文件大小、采集ip进行监控,防止数据丢失;实时是以白名单的方式动态配置,写到kafka中,最后将数据入仓。

3. 京东零售——流量数仓分层介绍

数据流转到数仓会进行一些统一化的管理,数仓是如何分层的呢?
受京东业务复杂度和数据体量的影响,整体分层较细,分为:数据缓冲层(BDM)、贴源数据层(FDM)、基础数据层(GDM)、公共数据层(ADM)、应用数据层(APP)五层。
① BDM层
是源业务系统的一些数据,会进行永久性保存。
② FDM层
主要是从报文日志转化成业务格式,对业务字段进行拆解、排序和数据回写等,例如用户逛京东时前期未登录,最终下单时才登陆,那对用户全链路回写便是在这一层进行。
③ GDM层
按照主题域进行标准化封装,整体会屏蔽生产系统干扰,同时会处理数据回灌事情。
④ ADM层
ADM是公共数据层,面向主题、面向业务过程的数据整合,目前划分成两层:ADM-D、ADM-S。
ADM-D负责统一的数据口径封装,提供各主题统一维度和指标的最细粒度数据;
ADM-S提供各主题统一维度和指标的聚合数据, 为各业务方提供统一口径的共享数据。
⑤ APP层
数据看板的数据整合,也可以进行一些跨主题的聚合数据处理。
⑥ 维度层
DIM层主要就是一些通用的维度数据。
基于以上的数仓分层方案,来看下京东流量数仓架构在离线和实时上别分是如何处理的。
4. 京东零售-流量离线数仓架构

① 基础数据层
离线数仓最下面一部分是基础数据,主要面向实体模型建设,按照数据渠道和不同类型做数据整合,例如渠道:app、pc、m等;日志类型:浏览、点击、曝光等。
② 公共数据层
这一层也是大家应用比较广泛的一层,上面也提到了adm面向业务过程的模型建设,这层也是分成了明细和汇总两层。在明细层,我们会把所有的业务口径沉淀到adm明细中,封装各种业务标识,保障数据口径统一管理,避免口径二义性,同时,为数据可视化管理,提供源数据依赖。
③ 应用数据层
应用层主要是面向数据看板的建设,提供预计算和OLAP两种方式服务模式,这一层整体上会很薄,重点解决数据引擎查询效率问题,高频访问的维度提供预计算、低频应用的数据由OLAP方式提供数据服务。
④ 数据服务层
面向多维数据分析场景,进行指标和维度的统一管理,以及服务接口的可视化管理,对外提供统一的数据服务。
5. 京东零售——流量实时数仓架构
实时数仓与离线数仓的建设理念是基本一致的。
RDDM是分渠道、分站点、分日志类型的实时数据流,构建过程中主要考虑解耦,如果只消费部分数据,依然需要全量读取,对带宽、i/o都是一种浪费。同时,也方便下游按照业务实际情况进行数据融合。
RADM面向业务场景,在RDDM的基础上进行整体封装整合,例如商详、来源去向、路径树等业务场景。
在整体封装后,数据会接入到指标市场,按照统一的接口协议和元数据管理规范进行录入,对外提供统一的数据服务。
以上主要介绍了京东流量场景的数据处理架构,接下来我们结合一个京东实际案例,讲述京东特殊场景下的数据处理方案。

02 京东零售场景的数据处理
1. 京东零售——流量挑战
首先是数据爆炸式的增长。2015年至今,整体的数据量翻了约十几倍,但资源情况并没有相应成比例的增长。其次,业务的复杂度升高,包括新增了小程序、开普勒、线下店的一些数据以及并购的企业的数据等,因此整体的数据格式以及完备度上还是存在较大差异的。再次,随着业务发展,流量精细化运营的场景增多,但数据服务的时效并没有较大变化,需要我们在有限时间内处理一些更多更大体量的数据,以满足更多场景化应用。特别是京东刷岗这样的场景,对数据的范围、需要处理的数据量,以及数据时效都是一个比较大的挑战。

2. 海量数据更新实践——刷岗
什么是刷岗?将发生在该SKU的历史事实数据,按照最新的SKU对应运营人员、岗位、部门等维度信息,进行历史数据回刷。

刷岗在京东也经历了多个阶段,从最初数据量较小,采取全量刷岗的模式,后续逐渐升级成增量的刷岗。后续采取OLAP的刷岗模式,也就是将数据写到CK中,通过Local join进行关联查询。目前我们通过iceberg+olap的方式来实现数据刷岗。
首先构建iceberg表;其次、对流量商品表的更新处理,将所有会发生变化的字段拼接做MD5的转化,后续每天做这种差异化的判断,如果有变化就做upsert操作;最后,生成的流量商品表与事实表进行merge into,进而得到刷岗更新后的数据;同时在此数据基础上,针对不同应用频率的数据,采取了预计算和OLAP两种数据服务模式。
通过数据湖的方式来实现数据更新,相比于hive存储格式,支持多版本并发控制,同时支持ACID事务语义,保障他的一致性,数据在同一个批次内提交,要么全对,要么全错,不会更新一部分。另外,支持增量数据导入和更新删除能力,支持upsert操作,整天数据处理的复杂度要降低很多,同时在资源的消耗和性能以及数据处理范围上较hive端模式都有了极大的提升。
基于数据湖的模式进行刷岗目前还面临数据倾斜的问题需要解决。

3. 数据倾斜治理方案

① 数据倾斜的原因及处理方式
数据倾斜出现的一个主要原因是数据分布不均,出现热点key。对于数据倾斜的处理方案,比较常见的有:优化参数,如增加reduce的个数、过滤一些异常值、赋随机值,或者按经验值设置固定阈值,把大于某阈值的数据单独处理。赋随机数的处理方式,当任务执行过程中,某个节点异常,切换新节点重新执行,随机数据会发生变化,导致数据异常。通过这种经验值设定阈值的一个弊端是,在不同的场景下,不容易界定阈值大小,包括对于热点key的识别,通常也只能事后发现处理。

② 数据倾斜的解决方案
基于此,我们在探索的过程中建立了一套智能监测倾斜的任务。
首先,利用实时的数据,提前对数据进行监测,针对数据分布特点,通过3倍标准差确定离群点,离群点即倾斜阈值。
其次,根据倾斜阈值计算分桶数量。
最后,按照对列资源在不同时段的健康度进行作业编排。
③ 如何寻找热点key及倾斜阈值
热key寻找的核心思想,就是根据数据的分布特点,通过3倍标准差确定离群点,离群点即倾斜阈值,如下图所示,整体的数据是呈右偏分布,我们通过两次3倍标准差得到最后的倾斜阈值X2。
第二步计算分桶的数量,根据整体的数据分布情况看,第一阶段的拒绝域面积与第二阶段的拒绝域面积相等。根据积分原理,频率绝对数与频次绝对数呈反比,因概率密度分布曲线未知,所以用两次离群点的频次均值比例,代表两次抽样数据量比例,进而得到分桶数。

④ 数据分桶作业
最后是作业编排,一次性起多个任务会出现资源获取不到,一直处于等待状态,同时对其他的任务也会产生较大影响,并发少了又会带来资源浪费,针对这类问题,我按照对列资源的健康度,对执行的任务做了编排,由整体串联执行和固化并发,调整为按资源健康度动态扩展,实现资源利用最大化。

03 数据处理架构未来探索
未来探索方向
首先,目前我们基于Flink+Spark的方式来做流批一体的探索。图中可以看到传统的Lambda数据架构有一个很大的特点:实时和离线是两套不同的数据链路。整体的数据处理过程中,研发的运维成本相对较高,而且两条不同的数据链路,会容易导致数据口径上的差异。
后续通过FlinkSQL+数据湖存储实现同一套代码两种计算模式,同时保证计算口径一致性。同时也会有一些挑战,开发模式的改变,CDC(change data capture)延迟目前是分钟级延迟,如果调整为秒级,频繁提交,会生成很多小版本,对数据湖的吞吐量造成影响,总体来说,在部分应用场景下存在一定局限性,但分钟级延迟可以满足大多数的实时应用场景,对于研发成本和效率都会有较大提升,当然,目前也在不断的完成和探索。总体来说,目前在一些特殊场景下具有一定的局限性。

04 问答环节
Q:分桶的应用效果?
A:总结成几个点就是:
- 从事后处理转变为事前监测。
- 不同周期、不同场景下动态计算倾斜阈值和分桶数量。
- 根据对列资源健康度动态扩展任务并发数量,实现资源利用最大化。
Q:Spark的应用在京东场景里最小的延迟是多少?
A:目前主要是基于小站点数据去做探索,数据处理量级比较小,目前延迟大概在分钟级左右,如提交的频率增大,对于io的性能会是一个很大的考验。
Q:Spark应该是不支持行级别的upsert,京东这边是怎么去解决这个问题的问题,分区和小文件的合并有哪些相关的经验分享?
A:目前的版本可以支持行级更新,关于分区这部分主要还是结合业务特性,在设计分区时,尽量让变化的数据都集中到少部分文件上,降低文件更新范围。
今天的分享就到这里,谢谢大家。